Gene
KWMTBOMO05859
Pre Gene Modal
BGIBMGA006967
Annotation
PREDICTED:_transcription_initiation_factor_TFIID_subunit_2_[Papilio_xuthus]
Full name
Transcription initiation factor TFIID subunit 2
Alternative Name
Transcription initiation factor TFIID 150 kDa subunit
Location in the cell
Nuclear Reliability : 3.559
Sequence
CDS
ATGAAAAAAGAACGTACGGGCGACAATTGTCGCCCATTTAAATTAGCTCATCAAATTTTGAGTTTAACGGGAATAAGCTTTGAAAGAAGAAGCGTTATTGGATTTGTGGAACTTACTGTCGTTCCCCTTAAGGATAACTTACGCTACATTCGTCTAAATGCGAAGCAATCTCGAATATATAGAGTGTGCTTAAATGATCAATATGAAGCAAATTTTCAGTACTTTGACCCATTTCTGGATATATGTCAAGCCGATCCAAATACGAGATCACTGGAAGCATTCTCTCAGTATCATTTAACTGCAGCACAGAAGACAGACCCTGACCATAACTCAGGAGAACTTCACATTCAAATACCTGAAGAAGCAGCTCACTTAGTTGGTGAAGGCCGAGGGCTCAGAATTGGTATTGAATTTTCACTTGAATCTCCCCAAGGGGGCATGCATTTTGTTGTACCTGAGGGAGAAGGTACTTTGACAGAGAAATCAGCGCACATGTTTACATATGGACATTCTGCTCGACTATGGTTCCCATGTGTGGATAGTTTTGCTGAGCCTTGCACTTGGAAACTGGAATTCACTGTTGATGAATGCCTCACAGCTGTTTCATGTGGAGAACTAGTAGATGTTATTTATACACCTGATCATAGGAGGAAAACATTTCATTATTTAGTGAATACTCCAGCTTGCGCACCAAACATAGCATTGGCTATTGGACCATTTGAAACTTATGTTGATCCTTTCATGAATGAAGTAACACATTATTGCTTACCAAATTTGCTACAAATATTAAAGAACACCGTAAGATATTTGCATGAGGCATTTGAATTCTATGAAGAAACATTATCAACTCGATATCCATATCCCTGTTACAAACAAGTTTTTGTTGATGAGACAGAAGATGACGCAACTGCTTACACAACTATTTCGATATTAAGCACTCACCTGCTACACTCGATTGCTATCATCGACCAGACTTACATCAGCAGGAAGGCAATGGCACAAGCAGTGGCCGAGCAGTTTTTCGGTTGTTTTATAACTATGCAGAACTGGTCAGATCTGTGGCTAGCAAAAGGTATACCGGACTATTTATGCGGACTGTACTCCAAGAAATGTTTCGGGAACAACGCCTATCGGTATTGGATACATCAGGAGTTGAAAGAGGTGATGGGTTACGAAGAACAATATGGCGGTATAGTCTTAGACCCGTGGCAGCCGCCCGCTAGTGGAACCAGGATTGAACCCAATGTCTTCTATTTCCCCGTACGCAATGTTCATACCATGTCGCCGCGGTATATTGAAGTTATGCGCAAAAAATCCCATTTGGTACTACGAATGTTGGAGCAGCGTATTGGACAAGAGCTCCTGCTTCAAGTATTTAACAAGCAGTTGGCGTTGGCCACCAATGCGGCCAATACAAAGATCGGGAGTGGGCTATGGGGCCACTTGTTGCTATCGACCAACTTGTTTGTCAAAGCTATATTCACGGTGACTGGTAAAGATATGGCTGTGTTCGTCGACCAGTGGGTGAGGACCGGAGGGCACGCCAAATTTCAATTGACATCAGTCTTTAATAGAAAAAGGAACACCGTAGAACTTGAGATACGACAGGACTGCGTGCACGAGCGCGGTATACGTAAATACGTGGGTCCCCTGCTCGTCCAGTTGCAAGAGTTGGACGGTACATTCAAGCACACATTGCAGATTGAGAATACGGTGGTCAAAGCCGATATAACTTGTCACAGCAAGAGTCGGAGGAATAAGAAGAAGAAGATTCCTTTGTGCACCGGAGAAGAAGTAGACATGGATTTGTCGGCAATGGACGATTCTCCTGTACTGTGGATTCGTCTGGACCCGGAGATGTCGTTACTGCGTAGCACTATAATATCGCAGCCGGACTACCAGTGGCAGTACCAGCTGCGTCACGAGCGTGACGTCACCGCGCAGAGCGAGGCCATAGACGCGCTGCACACGTTCCCCGAGCCGGCCACGAGGAAGGCTCTCACGGACACCATTGAGAACGAACAGACGTTCTATAAGATACGGTGTAGGGCAGCGCATTGCTTGACAAAGGTGGCGAATGCAATGATAAGTTCATGGGCGGGTCCGCCGGCGATGTTGACGATCTTCCGCAAAATGTTCGGTTCGTTTTCCGCGCCGCATATAATAAAGCAGAACAACTTCGACAACTTGCAGCATTACTTCCTGCAGAAGACTATACCGGTCACCATGGCTGGTCTCCGGAACATCCACGGCATCTGTCCACCGGAAGTCGTGAAATTCCTCTTAGATCTCTTCAAGTACAACGACAATTCGAAGAATCATTTCTCTGATAACTACTACAGAGCTGCTTTGGTGGACGCTCTCGCTGCCACGATCACTCCAGTCATATCCGTGCTGCAACCCGGCGCGCCGATAACGGCAGACTCCCTGTCGGCGGACTCCAGACTGGTCCTGGAAGAGATAACCCGGGTCCTGAATTTGGAGAAGGTGCTGCCGTGCTACAAGAACACGGTGACGGTGAGCTGCCTGCGCGCCATCCGCCGCCTGCAGCAGTGCGGCCACCTGCCCAGCACGCCCATGATATTCAGGGCCTATGCGCAGTACGGACAGTACATTGATGTGCGACTGGCGGCCTTCGAGTGCCTGGTCGAGTTCGTCCGAGTGGACGGGAAGCCGGAGGACCTGGCGTCGCTGCTGACGGCCGTGGAGAGCGACCCCGACCCGGGCGTGCGGCACGGCCTGGCGCGCCTGCTCGTCGACACGCCGCCCTTCGAGCGCGCGCAGAGGCACCGCCTCGACTCCGAGACGGTGGTGCACAGAATATGGAACAATATAAACAGTAATTTGTCGAACGACGCTCGTCTCCGGTGCGACCTTGTGGACCTGTATTACACGTTGTACGGCGCTAAACGTCCTATTTGCTGTCCGCTACCCGAAATACAAGCGATGATAAAGCAGAACCATCAAAAAGAACGAGAACGCCTCGAGAGGGAACGAGAAAGGGAGAGGGAAAAGGAAAGGGAGAGGGAGAGACAGAGCAATCTGGAGTTGAAGCCCGTGATCAAACAGGAGATTGATGACGTGAAATACGATTCGACGATTGGTCCAATGACGAGTACATCGCTATTGGACAATAAAATGGACATCACAGATGAGAACGTGCTTCCGGTTCCGCTGTCCAGTATCAAAGAGGAGGACGTGAAGGTTGACGTAACGACAGTTTCCGCTGAAATTCCCTTAAGAGTTTTTAATGATGATTCGAAACGAGAATTCAGTTCAGATAATGCTGTGGCTCTGCCCGGTATCCCGGGGACTTCGGGACCCATCGGCTTCGAACCTGGAATGTTCAGGCCCCTGAAGGATGAGCTCGGAGCCCCTAAGGCAAAGAAAAAGAAGAAAGAGAAAAAGAAGCACAAACACAAACATAAACACAAGCACAGCAGCAAAGATAAGTCTAAAGAGCACAAGGACAGGTCGTTGCCCCCGAGCCTGCCCCTCGGCACCGACCATCTGAAGATTAAAGAGGAGACCCGTGAGACTCTCAGCTCTTTCAGCTCGAGTCAAAGTCCCTCTGAAGATATCTCCAGCACGCAGGGCAATATGAGTTTTTGA
