Gene
KWMTBOMO05963
Pre Gene Modal
BGIBMGA002901
Annotation
PREDICTED:_uncharacterized_protein_LOC106708887_[Papilio_machaon]
Location in the cell
Nuclear Reliability : 1.461 PlasmaMembrane Reliability : 1.518
Sequence
CDS
ATGTCGGTGTCCTACATTCGCGGGAAGGTGACTAGTGAGCTCCGATGGTTCGCATCAGCTCATGCTTTGGTTGACAGAACGGATAGGGATGCGGCATTGCTCGATAGGGCGTCTCAGGTGCACGAACGGTTGGAGGTAGTGTACGATCGGTTGTCTGACCTCGTTGCTTTGGGGTCCGAAGTGGAGAAGGAGGTGATCCATGCCATCGGTCTTGACGTGGACCAGTGTCAGGAGTACGCTGATGCCATTCTGCAACGGGTGGCCGATATTAAGAAGCAGTCGCCTTCCGGTGGTAATGGAGGTTCGGGAACTTCGCTAGGCGTCATATCACGCCTCCCTTCCATCGACCTGCCGATCTTCCACGGTGATCTGAACGAGTGGGTCGGCTTTATAAATTTGTTTGACAGCCTGGTCCATGGTCGGTCGGACTTGACTGCCTCGTATAAGATGGCTCAGCTTCGGGGTGCTCTGCGAGGTGAACCTGGTGAATTGGTGGCACACTTGCCTATCACCAACGACAATTATGCGGTCGCACGCCAGATCCTGTTCGACCGATATCAAAATCAACGACGGTTGGTGGACGTTCAGCTGGCCAGGCTGTTTGCGATACCCAAACTTTCTCGGGCTTCCGATATCAGAGCCGAGGTACTGAATCCAGTTACGGTGGCCACTAAGGCCTTGGGCAATTTGGGTCTACCAGTAGACCAATGGTCATATCTGCTCTTTTATATTGTTGCAGGTAGGCTGCCGGTTGAGGTGCTCACTCGATTCGAGCAGCAGGACAACGCAGGTAGGGACGAACTGCCTACCCTGGCCAGTCTGCTGGCGTTTTTAGAAGCCGAAAGTCGCCGACACGAGATTATGCCACCACCCTCCTCCTCTGGGTCGCGTGTGCCGGCTTCCGGCCACGCCGTTTCGGTTGCTCAGAGGGGAGGGGGAGGGGATAAGAGGGGGCCGTCTCAACGACTGACTGCGCTCATGGCAGCGGTGGGAGGCCCACGGTGTGCCTTCTGTCATGAGAGCGGGCACGACGTAGCCGCCTGTCCGAGGTTCCGGTCGACGCGCATCAGGGGTAGACGCAACATCGTTGCCCAGCGGCGATGGTGCTTTTTTTGTTTTGGGCCGCACACGGCGAGCGTCTGTCCACAGCCACAATTGTGCCCTAATTGCGACGGTCGGCACCATGCCCTCCTGTGTCTGGAGTCTGCCGCCACTCCGAGGTCATCCGGACGCAGTCATCCAGCCTCGCCGACCGGTGAGCGCACCGGTCGTAGCCCTCGCCAATTCGGCGGCGTGGACCCTCGGAAAGAGGCTTCGCAGGGAGGCGCCGGGTTAGGTACTGCGGGCGGGTGCCAGCGGATGCCCACCAGCTACGCCGGGGTGGCCACGTTGTCCCCCCGTGCGGGGCCGTGTTCGCCTGCTGGATCGAGTAGCCCTGCTCACTCGTCTCCCCCTCCCTCAGAAGTATGGTTTTCTCCTCCGCTGAGGGAGCGGCCGACGCTGGAGCGACTCCCTCCAGTGTTTGGCCCGTTTGGCCATCGTACGCGGAGTGTTGCCCCAGCCCCAGAAGCTGTTTTACTTCCTACCGCTTCTGTTCGGGTGTTGGATTCGGATGGCAACACTGTGTTTGCTCGAGCTCTGTTGGATTCCGGCGCACAGGGCAGTATTATGTCGAGCAACCTTGCAGTACGGTTGGGCAATCCTATTTACAAGTCTTCTTATTCTATTCGTGGAGTGGGCAATGTTAGAATTTCGGACGTGATCGGTCACACTTCATTTATTTTCTCATCGAATCCCAACCCTCGCTTACAGTTTAGAGTCTCAGCTTTGGTGATGCCTGAGGTGATAGGTCGTCACCCTCCGGTGAAGGTAAACAGTTACATACGGTCATTGACTTCAGACTTACGGCTAGCGGACCCCAAGTTTGACACACCGGGGCCAGTAGACGTACTACTTGGGGCGGATGTACTAGGGAAGCTGCTCCTGACTGGGAAGCGCGTTCTTCATGCGGAGGGTTTGGTTGCAATGGACACAAAATTAGGGCATGTATTGTTGGGTCCTGCGTTCCGGCCGGTCGCTGCGAGGAAATCGGACAATTTTCTGGTCGGGTCTACGCTTTCGGAAGTAGTCCAACGGTTTTGGGAACTAGAAGAACCTCCTACAGCTTATCGAGTTAACCCGGATGAGGAGGAATGTGAGCTGTTTTACCAGAATAATACGGGTCGTCTCTATTCGGGCCGGTTCTTGTTAAGACTTCCTTTTCGGGCGAATCGCCCACTGCTAGGCAGTTCGAGGAAGGCAGCAGAGACTAGACTTTTGTCAATGGAGAGACGCATGAGGCGCGACGCGGTGTTCCGGCAGAAATATGTAGAGTTTATGCGGGAGTATGAATCTTTAGGTCACATGTCGGTTTCCAAGGTAGATTGGAGTGCTACGGAGCACTGTTTCCTGCCTCATCATGCGGTTTTGAAAACTCCTAACGGTAAAATTAGGGTCGTGTTTGACGGTTCGGTCACGACCTCCTCCGGCGTCTCGTTAAATCAGTGTCTCCATTCGGGTCCAAAGCTGAACCGGGACATTTCAGACATACTGACGAGCTTCCGCAGGCACCAGATCGTTTTCGTGGCAGACATCCGTATGATGTTCAGGCAAACGGTGATTCATCCGGAGGATAGGCGGTATCAACTCATTCTCTGGCGTGAAAGCTCAGATGAGCCCATAAAAATTTATGAACTGAACACGAACACTTACGGGTTGCGGTCGAGTCCATATTTGGCGGTTCGTTCTTTGCGGGAGCTGGCAGTGAGGGAACGGTTGCACTACCCTCGTGCTGCGGACATTTTGGAACGGGACCTATATGTCGATGACGTATGTACGGGCGCCGACAGTGTCGAAGAGGCCTTATCACGCAAGGATGAACTGATCCGCCTTTTGAGCAGGGGCGGGTACGAGTTGAGAAAATGGCTGTCTAACTGTCCTGAGTTGTTGACTGGTTTGCCAACGAAGTTTCAACAGGATCCCCATCTTTTCGAGAATGTCGATAACCCTAACATGCTGTCGGTCCTAGGGATTCAATATCGTCCGATTCAAGACGAATTTACCTATCGGGTGGAGTTGGAAAATCCAAAGGTATGGTCTAAGCGAACGGTGCTTTCCACAATTGCTCGAACCTTCGATCCAAACGGTTGGATCGCTCCTGTCACTTTTCTCTTAAAGTGCTTCATGCAGCGACTGTGGTCTGCTAACCTGTCATGGGACGAGGGGATTGCTGGTGACCTATTGAAGGATTGGTTGAACTTTTTCTCGTCTCTTCCTGATATTAACCACGTGTCAATACCTCGGAAGCTGGTTCCTGCGGGCAAATACAAGGCGTCTCTCCACGGGTTTTCGGATGCCTCGGAACGTGGATTCGCAGCTGCGGTATACTTGCGAACGGTTTCTTCAACTGGAAGGGTTGATATACGGTTGGTGTTAGCGAAGAGTAAGGTCGCTCCGCTTCGGACACGCATGACGATTCCGAAGCTCGAGTTGTCTGGTGCCGCTCTGTTGACTAGGTTGTTAAACCATACAGCTACTAGTTTACGGTCGGTTATTGATTTAGAAAACACTGTCTATGCTTGGACAGACAGCCAGATAGTGTTATGCTGGTTGAAGGCTTCGGTTCATACACTTGAAGTTTTCGTGGCCAACCGTGTCTCCCAGATTCAAGGATCTGAGGTCCCTCTAACATGGAGACACGTGCCTGGTGAGCTCAATCCGGCGGACTGCGCTTCTCGGGGATGCTTAGCATCGGAAATGGTTGATCATCAGTTATGGTGGGGTCCCCAGTGGCTCACAATGAAGGCTTCTCAGTGGCCACCCTCTCGCATAGGAGTTCCTCCAGGTCTCGTGGCTGCACCGGCGCAGTTCCAGGATCGAGGAGTGATTCAGGGGTTGGATTTGGATCTGCTCATCAACCGTTATAGCTCCTTGGACAAGCTGGTTAAGGTTACCGCCTGGATTTTGAGGTTTATTCGGAATTGTCGTTTGTCGGTGTCTCAACGCAATATGACACCTGTTGTGTGTCCCATCGAGCGGAAGAAGGCACTGCTGAAATTAATTGAAGTTGTGCAAGCCACCAGCTTTCATTCAGAATTGAAGGCGCTAAGGACTGAGCGCCCTAAGCTTCGTGGAGCTATCGCTCGTCTTAGCCCCTTTGTAGACGGCCAGGGGTTGATTCGAGTGGGAGGTAGATTAAGTAACTCCAATTTACCTTATTCGGCGCGCCATCCTCTTTTACTTCCTAAGAAGAGCCAGTTAGTTGACCTGTTGGTGATGGATCGCCACATCGCAAATTCGCATTCCGGTTGCAATGCGCTGCTGGCATCCCTCCAGAGGGAATTTTGGATTCTGTCAGGGCGTCGTACGGTTCGGAGCGTCCTTTTCCGGTGTTTACCCTGTTATCGGCTTAAGGCGTCTACGATGCAGCCTCAGATGGGAGATCTGCCTCCAGACAGAGTGAAGAAGATGAGGCCGTTTTCTGGAGTTGGTACGGACTTCGCTGGGCCCTTCATGATCAAGGCTTCACGTTTGCGGAATGTTAGGTTAATTAAGGCTTATCTGTGCGTCTTTGTCTGTCTTTCAACCAAAGCTGTACATCTTGAAGTTGTTGCCGACCTTACAACTGAAGCCTTTATTGCGAGCTTGGATAGATTTGTGTCCCGTCGAGGTTTACCCGAATTGATACGCTCCGATAACGGAACGAATTTTGTAGGTGCGGACCGTTACTTGCGGGATGTAGTAAATTTCTTGAACAATAACCAGGTGGATATTGAAACGGCCCTCTCTCGTCGCGGTATTCGGTGGACCTTCAGTCCTCCAGGATGCCCCCACTGGGGTGGAATTTTCGAGGCAGTAGTAAAATCGGCTAAGACTCACTTGATGCGCGTGATAGGGCAAACCTCGCTCACCTTTGAGGAGTTAACCACGGTATTTTGTAAAATTGAAGCGGTACTTAATTCGCGGCCGTTGTGCCCGCTCAGTTCAGACCCGAATGACTTGGAGTCGTTAACTCCAGGCCATTTCTTGATAGGACAGCCACTCAATGCGTTGCCGGAGTATCCCCTCTCGGATATCAAGCCTGGACGGTTGAGGCGATACCAGATGTTGCAGCAGATGTCCCAAGATTTTTGGAAACGTTGGTCCCTTGAGTATTTACATCTGCTCCAGCAGCGCTTTAAGTGGACGGATAAAACCAGTCCCCCTCACGTCGGTGACCTTGTGTTGGTTAAGGATGCTAACCTGCCGCCACTGCGTTGGCGTAGGGGGCGCATTGTTAATCTGTTTCCCGTTCATGCATGCACGCCTCATACTCTTCGTCTTCTGATGAGAGGTTCTTCAGCACCGCATCCATCAACAGCGGGAGTCTCGTCACTCGCTGTATCGGTAGCATCAGGAACGAGTGGAGGGATAGACTCTGGCAAGCCGGGTGACTCTCTAGCCTGTGACCGAGTGATAAATATAGCTTTCTCTCGATCTGCGCACATTGCAAGTATGCTGCGATTGGTTGCTCTGTTAGGCTTGTTGTCGGCGGTGGCTGCCCGGTTGAGGGTAGACCCCCTTGTTGATACTCAGCGGGGACTCATCAGGGGACTGAGGTCCGAAAATGGAAAGTTCGCGAAGTTTTTGGGCATACCGTACGCACTAGTTGATGAGAACAATCCTTTCGGGCCATCAGTACCACACCCTGGTTTCGAAGAGACATTCGAAGCATACGATGATTCCGTAGTTTGTCCTCAAGTTACTAAGGGCGTCGGAGTTGGTAGTCTTCAGTGTTTGAACCTGAACGTTTATGTCCCAAACACGGCTACATCGCGCAACAAGCGCCCCGTGATGATTTGGATCCACGGAGGAGGCTTCGCCACCGGCAGTGGGACAGGCAGGGACTTCTCCTACGACGACCTGGTCCGACATGACGTCATCGTCGTATCGGTCAACTACCGACTCGGACCCTACGGGTTCTTATGCTTGGACAGTCCTGATATTCCCGGGAACCAGGGTTTGAAGGATCAAGCTCTTGCTCTCAGATGGATTAAGGAAAATATCGAAGCGTTCGGCGGAGATGTCTCTAAAATAACCTTGTTCGGAGAGAGTGCTGGTGGCGTCGCTGTCGAGCTACACCTACTGACCGACCAGGATAAACTGTTCAATCAGGTGATCATCCAGAGTGCATCTGCTTTCTTTGCTGGGGGTATTAGGAAACCTAGCAACCGTGTTCCAATAGAAATAGCAAGCCAGCTGGGATTCGAAACTGACAACTTCGTAGAGGCGGTAAAGTTTCTGGCCGGTCAAGACCCCCACCTGGTGGTCGCAGCCAGCACTTCTCAAAGCTCTGCCATAAGAGGCGGTACTCTTAGACCTTGCCGAGAGAACAAATACGACGGAGTTGGCAATTTTCTTTCGGATTTTCCTGAAAATTTAAGGGCTAGAAACATTCCTGCTATTTATGGAGTAACCAATAAAGAATTTCTAACATTACATGCTTATGTGACCCCAGAAGATTACGAGGTGACAGGATTTCGAACTTTTCTGGAACGGGCTTTCAACTTGACCGATAGCGAGATGGAAGACCACGTGAGACATTTCTACATCGGAGACGAGACGCTGACCGAGAAGCAGTTTGATGAGTTTATAGATTTTGCGTCGGACTATTACTTTAACTACGCCGTCCAGCGGTCTATTAAGAAGTCATTGGCAGACGGTAACAAGGAGGTATATTACTACGTGTTCTCGTACGACGGAGGCAGGAATGCCATGAAGCAGTACCTCGGCATAACGGCGGAGGGCGCTGCGCACGCGGACGAGCTCGGCTACCTGCTGGCCGTGGATTTGGTCCCGGGACAACACATCGCCGAGGAGGACCAACTGATCATCGACAGGATCACTACTCTTTGGGCAAATTTTGCTAAATACAGCAACCCCACCCCTGAGCCGACGGACCTGCTGCCGGTCGTGTGGACGACAGTAGAAGGTAACAAGCGGCCGTATCTGGACATCGACACCGACCTGCAGCTCAGAAGCAGGCCCTTCCACCACCGGATGGCCTTCTGGGATCTCTTCTATAAGCTCTATGGAGAATTGGAGCGCAGGAACTAG
