Gene
KWMTBOMO05735 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA006874
Annotation
Chitinase-related_protein_1_[Operophtera_brumata]
Location in the cell
Extracellular Reliability : 2.033
Sequence
CDS
ATGGGGCATACTACAGCAAAATGGTGTGCAACGACGCTCCTGCTATGCGTATCTGCATTTGCGTCTCCACGTACATCAAGCAATTCCTTCATCAGAAGCGCAGTAGAAACTATCCCACAGCATGACCCCATTCCTGTACCCATTCGTGCATCAGTCGAAAGTATTCCACTTAGGAGCATACGGGATGAAGGTGAAGGAAGACTACCTCTAAGAGATGCGGTCGAAAAGCGACCGATACCCGTATTAAATGCAGAATATAACTACAAATTATTGGGGGACGTGGAACGTATTAATAATGCAAATGGTTTTAATACCGAAGGATACAAACAATATTATGGCGCAGCCAGTTTTCTTAACAACGCCACACATAGTGATGAGCGGCTTCATTTAGGCAATGCGAACTTACAAGAAATGCAGCAAACTTCTGGGGTTGGTGCTGTTCGTCGATTAGTTGTTTGCTACATCGAATCGTGGGCAGCTTACAGAGCTCCACCGTTGGCTTTCACGGCCAGCTTAGTGCCACGATCTTGTACGAACCTTCATTATGCTTTCGCTTCAATGCACCCACACACATATTCAGTCTTGCCCGCTAACGAAGACTTCGATGTTATAAAAGGAGGGTACCGCATTGCGACTGGACTGAAACGTCATATACCTGGATTGAAGGTTATTTTGAGCGTTGGTGGTGAAGGCTCGGATCGTTTGTTTAGTGAGATGGTACAGGAGCCTGTGAGGAGAAACATGTTTATCGAAAGTGCCTTATCATTTTTACAAGAGCATGATTTTGATGGGCTCGATTTACATTGGGTGTATCCAGGTGAAAAGGATGAAAAAGAAAAAGATCTGGTAACAACTTTATTATACGAGATCAGAGAGAAGTTCTCTTCGTATGGCTATTTGCTATCGACAGTTTTGCCGCCGTTTAGATATCAAATAGAAGACGGCTATGATCTGAGTGCTGTGAGTGGGGCAACGGATTATACTATACTACAAGCGTGGGATATGACGCACGGGAGACGGGAGGAACCTCCTGCCAAAGCTGTTCAACACAGCGCTCTACATAGAGACCCAGGCGCTACATCACGGGATCAGCGATATGACAATATTGAATTTATGGTAAAATATATCCTGCGACACGGAATGGCCCCAGAAAAATTGGTGCTGGGTGTACCGCTTTATGGTCGCAGTTATACTTTAGCACCATCGACAAATCCTTATCCGGGAGCCCCCATCGATGGATGGGGAGAAGAAGGACCATACACTCAAACGAAGGGACTTCTAGCTTATTTTGAGATATGTATGGCTGAACGCGAAGGTAAAGGCGTAAGCGGTGTGGATGAAGCTGGTAACGCTTACGCGGTTTTCGATAATCAGTGGGTGACATACGATACCCCATCAACGATCGTTGATAAGATGAAATACGTCATAAGTAGTGGATTAGCTGGAGCTGCAGCGTGGGCGGTCGACATGGATGACTTCAGAGGGTTATGCGGTTCACCATTCCCAATTCTAAGTGCAATTTCTAAAACATTAAACGGGGAAGAAGTACAAACTGACCAATCGACCCTTAAAATCGGATCGTGCGACTCAAATGCTCCTTACTTAGCTTCCGACGAGGAGTCGTGTGCCCACTTTCATTTCTGCACAGGAGCTATTAGTTATAGAATGTCCTGTGAAGATGATCGTTTATACGACCCTTCCACCGGTTACTGCGGGCACCAGGATGTAGGTAAATGCCTCCCAGGACAAAGTTTGCGAATCAGTGTGGAAGATGCAGCTCGTTATCTGTCACATGTTTATGAAACAGACTTCGAGTGGAACAATGAACCTATGAAAGCAGTGGCCAATCGAGACTCAGAACGCCTGACTTCAGACGATGTAGATATTAAGAAAAATAAGGAAAACGACAACAAAGTGGTGTGCTATATGACCAGTTGGGCCTTTTATCGACGTGGCGACGGAAAGTTTGTACCCGAACAAGTGGACACACGTCTGTGTACTCACGTTGTATACGCATATGGCTCACTGTCCCCTGATGAACTTGTTGCCAAAGAATTTGATCCTTGGGCTGACATAACCAATAATTTGTACGAACGTGTCACATCACTCAGAGATGTTAAAGTCCTCCTTGGTTTAGGAGGATGGACAGACTCAGCAGGAGATAAATATTCTCGTTTGGTATCTTCAGATTCAAATCGATCTAAGTTCATAACGAAACTAATACCATTCCTTCGGATGCACAACTTTAAGGGCCTCCACCTGGATTGGAACTATCCCGTTTGCTGGCAAAGTAATTGCAAGAAAGGTGCTCGTTCTGATAAAGCAAATTTTGCTAAATTTGTACAAGAATTAGCGAAAGCATTACACGGTGCCGAAATGGAACTAGGAGTCGCAATCTCTGGTTACAAAGAGGTCATTGAATCAGCGTACGATTTAGCAACAATATCGCGTGAGGCCGATTTTCTAAGCGCTATGACATATGATTACCACGGTGGTTGGGAGAGAACTACCGCTCATCACACGCCCCTGATTCCATCGCCCAAAGACGCATTATCGTATTATTCTATTGAGTATGCAATCAAAGCGATAATTAGCGGTGGTGCCGATCCGAAGAAATTGCTCCTCGGCTTATCGTTCTACGGTCAGTCCTACAGATTAGCGGACGTGGAAAGCACCAGCGGACCCGGGGCACCGGCCGCCGGCCCTGGCGAACCTGGGGAGTTCACCAAGCAGCCCGGAATGTTGGCCTATTACGAAGTCTGCTATAGAGTGAAGAATTTGCGTTGGAAAACGGGACGACAGACAAACGCAGGACCTTACGCCTATTCAGACAATCAGTGGGTCGGATATGATGACCCGAAGTCTATTACCGAAAAGGTGGAATGGGCGATGCGTCTGGGACTGGGCGGCGTGACCGCTTGGGCGATAGACTTGGACGACTCCAGTAACCGATGTTGCGCAGAGCCGTACCCGCTACTACGAGCCGCTGGCCGTGCTCTCGGCCGTTCTGTGCCTTCGCCGCCCACCACGCCCTGCGAACGGCCGCCCGAGCCTGTCACTCCCGCTCCCCCCACTACTACCCCTGCAGAGTCCGATGGTGGAGCGCACGGAAGTGTAGAAGGCGGGTCATGCACTGCCGGTGAATACAGCGCAGCGCCCGGAGACTGCGAGGGATACTTGCAGTGCGAGGGGGGACAGTGGCGGAAACATCGCTGCGCACCCGGCTTGCACTGGGCACCTTCTGTCAGTCGGTGCGACTGGCCCAGTTTCGCTAAATGCACTGCTACATCCAGTAGTGAATCTAGTACGGCAACCACAACTCTGGCTCCGATGACGTCACGTCCGCCGCCTAGACCCACAACTAGTAGGTGGACGACGACCACGACAACTACCACAACAACTACCACAACTACCACTAAGAGACCGACAACTAGACCTACAACTGTAGCATCAGATCCCGTTTCCGAGGGGAAGCCATGTGGCAGTCAAGATTACGAAGCAGTGTCTGGTGACTGCAGCGCGTATCTGCAATGTGACAGCGGAACTTGGCGCATTCAGCACTGCGCTCCTGGATTACACTGGAGCCCGGCCCATAAGCACTGCGACTGGCCTAAATACGCACAGTGTGGAGATTCCGCAACTACTACAACAACCCTTAAGCCGAAACCAACTCGTCCACCAGTACAAGCTACAAGACCAATGACTACACAAGCTTCATCAAGTCAACCACATGAAGACGACGAGTGCAGCAGCAGTGACGTACACGCTTCAGCGTCCACATGCGACTCGTACTTGCTGTGTGTGAGCGGACATTGGCGCAAGCAGATGTGTCCGCCGGGACTTCACTGGGACAAACGGACCAAGCGATGCGATTGGGTCGAATTCGCTATGTGTGAAACAAAACCATCAGCTACCAAGTCGCCAATAACAGTACCGACAAAAACGACTACGTCAGCTACCCGCAGACCAACAACTACGAGACGACCATGGACGACTACTACTTCAAAACCATGGGCCGACGAACCCCAGAAACCTGGAAAAGGTTGCCGCACCGGCACGTATCATGCGCACCCGAAGTGTGAGAAGTTCTACGTTTGCGTGAACGGTCTACTGATAACGCAAAGCTGCGCGCCGGGGCTGGTGTGGCGCCCAGATCGCTCGCAGTGCGACTTCCCTGGCTCCAGCTCATGCTCTGACCGCAGGCAGGGCGTCTCTGCACCCATACTCGACGCGACTAACTCGGCCTCTACTGCCGTCCATGTGCAAGAAGAACCGGAATTTTGTGAAAACGGCCAATATGCTTCATTCCCAAATGATTGCTCAAGATATCGACATTGTTTATTCGGTAAATTCGAAGAGTATTCATGTAGCCCCGGCTTACATTGGAATCAGGAAAAACAAATATGTGATTGGCCAAACAACGTCAAATGTTCAATGAAAGGCACGACTCCGATAACCACGACCACGACTACGACGACATTTCGTCCCGTCGAAATGGATACTATTCACGAGGAACCTCAAAAGCCATATGTACCGTTAAGACCATCAGCACCCCCTTCTGGAACAAACTCTGATATATCAACGAGACCGGCTCTGCTTAATTCACGCTATAAGCTAGTTTGTTATTACACAAACTGGTCCTGGTACAGGCCCGGTATAGGAAAATACAGTCCAGAAGATATCGACCCTACGCTTTGTACGCATATCGTTTACGGATTTGCAGTCCTGGGATCAGATGGACTTATAACTGCCCACGACTCTTGGGCAGATTATGATAATCAATTTTATGAACGCGTAGTTGAATTTAAAAAATACGGTATAAAGGTTTCCATTGCTATCGGAGGATGGAACGACTCGGCAGGAGACAAATATTCTAAGTTAGTGAACGATCCCGCAGCAAGGGCCAGATTTGTAAAACACACTTTGTCATTCGTTGAGCAGTACGGATTCGACGGACTGGACCTCGACTGGGAGTATCCTAAGTGCTGGCAGGTTGACTGTTCTCTAGGCCCTGATTCGGACAAGGAAGCATTCGCTGACTTAGTTCGAGAGCTCTCAGCAGTTTTCAAGCCTAGAGGCTTGCTGCTATCGGCCGCTGTATCACCTAGCAAAATGGTTATAGACGCCGGTTACGATGTCCCAGTATTGGCAAGACATCTTGACTGGATTGCTGTTATGACGTACGACTACCACGGACAATGGGACAAACAGACAGGACACGTGGCGCCCTTGTACTATCACCCTGACGACGACAAAACTTACTTCAATGCCAATTATACAATGCATTATTGGATGAAAAAAGGGGCTCCAGCTTCTAAATTGGTTATGGGTATGCCGATGTACGGGCAAACGTTCACTATAGAAAACAGAGGGATACACGGTTTGAATGCCCCAGCCTCGACCGGCGGAGCGGAGGGTGAATACACAAGAGCCAAAGGATTCTTATCTTACTATGAGATATGCGATCGAATCAGGTACGACGGATGGACAGTTGTCAAAGATCCGCTACAACGAATGGGACCATACGCCTACAAAGGCGATCAATGGGTCTCATTTGACGACACCGACATAATTAAGCAGAAAATTAATTTCATCAAATCCCTTAACCTTGCTGGTGGCATGGTCTGGGCTTTAGATCTTGATGACTTTAGGAATAGGTGCGGACAAGGCAAGCATCCCTTAATAAACGCGATTAAAAAAGGTTTCCTTGATCAAGAAATCCATGACGATCCTATAGTAACAGAACCTCCATTGTTAGAACCTCCAAACGATATTGATGACTCTGACGATATTGAAGTGAGACCCGTTCATTCAAGACCAACTTCCAAGCCAATGAGAGATCCAATGCAAACAACTATGGCAATACAAACAACTAAGAAACCGTCAACTACCGTAGCTCCGTTCGTTGAAGAGCGTTACAGGGTTGTGTGCTACTATACAAACTGGGCTTGGTACAGGCCTGGATCTGGTAAATTCACTCCTAGCAACATAGATCCTTCTCTTTGTACACACATCGTATACGCGTTTGCTGTCCTCGATACAACCCGCTTAGTTATAAAGCCTCATGACATTTGGTTGGATGTCGAAAACAAATTCTACGAGAAAGTAGCTTCCTTGAAGAGCAATGGTGTTAAAGTTGTTCTCGGTTTGGGTGGATGGGACGATTCAGCAAGTGACAAATACTCGAGATTAGTAAACAGTGTATCTGCTCGTAGAAAGTTTATTGTACACGCCATAGACTTTATTGAACAGTATGAATTCGATGGCTTAGATCTAGACTGGGAATATCCAAAATGTTGGCAAGTAAATTGTGAAAAGGGCCCAAGTTCAGACAAACAAGGATTCGCTAATCTTGTAAAAGAATTAAGAGCTGCGTTTGGTCCCCGAGGTCTTCTCCTTTCCGCTGGCGTTTCTGGAAGTAAACGCGTTATCGACGCAGGATATGATATACCAACGCTGTCGAGAAACCTAGATTGGATTTCTTTGATGGCGTACGACTACCACGGACAATGGGATAAAAAGACAGGTCACTTAGCTCCCATGTACGCTCAAGAAGACGAAATTGATGATACTTTGAATGTAAACTACACAGTTAATTATTGGATAGACAAAGGAGCCGATAAAGAGAAACTGGTTATGGGAATTCCATTCTACGGGCAATCGTTTTCATTAGTAGAGGGCGTTGGAACTGGTCTCGGAGCTGAAGCCTACGCTGGCGGAGAAGCTGGAGATGAAACTAGAGCTCGAGGATTTTTATCTTTCTATGAGATATGCGAACGAATTAGGGTGCAAGGTTGGAAAGTAGGTCGTGACCCGGGCGGCCGAATGGGTCCTTATGCTGCATTCGAAGACCAATGGGTATCATTTGACGATGATTACATGGTACGTCATAAAGCCGAATACGTTCGGGCTATGGGACTTGGAGGTGCTATGGCGTGGGCTCTAGATCTTGATGATTTCACTGGAAAATATTGTGGATGTGGAAAGTCGCCTCTTTTGAAAACTATTAATCACGTACTGCGTGGGAAAGAAGCTTCTCCATCGTGCCCACTAGAAGAAATACAAGCACCATCTACTGAAGTTGCAGTCGTTGAACACGATCATGATCATGATCATGAACATCATGATAATCACGATCATGGTGAAGACGGACATGACCATAATGAAGAACATATGACTCCTGATATGGAAAAACCTCCACCTAAGCCACAAGAAAGACCAGAGGACGTTGATATTACTGGATCAAGCCTTGAAGGCAAATCTTGCACAGGAAACGTTTTTAGGTCAGACAACGCCGATTGTACGAAATACTATTTATGTATCAATGGAGCGTACATACAACTTCAGTGCCCTGAACCTCTACACTGGAATAAGAATCACTGCGATTGGCCCGAGAAAGCTCGTTGTGGAACTAAAGCTCAGTTGAAAATAGCCGGACAGTATGACCAAGAGACCCAAGCCGACAAACCTATCCTTGCTTGTTACTTTACAAACTGGGCTTACTATAGGAAAGACAGCGGTAGTTTTGGACCAGAGCAAGTTAACCCATCAATGTGCACACACATCATTTACGCTTGGGCACATCTTGACGACGAAACCTATAAGTTAGTACCGGGAATACCGGAACTAGATCTCGAGAACGACTTTTTCGGAAAAATTACCGAATTAAAGAAAACCGGAGTAAAAGTGATATTAGGTGCGGGAGGTTTAGTAGATTCGGAAAGCGACAAATGGAAACGGATGGCTTCTACTGCTGAAAACAGAATGATATTCATAGACTCAGTTGTTAAGTTCGTGAATAGGTGGAATTTCGACGGAGTGCAGATTGCTTGGCAGTATCCAGTTTGTAAACAGGCTCCATGTATGTATGCATCACGAGACTTCTCTGACGTGGACAATTTTGCCGATCTCCTGTCAACGCTATCTAAAGTACTCCGACAGCACGATCTGGAGTTTTCGGCTATGGTCTCAGCCAATCCTGAGATAGCGGCGCTGGCATACAAACCCCACATACTATCAACAGAATTAGACTGGATATCTGTAGCGGCTAACGACTTCTATGCATCGAATACGGGTCGAGCATCGTATCTCATGCAACTGGATAACAATCAAAATGCAGGAATCAATAGTATGAATGCATCTCTAGCGTATTGGACTAGTGTAGTACAACTACAGAAGCTAGTGGTGGGAGTACCAGCATACGCTCGCGCCTACACATTGCGAAGTGCGTCCAACGCTGTTGCAGGCGCCCCGGCCTCAGGGCCTGGGGAGCCTGGAAAGTACACAGGGATACCTGGTTTCCTTGCATATTTTGAGATTTGTGAAGGTATACGTTCTGGTGAATGGAAAGATACTCATACACGTGATGGCACATTCGCCGTTCACGACAGACAGTGGGCTTCGTACTTAAGTGTCGAGGACGTCCACCGAGTGGGGACGTGGGTGTCGCGTGGTGGCCTGCGGGGCGCGGCGCTGTGGGCTCTCGATCTGGACGACTGGCGCGGGCGGTGCTCCTGCATGCCGCACCCGCTATTAGCTGCTCTACGACAAGGATTAACTGACCCCACGATACCGCTCACTTTATGCGCTTAG