Protein
MKKERTGDNCRPFKLAHQILSLTGISFERRSVIGFVELTVVPLKDNLRYIRLNAKQSRIYRVCLNDQYEANFQYFDPFLDICQADPNTRSLEAFSQYHLTAAQKTDPDHNSGELHIQIPEEAAHLVGEGRGLRIGIEFSLESPQGGMHFVVPEGEGTLTEKSAHMFTYGHSARLWFPCVDSFAEPCTWKLEFTVDECLTAVSCGELVDVIYTPDHRRKTFHYLVNTPACAPNIALAIGPFETYVDPFMNEVTHYCLPNLLQILKNTVRYLHEAFEFYEETLSTRYPYPCYKQVFVDETEDDATAYTTISILSTHLLHSIAIIDQTYISRKAMAQAVAEQFFGCFITMQNWSDLWLAKGIPDYLCGLYSKKCFGNNAYRYWIHQELKEVMGYEEQYGGIVLDPWQPPASGTRIEPNVFYFPVRNVHTMSPRYIEVMRKKSHLVLRMLEQRIGQELLLQVFNKQLALATNAANTKIGSGLWGHLLLSTNLFVKAIFTVTGKDMAVFVDQWVRTGGHAKFQLTSVFNRKRNTVELEIRQDCVHERGIRKYVGPLLVQLQELDGTFKHTLQIENTVVKADITCHSKSRRNKKKKIPLCTGEEVDMDLSAMDDSPVLWIRLDPEMSLLRSTIISQPDYQWQYQLRHERDVTAQSEAIDALHTFPEPATRKALTDTIENEQTFYKIRCRAAHCLTKVANAMISSWAGPPAMLTIFRKMFGSFSAPHIIKQNNFDNLQHYFLQKTIPVTMAGLRNIHGICPPEVVKFLLDLFKYNDNSKNHFSDNYYRAALVDALAATITPVISVLQPGAPITADSLSADSRLVLEEITRVLNLEKVLPCYKNTVTVSCLRAIRRLQQCGHLPSTPMIFRAYAQYGQYIDVRLAAFECLVEFVRVDGKPEDLASLLTAVESDPDPGVRHGLARLLVDTPPFERAQRHRLDSETVVHRIWNNINSNLSNDARLRCDLVDLYYTLYGAKRPICCPLPEIQAMIKQNHQKERERLEREREREREKERERERQSNLELKPVIKQEIDDVKYDSTIGPMTSTSLLDNKMDITDENVLPVPLSSIKEEDVKVDVTTVSAEIPLRVFNDDSKREFSSDNAVALPGIPGTSGPIGFEPGMFRPLKDELGAPKAKKKKKEKKKHKHKHKHKHSSKDKSKEHKDRSLPPSLPLGTDHLKIKEETRETLSSFSSSQSPSEDISSTQGNMSF
Summary
Description
TFIID is a multimeric protein complex that plays a central role in mediating promoter responses to various activators and repressors. An essential subunit binds to core promoter DNA.
Subunit
Belongs to the TFIID complex which is composed of TATA binding protein (Tbp) and a number of TBP-associated factors (TAFs). Interacts with Tbp, Taf1, Taf11 and Taf12.
Similarity
Belongs to the TAF2 family.
Keywords
Complete proteome
Direct protein sequencing
Nucleus
Phosphoprotein
Reference proteome
Transcription
Transcription regulation
Feature
chain Transcription initiation factor TFIID subunit 2
Uniprot
H9JBS2
A0A2A4JZ75
A0A2H1WDD7
A0A212ETI9
A0A194Q870
L7X0M9
+ More
A0A3S2NRW6 D6WZT8 A0A0T6B482 A0A088AQA5 A0A2J7PJZ4 A0A1S4G185 A0A1Q3F5Y4 A0A0P6IT94 K7IVG4 A0A151J1F2 A0A195D198 A0A151XDB6 A0A158NH00 A0A1B6LDU4 F4WSR6 A0A0M8ZX29 A0A336MMD4 A0A336MRJ9 A0A067R4M3 A0A182GFP6 A0A182GC37 A0A1Y1JZD6 B0WMQ1 A0A0L7QZ07 E2AS08 A0A154NYC2 A0A026X344 A0A195B6H6 A0A0C9R2X1 A0A336MKX7 A0A1B0CCN9 A0A182RAA1 E0V9Y7 A0A182J7U6 A0A195FNU9 A0A182YPI7 A0A182XMQ0 A0A182PPD6 A0A182M9F3 A0A182VCN1 A0A182SU14 A0A182WKW0 A0A1I8PH89 A0A1I8PH07 A0A0L0CNQ5 A0A182QS22 A0A084VPX6 A0A1I8MN66 A0A182K509 A0A182NID5 A7UTV1 A0A182L320 A0A182HWK7 Q7Q6Q1 A0A182TUD2 W8B442 A0A0K8W6B0 A0A1J1IAX7 A0A2M4CS69 A0A2M4CS30 A0A023F4P3 A0A1A9XF11 A0A2M4AMY0 A0A1A9WDZ5 A0A182FDQ5 A0A1A9ZTU1 A0A1B0BBV2 A0A1B0G6D2 A0A1A9UVW5 B4LGL6 B4L098 A0A1B0DAF1 B4MLY0 B4PDX9 A0A0J9RSZ9 B4J2T3 T1HIJ1 B3NGN4 E8NHB1 Q24325 B3M574 A0A1W4UMT8 B4QNQ8 A0A0M4EJQ3 A0A0A9Y392 A0A146MGD9 E2BJS0 A0A3B0JNA2 B5DPM6 B4HLR1 B4H3H1 A0A3B0JW99 A0A2H8U174 A0A1Z5L4C4
A0A3S2NRW6 D6WZT8 A0A0T6B482 A0A088AQA5 A0A2J7PJZ4 A0A1S4G185 A0A1Q3F5Y4 A0A0P6IT94 K7IVG4 A0A151J1F2 A0A195D198 A0A151XDB6 A0A158NH00 A0A1B6LDU4 F4WSR6 A0A0M8ZX29 A0A336MMD4 A0A336MRJ9 A0A067R4M3 A0A182GFP6 A0A182GC37 A0A1Y1JZD6 B0WMQ1 A0A0L7QZ07 E2AS08 A0A154NYC2 A0A026X344 A0A195B6H6 A0A0C9R2X1 A0A336MKX7 A0A1B0CCN9 A0A182RAA1 E0V9Y7 A0A182J7U6 A0A195FNU9 A0A182YPI7 A0A182XMQ0 A0A182PPD6 A0A182M9F3 A0A182VCN1 A0A182SU14 A0A182WKW0 A0A1I8PH89 A0A1I8PH07 A0A0L0CNQ5 A0A182QS22 A0A084VPX6 A0A1I8MN66 A0A182K509 A0A182NID5 A7UTV1 A0A182L320 A0A182HWK7 Q7Q6Q1 A0A182TUD2 W8B442 A0A0K8W6B0 A0A1J1IAX7 A0A2M4CS69 A0A2M4CS30 A0A023F4P3 A0A1A9XF11 A0A2M4AMY0 A0A1A9WDZ5 A0A182FDQ5 A0A1A9ZTU1 A0A1B0BBV2 A0A1B0G6D2 A0A1A9UVW5 B4LGL6 B4L098 A0A1B0DAF1 B4MLY0 B4PDX9 A0A0J9RSZ9 B4J2T3 T1HIJ1 B3NGN4 E8NHB1 Q24325 B3M574 A0A1W4UMT8 B4QNQ8 A0A0M4EJQ3 A0A0A9Y392 A0A146MGD9 E2BJS0 A0A3B0JNA2 B5DPM6 B4HLR1 B4H3H1 A0A3B0JW99 A0A2H8U174 A0A1Z5L4C4
Pubmed
19121390
22118469
26354079
23674305
18362917
19820115
+ More