Protein
MSVSYIRGKVTSELRWFASAHALVDRTDRDAALLDRASQVHERLEVVYDRLSDLVALGSEVEKEVIHAIGLDVDQCQEYADAILQRVADIKKQSPSGGNGGSGTSLGVISRLPSIDLPIFHGDLNEWVGFINLFDSLVHGRSDLTASYKMAQLRGALRGEPGELVAHLPITNDNYAVARQILFDRYQNQRRLVDVQLARLFAIPKLSRASDIRAEVLNPVTVATKALGNLGLPVDQWSYLLFYIVAGRLPVEVLTRFEQQDNAGRDELPTLASLLAFLEAESRRHEIMPPPSSSGSRVPASGHAVSVAQRGGGGDKRGPSQRLTALMAAVGGPRCAFCHESGHDVAACPRFRSTRIRGRRNIVAQRRWCFFCFGPHTASVCPQPQLCPNCDGRHHALLCLESAATPRSSGRSHPASPTGERTGRSPRQFGGVDPRKEASQGGAGLGTAGGCQRMPTSYAGVATLSPRAGPCSPAGSSSPAHSSPPPSEVWFSPPLRERPTLERLPPVFGPFGHRTRSVAPAPEAVLLPTASVRVLDSDGNTVFARALLDSGAQGSIMSSNLAVRLGNPIYKSSYSIRGVGNVRISDVIGHTSFIFSSNPNPRLQFRVSALVMPEVIGRHPPVKVNSYIRSLTSDLRLADPKFDTPGPVDVLLGADVLGKLLLTGKRVLHAEGLVAMDTKLGHVLLGPAFRPVAARKSDNFLVGSTLSEVVQRFWELEEPPTAYRVNPDEEECELFYQNNTGRLYSGRFLLRLPFRANRPLLGSSRKAAETRLLSMERRMRRDAVFRQKYVEFMREYESLGHMSVSKVDWSATEHCFLPHHAVLKTPNGKIRVVFDGSVTTSSGVSLNQCLHSGPKLNRDISDILTSFRRHQIVFVADIRMMFRQTVIHPEDRRYQLILWRESSDEPIKIYELNTNTYGLRSSPYLAVRSLRELAVRERLHYPRAADILERDLYVDDVCTGADSVEEALSRKDELIRLLSRGGYELRKWLSNCPELLTGLPTKFQQDPHLFENVDNPNMLSVLGIQYRPIQDEFTYRVELENPKVWSKRTVLSTIARTFDPNGWIAPVTFLLKCFMQRLWSANLSWDEGIAGDLLKDWLNFFSSLPDINHVSIPRKLVPAGKYKASLHGFSDASERGFAAAVYLRTVSSTGRVDIRLVLAKSKVAPLRTRMTIPKLELSGAALLTRLLNHTATSLRSVIDLENTVYAWTDSQIVLCWLKASVHTLEVFVANRVSQIQGSEVPLTWRHVPGELNPADCASRGCLASEMVDHQLWWGPQWLTMKASQWPPSRIGVPPGLVAAPAQFQDRGVIQGLDLDLLINRYSSLDKLVKVTAWILRFIRNCRLSVSQRNMTPVVCPIERKKALLKLIEVVQATSFHSELKALRTERPKLRGAIARLSPFVDGQGLIRVGGRLSNSNLPYSARHPLLLPKKSQLVDLLVMDRHIANSHSGCNALLASLQREFWILSGRRTVRSVLFRCLPCYRLKASTMQPQMGDLPPDRVKKMRPFSGVGTDFAGPFMIKASRLRNVRLIKAYLCVFVCLSTKAVHLEVVADLTTEAFIASLDRFVSRRGLPELIRSDNGTNFVGADRYLRDVVNFLNNNQVDIETALSRRGIRWTFSPPGCPHWGGIFEAVVKSAKTHLMRVIGQTSLTFEELTTVFCKIEAVLNSRPLCPLSSDPNDLESLTPGHFLIGQPLNALPEYPLSDIKPGRLRRYQMLQQMSQDFWKRWSLEYLHLLQQRFKWTDKTSPPHVGDLVLVKDANLPPLRWRRGRIVNLFPVHACTPHTLRLLMRGSSAPHPSTAGVSSLAVSVASGTSGGIDSGKPGDSLACDRVINIAFSRSAHIASMLRLVALLGLLSAVAARLRVDPLVDTQRGLIRGLRSENGKFAKFLGIPYALVDENNPFGPSVPHPGFEETFEAYDDSVVCPQVTKGVGVGSLQCLNLNVYVPNTATSRNKRPVMIWIHGGGFATGSGTGRDFSYDDLVRHDVIVVSVNYRLGPYGFLCLDSPDIPGNQGLKDQALALRWIKENIEAFGGDVSKITLFGESAGGVAVELHLLTDQDKLFNQVIIQSASAFFAGGIRKPSNRVPIEIASQLGFETDNFVEAVKFLAGQDPHLVVAASTSQSSAIRGGTLRPCRENKYDGVGNFLSDFPENLRARNIPAIYGVTNKEFLTLHAYVTPEDYEVTGFRTFLERAFNLTDSEMEDHVRHFYIGDETLTEKQFDEFIDFASDYYFNYAVQRSIKKSLADGNKEVYYYVFSYDGGRNAMKQYLGITAEGAAHADELGYLLAVDLVPGQHIAEEDQLIIDRITTLWANFAKYSNPTPEPTDLLPVVWTTVEGNKRPYLDIDTDLQLRSRPFHHRMAFWDLFYKLYGELERRN
Summary
Uniprot
EMBL
Proteomes
Pfam
Interpro
IPR008737
Peptidase_asp_put
+ More
IPR021109 Peptidase_aspartic_dom_sf
IPR040676 DUF5641
IPR000477 RT_dom
IPR005312 DUF1759
IPR041373 RT_RNaseH
IPR036397 RNaseH_sf
IPR041588 Integrase_H2C2
IPR001969 Aspartic_peptidase_AS
IPR041577 RT_RNaseH_2
IPR001584 Integrase_cat-core
IPR012337 RNaseH-like_sf
IPR008042 Retrotrans_Pao
IPR021109 Peptidase_aspartic_dom_sf
IPR040676 DUF5641
IPR000477 RT_dom
IPR005312 DUF1759
IPR041373 RT_RNaseH
IPR036397 RNaseH_sf
IPR041588 Integrase_H2C2
IPR001969 Aspartic_peptidase_AS
IPR041577 RT_RNaseH_2
IPR001584 Integrase_cat-core
IPR012337 RNaseH-like_sf
IPR008042 Retrotrans_Pao
Gene 3D
ProteinModelPortal
PDB
6EMI
E-value=3.27101e-42,
Score=439
Ontologies
GO
Topology
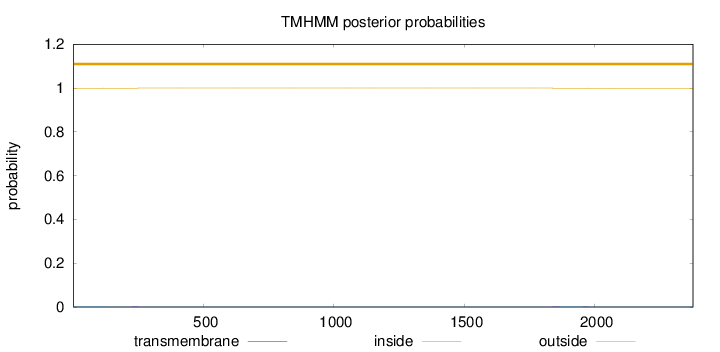
Length:
2377
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.0464100000000001
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00065
outside
1 - 2377
Population Genetic Test Statistics
Pi
253.070868
Theta
185.061433
Tajima's D
1.413948
CLR
128.942199
CSRT
0.76111194440278
Interpretation
Uncertain