Protein
MGHTTAKWCATTLLLCVSAFASPRTSSNSFIRSAVETIPQHDPIPVPIRASVESIPLRSIRDEGEGRLPLRDAVEKRPIPVLNAEYNYKLLGDVERINNANGFNTEGYKQYYGAASFLNNATHSDERLHLGNANLQEMQQTSGVGAVRRLVVCYIESWAAYRAPPLAFTASLVPRSCTNLHYAFASMHPHTYSVLPANEDFDVIKGGYRIATGLKRHIPGLKVILSVGGEGSDRLFSEMVQEPVRRNMFIESALSFLQEHDFDGLDLHWVYPGEKDEKEKDLVTTLLYEIREKFSSYGYLLSTVLPPFRYQIEDGYDLSAVSGATDYTILQAWDMTHGRREEPPAKAVQHSALHRDPGATSRDQRYDNIEFMVKYILRHGMAPEKLVLGVPLYGRSYTLAPSTNPYPGAPIDGWGEEGPYTQTKGLLAYFEICMAEREGKGVSGVDEAGNAYAVFDNQWVTYDTPSTIVDKMKYVISSGLAGAAAWAVDMDDFRGLCGSPFPILSAISKTLNGEEVQTDQSTLKIGSCDSNAPYLASDEESCAHFHFCTGAISYRMSCEDDRLYDPSTGYCGHQDVGKCLPGQSLRISVEDAARYLSHVYETDFEWNNEPMKAVANRDSERLTSDDVDIKKNKENDNKVVCYMTSWAFYRRGDGKFVPEQVDTRLCTHVVYAYGSLSPDELVAKEFDPWADITNNLYERVTSLRDVKVLLGLGGWTDSAGDKYSRLVSSDSNRSKFITKLIPFLRMHNFKGLHLDWNYPVCWQSNCKKGARSDKANFAKFVQELAKALHGAEMELGVAISGYKEVIESAYDLATISREADFLSAMTYDYHGGWERTTAHHTPLIPSPKDALSYYSIEYAIKAIISGGADPKKLLLGLSFYGQSYRLADVESTSGPGAPAAGPGEPGEFTKQPGMLAYYEVCYRVKNLRWKTGRQTNAGPYAYSDNQWVGYDDPKSITEKVEWAMRLGLGGVTAWAIDLDDSSNRCCAEPYPLLRAAGRALGRSVPSPPTTPCERPPEPVTPAPPTTTPAESDGGAHGSVEGGSCTAGEYSAAPGDCEGYLQCEGGQWRKHRCAPGLHWAPSVSRCDWPSFAKCTATSSSESSTATTTLAPMTSRPPPRPTTSRWTTTTTTTTTTTTTTTKRPTTRPTTVASDPVSEGKPCGSQDYEAVSGDCSAYLQCDSGTWRIQHCAPGLHWSPAHKHCDWPKYAQCGDSATTTTTLKPKPTRPPVQATRPMTTQASSSQPHEDDECSSSDVHASASTCDSYLLCVSGHWRKQMCPPGLHWDKRTKRCDWVEFAMCETKPSATKSPITVPTKTTTSATRRPTTTRRPWTTTTSKPWADEPQKPGKGCRTGTYHAHPKCEKFYVCVNGLLITQSCAPGLVWRPDRSQCDFPGSSSCSDRRQGVSAPILDATNSASTAVHVQEEPEFCENGQYASFPNDCSRYRHCLFGKFEEYSCSPGLHWNQEKQICDWPNNVKCSMKGTTPITTTTTTTTFRPVEMDTIHEEPQKPYVPLRPSAPPSGTNSDISTRPALLNSRYKLVCYYTNWSWYRPGIGKYSPEDIDPTLCTHIVYGFAVLGSDGLITAHDSWADYDNQFYERVVEFKKYGIKVSIAIGGWNDSAGDKYSKLVNDPAARARFVKHTLSFVEQYGFDGLDLDWEYPKCWQVDCSLGPDSDKEAFADLVRELSAVFKPRGLLLSAAVSPSKMVIDAGYDVPVLARHLDWIAVMTYDYHGQWDKQTGHVAPLYYHPDDDKTYFNANYTMHYWMKKGAPASKLVMGMPMYGQTFTIENRGIHGLNAPASTGGAEGEYTRAKGFLSYYEICDRIRYDGWTVVKDPLQRMGPYAYKGDQWVSFDDTDIIKQKINFIKSLNLAGGMVWALDLDDFRNRCGQGKHPLINAIKKGFLDQEIHDDPIVTEPPLLEPPNDIDDSDDIEVRPVHSRPTSKPMRDPMQTTMAIQTTKKPSTTVAPFVEERYRVVCYYTNWAWYRPGSGKFTPSNIDPSLCTHIVYAFAVLDTTRLVIKPHDIWLDVENKFYEKVASLKSNGVKVVLGLGGWDDSASDKYSRLVNSVSARRKFIVHAIDFIEQYEFDGLDLDWEYPKCWQVNCEKGPSSDKQGFANLVKELRAAFGPRGLLLSAGVSGSKRVIDAGYDIPTLSRNLDWISLMAYDYHGQWDKKTGHLAPMYAQEDEIDDTLNVNYTVNYWIDKGADKEKLVMGIPFYGQSFSLVEGVGTGLGAEAYAGGEAGDETRARGFLSFYEICERIRVQGWKVGRDPGGRMGPYAAFEDQWVSFDDDYMVRHKAEYVRAMGLGGAMAWALDLDDFTGKYCGCGKSPLLKTINHVLRGKEASPSCPLEEIQAPSTEVAVVEHDHDHDHEHHDNHDHGEDGHDHNEEHMTPDMEKPPPKPQERPEDVDITGSSLEGKSCTGNVFRSDNADCTKYYLCINGAYIQLQCPEPLHWNKNHCDWPEKARCGTKAQLKIAGQYDQETQADKPILACYFTNWAYYRKDSGSFGPEQVNPSMCTHIIYAWAHLDDETYKLVPGIPELDLENDFFGKITELKKTGVKVILGAGGLVDSESDKWKRMASTAENRMIFIDSVVKFVNRWNFDGVQIAWQYPVCKQAPCMYASRDFSDVDNFADLLSTLSKVLRQHDLEFSAMVSANPEIAALAYKPHILSTELDWISVAANDFYASNTGRASYLMQLDNNQNAGINSMNASLAYWTSVVQLQKLVVGVPAYARAYTLRSASNAVAGAPASGPGEPGKYTGIPGFLAYFEICEGIRSGEWKDTHTRDGTFAVHDRQWASYLSVEDVHRVGTWVSRGGLRGAALWALDLDDWRGRCSCMPHPLLAALRQGLTDPTIPLTLCA
Summary
Similarity
Belongs to the glycosyl hydrolase 18 family.
Uniprot
EMBL
Proteomes
Interpro
Gene 3D
ProteinModelPortal
PDB
6JAY
E-value=0,
Score=1845
Ontologies
PATHWAY
GO
Topology
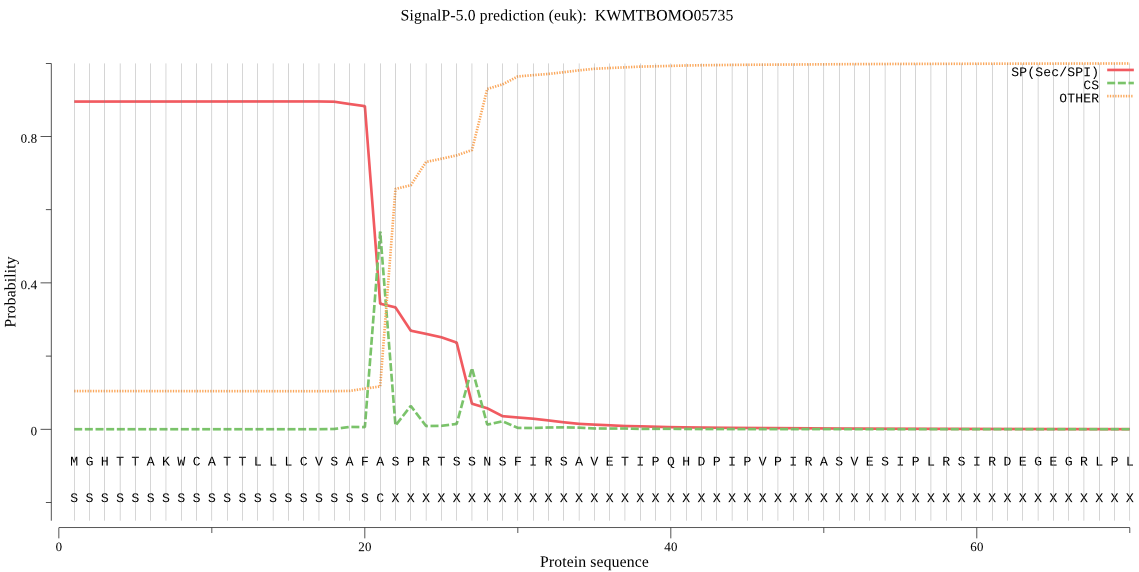
SignalP
Position: 1 - 21,
Likelihood: 0.895135
Length:
2863
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.309190000000001
Exp number, first 60 AAs:
0.27766
Total prob of N-in:
0.01569
outside
1 - 2863
Population Genetic Test Statistics
Pi
220.484393
Theta
188.381942
Tajima's D
0.607438
CLR
0.148387
CSRT
0.543322833858307
Interpretation
Uncertain