26999592 20075255 21347285 21719571 24845553 26483478 28004739 20798317 24508170 20566863 25244985 26108605 24438588 25315136 12364791 20966253 24495485 25474469 17994087 17550304 22936249 10731132 12537568 12537572 12537573 12537574 16110336 17569856 17569867 26109357 26109356 8178153 12537569 8276241 18327897 25401762 26823975 15632085 28528879
26999592 20075255 21347285 21719571 24845553 26483478 28004739 20798317 24508170 20566863 25244985 26108605 24438588 25315136 12364791 20966253 24495485 25474469 17994087 17550304 22936249 10731132 12537568 12537572 12537573 12537574 16110336 17569856 17569867 26109357 26109356 8178153 12537569 8276241 18327897 25401762 26823975 15632085 28528879
EMBL
BABH01024589
BABH01024590
BABH01024591
NWSH01000367
PCG76944.1
ODYU01007906
+ More
SOQ51095.1 AGBW02012562 OWR44822.1 KQ459302 KPJ01723.1 KC469892 AGC92654.1 RSAL01000003 RVE54808.1 KQ971372 EFA09648.1 LJIG01009894 KRT82168.1 NEVH01024944 PNF16653.1 GFDL01012122 JAV22923.1 GDUN01000923 JAN94996.1 KQ980555 KYN15558.1 KQ976973 KYN06642.1 KQ982294 KYQ58343.1 ADTU01015419 ADTU01015420 GEBQ01018114 JAT21863.1 GL888327 EGI62723.1 KQ435840 KOX71363.1 UFQT01001519 SSX30895.1 SSX30897.1 KK852704 KDR18047.1 JXUM01010685 KQ560314 KXJ83099.1 JXUM01053738 KQ561789 KXJ77528.1 GEZM01096674 JAV54682.1 DS232000 EDS31136.1 KQ414685 KOC63835.1 GL442209 EFN63782.1 KQ434782 KZC04581.1 KK107020 EZA62441.1 KQ976574 KYM80111.1 GBYB01007167 JAG76934.1 SSX30896.1 AJWK01006930 DS235000 EEB10193.1 KQ981387 KYN41987.1 AXCM01010257 JRES01000234 KNC33084.1 AXCN02000881 ATLV01015067 KE525001 KFB40020.1 AAAB01008960 EDO63725.1 APCN01001497 EAA10740.3 GAMC01010640 JAB95915.1 GDHF01005899 JAI46415.1 CVRI01000042 CRK95593.1 GGFL01003975 MBW68153.1 GGFL01003974 MBW68152.1 GBBI01002773 JAC15939.1 GGFK01008810 MBW42131.1 JXJN01011682 CCAG010000615 CH940647 EDW69454.1 CH933809 EDW18044.1 AJVK01029047 AJVK01029048 CH963847 EDW73191.1 CM000159 EDW93975.2 CM002912 KMY98787.1 CH916366 EDV96074.1 ACPB03016793 CH954178 EDV51270.2 BT125987 AE014296 ADX35966.1 AGB94362.1 X79243 AY070564 CH902618 EDV40579.1 CM000363 EDX09925.1 CP012525 ALC43272.1 GBHO01019589 JAG24015.1 GDHC01000803 JAQ17826.1 GL448636 EFN84045.1 OUUW01000002 SPP76980.1 CH379069 EDY73646.2 CH480815 EDW40943.1 CH479206 EDW30911.1 SPP76981.1 GFXV01008134 MBW19939.1 GFJQ02004717 JAW02253.1
SOQ51095.1 AGBW02012562 OWR44822.1 KQ459302 KPJ01723.1 KC469892 AGC92654.1 RSAL01000003 RVE54808.1 KQ971372 EFA09648.1 LJIG01009894 KRT82168.1 NEVH01024944 PNF16653.1 GFDL01012122 JAV22923.1 GDUN01000923 JAN94996.1 KQ980555 KYN15558.1 KQ976973 KYN06642.1 KQ982294 KYQ58343.1 ADTU01015419 ADTU01015420 GEBQ01018114 JAT21863.1 GL888327 EGI62723.1 KQ435840 KOX71363.1 UFQT01001519 SSX30895.1 SSX30897.1 KK852704 KDR18047.1 JXUM01010685 KQ560314 KXJ83099.1 JXUM01053738 KQ561789 KXJ77528.1 GEZM01096674 JAV54682.1 DS232000 EDS31136.1 KQ414685 KOC63835.1 GL442209 EFN63782.1 KQ434782 KZC04581.1 KK107020 EZA62441.1 KQ976574 KYM80111.1 GBYB01007167 JAG76934.1 SSX30896.1 AJWK01006930 DS235000 EEB10193.1 KQ981387 KYN41987.1 AXCM01010257 JRES01000234 KNC33084.1 AXCN02000881 ATLV01015067 KE525001 KFB40020.1 AAAB01008960 EDO63725.1 APCN01001497 EAA10740.3 GAMC01010640 JAB95915.1 GDHF01005899 JAI46415.1 CVRI01000042 CRK95593.1 GGFL01003975 MBW68153.1 GGFL01003974 MBW68152.1 GBBI01002773 JAC15939.1 GGFK01008810 MBW42131.1 JXJN01011682 CCAG010000615 CH940647 EDW69454.1 CH933809 EDW18044.1 AJVK01029047 AJVK01029048 CH963847 EDW73191.1 CM000159 EDW93975.2 CM002912 KMY98787.1 CH916366 EDV96074.1 ACPB03016793 CH954178 EDV51270.2 BT125987 AE014296 ADX35966.1 AGB94362.1 X79243 AY070564 CH902618 EDV40579.1 CM000363 EDX09925.1 CP012525 ALC43272.1 GBHO01019589 JAG24015.1 GDHC01000803 JAQ17826.1 GL448636 EFN84045.1 OUUW01000002 SPP76980.1 CH379069 EDY73646.2 CH480815 EDW40943.1 CH479206 EDW30911.1 SPP76981.1 GFXV01008134 MBW19939.1 GFJQ02004717 JAW02253.1
Proteomes
UP000005204
UP000218220
UP000007151
UP000053268
UP000283053
UP000007266
+ More
UP000005203 UP000235965 UP000002358 UP000078492 UP000078542 UP000075809 UP000005205 UP000007755 UP000053105 UP000027135 UP000069940 UP000249989 UP000002320 UP000053825 UP000000311 UP000076502 UP000053097 UP000078540 UP000092461 UP000075900 UP000009046 UP000075880 UP000078541 UP000076408 UP000076407 UP000075885 UP000075883 UP000075903 UP000075901 UP000075920 UP000095300 UP000037069 UP000075886 UP000030765 UP000095301 UP000075881 UP000075884 UP000007062 UP000075882 UP000075840 UP000075902 UP000183832 UP000092443 UP000091820 UP000069272 UP000092445 UP000092460 UP000092444 UP000078200 UP000008792 UP000009192 UP000092462 UP000007798 UP000002282 UP000001070 UP000015103 UP000008711 UP000000803 UP000007801 UP000192221 UP000000304 UP000092553 UP000008237 UP000268350 UP000001819 UP000001292 UP000008744
UP000005203 UP000235965 UP000002358 UP000078492 UP000078542 UP000075809 UP000005205 UP000007755 UP000053105 UP000027135 UP000069940 UP000249989 UP000002320 UP000053825 UP000000311 UP000076502 UP000053097 UP000078540 UP000092461 UP000075900 UP000009046 UP000075880 UP000078541 UP000076408 UP000076407 UP000075885 UP000075883 UP000075903 UP000075901 UP000075920 UP000095300 UP000037069 UP000075886 UP000030765 UP000095301 UP000075881 UP000075884 UP000007062 UP000075882 UP000075840 UP000075902 UP000183832 UP000092443 UP000091820 UP000069272 UP000092445 UP000092460 UP000092444 UP000078200 UP000008792 UP000009192 UP000092462 UP000007798 UP000002282 UP000001070 UP000015103 UP000008711 UP000000803 UP000007801 UP000192221 UP000000304 UP000092553 UP000008237 UP000268350 UP000001819 UP000001292 UP000008744
Interpro
IPR042097
Aminopeptidase_N-like_N
+ More
IPR014782 Peptidase_M1_dom
IPR016024 ARM-type_fold
IPR037813 TAF2
IPR002052 DNA_methylase_N6_adenine_CS
IPR031933 UPF0767
IPR036047 F-box-like_dom_sf
IPR006553 Leu-rich_rpt_Cys-con_subtyp
IPR016443 RNA3'_term_phos_cyc_type_2
IPR013791 RNA3'-term_phos_cycl_insert
IPR032675 LRR_dom_sf
IPR001810 F-box_dom
IPR023797 RNA3'_phos_cyclase_dom
IPR020719 RNA3'_term_phos_cycl-like_CS
IPR013792 RNA3'P_cycl/enolpyr_Trfase_a/b
IPR037136 RNA3'_phos_cyclase_dom_sf
IPR036553 RPTC_insert
IPR014782 Peptidase_M1_dom
IPR016024 ARM-type_fold
IPR037813 TAF2
IPR002052 DNA_methylase_N6_adenine_CS
IPR031933 UPF0767
IPR036047 F-box-like_dom_sf
IPR006553 Leu-rich_rpt_Cys-con_subtyp
IPR016443 RNA3'_term_phos_cyc_type_2
IPR013791 RNA3'-term_phos_cycl_insert
IPR032675 LRR_dom_sf
IPR001810 F-box_dom
IPR023797 RNA3'_phos_cyclase_dom
IPR020719 RNA3'_term_phos_cycl-like_CS
IPR013792 RNA3'P_cycl/enolpyr_Trfase_a/b
IPR037136 RNA3'_phos_cyclase_dom_sf
IPR036553 RPTC_insert
Gene 3D
ProteinModelPortal
H9JBS2
A0A2A4JZ75
A0A2H1WDD7
A0A212ETI9
A0A194Q870
L7X0M9
+ More
A0A3S2NRW6 D6WZT8 A0A0T6B482 A0A088AQA5 A0A2J7PJZ4 A0A1S4G185 A0A1Q3F5Y4 A0A0P6IT94 K7IVG4 A0A151J1F2 A0A195D198 A0A151XDB6 A0A158NH00 A0A1B6LDU4 F4WSR6 A0A0M8ZX29 A0A336MMD4 A0A336MRJ9 A0A067R4M3 A0A182GFP6 A0A182GC37 A0A1Y1JZD6 B0WMQ1 A0A0L7QZ07 E2AS08 A0A154NYC2 A0A026X344 A0A195B6H6 A0A0C9R2X1 A0A336MKX7 A0A1B0CCN9 A0A182RAA1 E0V9Y7 A0A182J7U6 A0A195FNU9 A0A182YPI7 A0A182XMQ0 A0A182PPD6 A0A182M9F3 A0A182VCN1 A0A182SU14 A0A182WKW0 A0A1I8PH89 A0A1I8PH07 A0A0L0CNQ5 A0A182QS22 A0A084VPX6 A0A1I8MN66 A0A182K509 A0A182NID5 A7UTV1 A0A182L320 A0A182HWK7 Q7Q6Q1 A0A182TUD2 W8B442 A0A0K8W6B0 A0A1J1IAX7 A0A2M4CS69 A0A2M4CS30 A0A023F4P3 A0A1A9XF11 A0A2M4AMY0 A0A1A9WDZ5 A0A182FDQ5 A0A1A9ZTU1 A0A1B0BBV2 A0A1B0G6D2 A0A1A9UVW5 B4LGL6 B4L098 A0A1B0DAF1 B4MLY0 B4PDX9 A0A0J9RSZ9 B4J2T3 T1HIJ1 B3NGN4 E8NHB1 Q24325 B3M574 A0A1W4UMT8 B4QNQ8 A0A0M4EJQ3 A0A0A9Y392 A0A146MGD9 E2BJS0 A0A3B0JNA2 B5DPM6 B4HLR1 B4H3H1 A0A3B0JW99 A0A2H8U174 A0A1Z5L4C4
A0A3S2NRW6 D6WZT8 A0A0T6B482 A0A088AQA5 A0A2J7PJZ4 A0A1S4G185 A0A1Q3F5Y4 A0A0P6IT94 K7IVG4 A0A151J1F2 A0A195D198 A0A151XDB6 A0A158NH00 A0A1B6LDU4 F4WSR6 A0A0M8ZX29 A0A336MMD4 A0A336MRJ9 A0A067R4M3 A0A182GFP6 A0A182GC37 A0A1Y1JZD6 B0WMQ1 A0A0L7QZ07 E2AS08 A0A154NYC2 A0A026X344 A0A195B6H6 A0A0C9R2X1 A0A336MKX7 A0A1B0CCN9 A0A182RAA1 E0V9Y7 A0A182J7U6 A0A195FNU9 A0A182YPI7 A0A182XMQ0 A0A182PPD6 A0A182M9F3 A0A182VCN1 A0A182SU14 A0A182WKW0 A0A1I8PH89 A0A1I8PH07 A0A0L0CNQ5 A0A182QS22 A0A084VPX6 A0A1I8MN66 A0A182K509 A0A182NID5 A7UTV1 A0A182L320 A0A182HWK7 Q7Q6Q1 A0A182TUD2 W8B442 A0A0K8W6B0 A0A1J1IAX7 A0A2M4CS69 A0A2M4CS30 A0A023F4P3 A0A1A9XF11 A0A2M4AMY0 A0A1A9WDZ5 A0A182FDQ5 A0A1A9ZTU1 A0A1B0BBV2 A0A1B0G6D2 A0A1A9UVW5 B4LGL6 B4L098 A0A1B0DAF1 B4MLY0 B4PDX9 A0A0J9RSZ9 B4J2T3 T1HIJ1 B3NGN4 E8NHB1 Q24325 B3M574 A0A1W4UMT8 B4QNQ8 A0A0M4EJQ3 A0A0A9Y392 A0A146MGD9 E2BJS0 A0A3B0JNA2 B5DPM6 B4HLR1 B4H3H1 A0A3B0JW99 A0A2H8U174 A0A1Z5L4C4
PDB
6MZM
E-value=0,
Score=2770
Ontologies
GO
GO:0008237
GO:0008270
GO:0005669
GO:0003743
GO:0045944
GO:0003682
GO:0006367
GO:0044212
GO:0008168
GO:0016021
GO:0042254
GO:0005730
GO:0060261
GO:0000979
GO:0017025
GO:0051123
GO:0000995
GO:0006352
GO:0008134
GO:0005634
GO:0006366
GO:0005488
GO:0046983
GO:0005216
GO:0006811
GO:0006541
GO:0016812
GO:0016597
PANTHER
Topology
Subcellular location
Nucleus
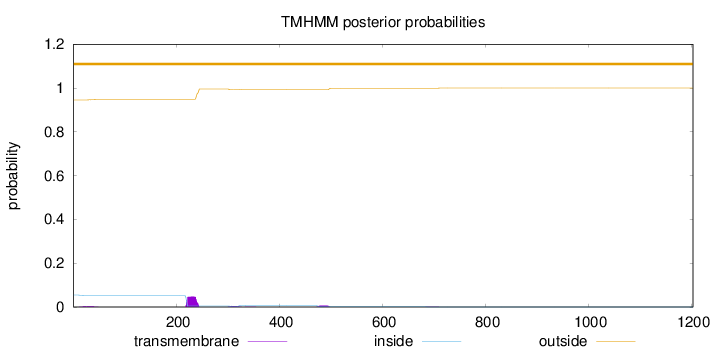
Length:
1203
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
1.30269
Exp number, first 60 AAs:
0.07279
Total prob of N-in:
0.05453
outside
1 - 1203
Population Genetic Test Statistics
Pi
215.025903
Theta
171.123435
Tajima's D
0.798907
CLR
0.192372
CSRT
0.60021998900055
Interpretation
Uncertain
