Gene
KWMTBOMO05325
Pre Gene Modal
BGIBMGA002391
Annotation
PREDICTED:_uncharacterized_protein_LOC106720812_[Papilio_machaon]
Location in the cell
Nuclear Reliability : 2.262
Sequence
CDS
ATGCGGGGTGAGCGCTCCAAGTGGGTGGCGGCCTCGCTGGCCTCACTCGCGGTGATCCTGGCGCTCGGCCTGGCACCGCTGGGCTCGGCCGAACTCAATGGAGGGGTTACGGATCCATCGAAACCCGGCCGCGTCGGCGACTGGTGCTCACTAACGGCCGACTGCAACTTTCCTGATGCAGTTTGCGACGAGAGCCAGAAGGTTTGCACGTGCCACCCTGACGTGCCCATCAGCAACCATTTCGATAAATGTGGAAAACACAGCATTGCTCCGAGTGAGACGTCTAAGTCAAAATCATCACGCTCGTCATCCACAATTAAGGCTCAAAAGGCCGCCGTAGAGGCCCTCGCCCTGCGCCGACGTCTTGAGCACGAGCAGGAGCTGGCTGAACGTGAGAGGCAACGTGAAAGTCGACTGGCAGCACTCCGTCAGCAGGTAGAGGAGGGCGAACTGAAGGCCGAACTTGCCGCTCTCGACGCGGAAGCCGCGGCAAGTCACAGCAGTCGCAGTAGTACTGCCAGGGTAAGCGTAGAAAGAACAGAAAGATGGGTACAAAGTTTAGGACAGCCAGTTTGCGTTGGCGAAAATACAGTTAATAGAGGCATCCCCGCAGTAGGGCGAGAGCAAGTAGTGGTTCCGCCTCCCGGCCACCAGGCACCTCTGCCGGCCACTGGGTCAACTGCATCCCCTGTTAACCGTTTTGTTCATCAGAAACAACTTTTAAACGTCACTAAAGCGTCCGAGGCGGCCGTACTTACGCGACCGCTCATTTCCACGGAGGTTGATCAGAGTAGTCTGCTTCAGGCTGTTGCTGACACTGCAGCTGCGGCCAAGGCGCTTGCTACTTCGCACCGTCATAAACATAAGATCGAATTGTTTCCTTTCGACGGAGACGCCTTAACATGGCTACATTTTAAACGTATTTTTGATTTAACCAAAAACAATTTTTCAAATATTGAAAATATTAGTCGGTTACAAAATGCACTTCGCGGCGCGGCCCGAGATGCAGTCGCGTCACTGTTGCTGGCTACAGACAACCCGAACGATATTATAAGAGTTCTGGAGGAGAACTTCGCTCGCCCGGAAATTATAGTATTTAAGGAAGTCTCCGCTCTTAAAAATCTACCACGTTTGGGAAATGACCTGAAAGAGTTAATTACGATAACGAATAAGGTACGTAATTCTATATCTTCTTTTAAAATACTGAATCAAATTGAGTACTTGCATTCTCCAGAACTATTTCACGCCGTCTTAGGAAAATTAAACCCGGTTACTAAAGTAAGATGGACGGACTTTGCTATGCAAGATACTACAGGGCGTCCTAAATTAGAAATTATGTCCGATTTTTTGAGGCGCGAGTTAGATCAACTTATTCGGTTCGGTTTATCACCGGAATCTTGCTCGATCCAACATTCATCACAAAACACTCAACTAAACAAACCGTATAAACGGGAAAATATTCACATAGTTACACACTCTAAACTAAATTCTAAGGCGGCGTCTACACAAAAGCTTGAATGCGCGTTTTGCAAAAAAGATCACAATATTAAGTCATGTTCTGAGTTCAAAGCCTTATCTGTTGATGAAAGGTGGGTCTGGCTGCGTGAGGTAAAAGCGTGTTATAAATGTCTTAGGCGTAGTTCACATCAGTGGAAAACATGTAAAGTTAACCCTTGTGGTGTTGATGGGTGTCTAATACGTCATCACCCGTTAATGCATGGTAAAGAACCTGCCTCTTCTGTCAATACTATGTTCGACACGCAATCCACCGAAAATGATCATACGACTAAGCACCACGAACCTGCATCTGTCGAAAAGGTAATAGTTTCTACCACTTCTACAGGTGTTCAAGAACCCAGCTCCATCTTAACTCTGTGCCCACGTGTATTTCTGAAAATCTTACCCGTTACTGTCTCTGGTCCCTCAGGAAGTTGCAATGTTTACGCACTTCTCGATGACGGTAGCACTGCTACGCTCATTGACTCAAGAATTGCTACTCAAATCGGTGCGACAGGGCCTCACCAGAAAATAACGGTTAATGGTATAGGCGGTCTCAGTAGAAACGCTACGATATCGTATGTAGATTTTCACATTAAGGGTAGGCACACACGAGACACATTTTTAGTGAAAAATGCGAGAGCTATGGAGTCTTTGTCTCTGCGTCCTCAAACAATTAGGCAGGAAACTATTGCTTCTTTCGCACATTTAGCGAATTTACCTTGCAACATAACTTACGAAGATGCTACACCAACAGTTTTAATTGGTGCAGAGCATTGGCATTTGTCAATCAGCAGCGAGGTACGGTGTGGTGGTAAGAATGAACCCGTTGCCTGTTTAACTGCCTTAGGCTGGGTGCTGTATGGAATCGCCTCCAGTAAAACTAAATCAGTGGAGTTTGTTAATCACGGTGTGTGTATCGAACCTTCCAATGAGGAGAAATTAGACTCTTTTATTAGGGAACAATACAAAATTGATTCGTTAGGTATTTCTAAAAAAGAAACTCTACATTCTAAGTCAGATAAACGTGCAGTCGAAATTTTAGAAAAAACTGCTAGACGCCTCCCCACTTCTGGTCGATTTGAGGTGGGTATGCCGTGGCGTGACGATATACAACGCATTCCCGACAGCTACCCTCAAGCCATGTCACGATTTTTAAGTCTAGAAAGGCGCATGGCTAAAGATGCTGACTTTGCAAAAGCATATGACGTGTTCATTTCAAACATGATCGCTAAAGGCTATGCAGAAGAATGTGCTCCTGAGTCATACTACGCCAACCACATTAAAGATAAACAATCTTCTTTTATGAGGCTCTATTTACCCCATTTTGGCGTGTATCACCCTCAGAAACGTAAGCTTCGTGTAGTTCACGACGCCGCAGCCACGAATGCGGGCGTCAGCCTAAACTCTTTATTGCTACCTGGTCCAGACCTGCTTCAGTCCTTGTTAGGTATTTTACTTCGGTTTCGCGAGGGCCGTATTGCTCTCACTGCTGATATCCGGGAAATGTTCCCTCAGGTAAGGATCAGAGAGCAAGATAGGGACGCCCTCCGGTTTCTCTGGAGGTCAAGCAGAGACCAACCTATAAAGGAGTTTAGGATGACAGCCATCATTTTCGGTGCGTGCTGCAGTCCATTTATAGCGCAATTTATTAAAAATAAAAACGCTCGTGAGCACGAAAGTTTATTTCCTAAAGCAGCTCATGCTATTTTGTACAATCATTATATGGACGATTATATTGACTCTCTCGATGACATTCAAGAGGCAGCACAACTGGCGGCAGATATTGTTGCCGTTCACAATGATGCCTACTTCGAGATGCGGGGCTGGATTTCCAACGATCCATCAGCGCTAAAATTTATTCCTGCTGATCTTAGGGCCACTCAACCGTCGTTGGAAATCAACCTTGGCAGCTGCTCTGCAAACAATATTAGAGCGTTGGGAGTATTGTGGAATCCCATAACAGATAATTTAGGGTTCCGCTCAGGCTTAGGTGAAACATTTCCAAACCCTCTCACAAAACGCAAAGTTCTTTGTCACCTCATGCGTGTGTACGACCCGTTAGGCTTATTAGCTCCAATAGTTGTTAAGGGTCGAATTTTATTTCAACAAACGTGGAGGTCTAATGTCGACTGGGACACCGAGTTCCAACCCACGGAAGCATTAAGATGGTCTGATTGGTTTCAGGAGTTGTCAAAAGTAACTTCTTTGGAAATTCCGCGTTGGTATTCTAACTCTAAAAACTCTGAACCAACTCAGAGGGAGTTACACGTTTTTGCTGATGCAAGTGAGCTCGCGTACGCATGTGTCGCTTATTGGCGCCTTTTATACTCAGACGGCAGCATCAAGCTTTCTCTCATCTCTAGTAAGGCAAGAGTTACACCCTTGAAACCTATCTCTATCCCACGTTTAGAGCTCCAGGCCGCTTTAATAGCTTCTCGTCTCGCGGTCACCATTAAGGACAGTCATAGAAAACAACCGGCACATACTTTCTTTTGGACCGATTCTATGACAGTCCTTCAGTGGTTACCGGCAAGCATCAATGAATCCTGCTTGTTTAATGAGCAGTGCGAAGACGTTGACTTCAAGACCGAGTGCAAGAATGAACGTTGCGCTTGCAAGTTCGAGATGGTACCGCTGGTCACCGTCGACGGAGCAGTTATATGTACTCCCGTAAAACCAGTTGATGAGTCTACCAGGACCGTTGACCCCGCGATGATTGGAGTCCTCGTCGGCATGGCGCTGATGTTCGTCATCATTTGCGTTGTTCTTCGGCTTTTCAGCAGGGCAAGATGGCGTGAAAACAGGACGATCTTCAACACTCCAAATCCTCGTCTGATGAATGTTTCTTTGCTCAGAGAATCTAAGCTGTTGCACTCTCAGGACCGTCGTGGTTCTAGAGTGAGCATGCGCCCGCCTTCTCGGCAGGCGAGCCAGCAGGAGTTAAGACCCCACTCGCCGAGTCCAGGCTCTCATCGTGGTTCAAGAGCAAGTAGCGGGCATTCAGCCACGTCATTGCGTTCAGCAACTCTGAGATCTCCAACGACTCCTGGACCGGCCTCAGTTACAGTCCAAATACGAGCTCCAGATACGTAA
Protein
MRGERSKWVAASLASLAVILALGLAPLGSAELNGGVTDPSKPGRVGDWCSLTADCNFPDAVCDESQKVCTCHPDVPISNHFDKCGKHSIAPSETSKSKSSRSSSTIKAQKAAVEALALRRRLEHEQELAERERQRESRLAALRQQVEEGELKAELAALDAEAAASHSSRSSTARVSVERTERWVQSLGQPVCVGENTVNRGIPAVGREQVVVPPPGHQAPLPATGSTASPVNRFVHQKQLLNVTKASEAAVLTRPLISTEVDQSSLLQAVADTAAAAKALATSHRHKHKIELFPFDGDALTWLHFKRIFDLTKNNFSNIENISRLQNALRGAARDAVASLLLATDNPNDIIRVLEENFARPEIIVFKEVSALKNLPRLGNDLKELITITNKVRNSISSFKILNQIEYLHSPELFHAVLGKLNPVTKVRWTDFAMQDTTGRPKLEIMSDFLRRELDQLIRFGLSPESCSIQHSSQNTQLNKPYKRENIHIVTHSKLNSKAASTQKLECAFCKKDHNIKSCSEFKALSVDERWVWLREVKACYKCLRRSSHQWKTCKVNPCGVDGCLIRHHPLMHGKEPASSVNTMFDTQSTENDHTTKHHEPASVEKVIVSTTSTGVQEPSSILTLCPRVFLKILPVTVSGPSGSCNVYALLDDGSTATLIDSRIATQIGATGPHQKITVNGIGGLSRNATISYVDFHIKGRHTRDTFLVKNARAMESLSLRPQTIRQETIASFAHLANLPCNITYEDATPTVLIGAEHWHLSISSEVRCGGKNEPVACLTALGWVLYGIASSKTKSVEFVNHGVCIEPSNEEKLDSFIREQYKIDSLGISKKETLHSKSDKRAVEILEKTARRLPTSGRFEVGMPWRDDIQRIPDSYPQAMSRFLSLERRMAKDADFAKAYDVFISNMIAKGYAEECAPESYYANHIKDKQSSFMRLYLPHFGVYHPQKRKLRVVHDAAATNAGVSLNSLLLPGPDLLQSLLGILLRFREGRIALTADIREMFPQVRIREQDRDALRFLWRSSRDQPIKEFRMTAIIFGACCSPFIAQFIKNKNAREHESLFPKAAHAILYNHYMDDYIDSLDDIQEAAQLAADIVAVHNDAYFEMRGWISNDPSALKFIPADLRATQPSLEINLGSCSANNIRALGVLWNPITDNLGFRSGLGETFPNPLTKRKVLCHLMRVYDPLGLLAPIVVKGRILFQQTWRSNVDWDTEFQPTEALRWSDWFQELSKVTSLEIPRWYSNSKNSEPTQRELHVFADASELAYACVAYWRLLYSDGSIKLSLISSKARVTPLKPISIPRLELQAALIASRLAVTIKDSHRKQPAHTFFWTDSMTVLQWLPASINESCLFNEQCEDVDFKTECKNERCACKFEMVPLVTVDGAVICTPVKPVDESTRTVDPAMIGVLVGMALMFVIICVVLRLFSRARWRENRTIFNTPNPRLMNVSLLRESKLLHSQDRRGSRVSMRPPSRQASQQELRPHSPSPGSHRGSRASSGHSATSLRSATLRSPTTPGPASVTVQIRAPDT
Summary
Uniprot
A0A2A4IX21
Q2MGA5
A0A1Y1LL75
A0A182G158
A0A226DH22
A0A226DM06
+ More
A0A226EEI4 A0A226E2P7 A0A182H5B8 A0A182HCB4 A0A1W7R6M1 A0A2M4CKI9 A0A226D351 A0A1W7R6A0 W8AJC8 A0A1W7R6F7 A0A2M4CVY8 A0A182HDB0 A0A1W7R6E5 A0A2M4B931 A0A2M4B962 Q76C95 A0A182HEF9 Q76C94 A0A226EDU9 A0A2M4CKZ8 O02006 A0A2M4BAL5 A0A2M4B963 A0A2M4B9E1 A0A2M4B9W9 A0A2M4B9D0 A0A2M4B8T6 A0A085N087 A0A0V0T6X5 A0A0V1GTE8 A0A0V0Z419 A0A0V1MV06 A0A0V1MUH2 A0A0V0WCL3 A0A1W7R6D5 A0A0V1CGE6 C7C204 A0A0V1KSQ0 A0A085N9I5 A0A0V0ULI0 A0A0V0UE53 A0A0V1BN71 A0A0V0SIP4 A0A0V1JNT0 A0A0V1KCJ6 A0A0V1E497 A0A0V1G1T1 A0A0V1GX78 A0A0V1KA91 A0A0V0XF38 W4XEJ7
A0A226EEI4 A0A226E2P7 A0A182H5B8 A0A182HCB4 A0A1W7R6M1 A0A2M4CKI9 A0A226D351 A0A1W7R6A0 W8AJC8 A0A1W7R6F7 A0A2M4CVY8 A0A182HDB0 A0A1W7R6E5 A0A2M4B931 A0A2M4B962 Q76C95 A0A182HEF9 Q76C94 A0A226EDU9 A0A2M4CKZ8 O02006 A0A2M4BAL5 A0A2M4B963 A0A2M4B9E1 A0A2M4B9W9 A0A2M4B9D0 A0A2M4B8T6 A0A085N087 A0A0V0T6X5 A0A0V1GTE8 A0A0V0Z419 A0A0V1MV06 A0A0V1MUH2 A0A0V0WCL3 A0A1W7R6D5 A0A0V1CGE6 C7C204 A0A0V1KSQ0 A0A085N9I5 A0A0V0ULI0 A0A0V0UE53 A0A0V1BN71 A0A0V0SIP4 A0A0V1JNT0 A0A0V1KCJ6 A0A0V1E497 A0A0V1G1T1 A0A0V1GX78 A0A0V1KA91 A0A0V0XF38 W4XEJ7
EMBL
NWSH01005440
PCG64209.1
AF530470
AAQ09229.1
GEZM01052588
GEZM01052587
+ More
GEZM01052586 JAV74402.1 JXUM01136032 KQ568367 KXJ69026.1 LNIX01000019 OXA44855.1 LNIX01000015 OXA46575.1 LNIX01000004 OXA55241.1 LNIX01000007 OXA52015.1 JXUM01111221 KQ565482 KXJ70922.1 JXUM01127084 KQ567147 KXJ69602.1 GEHC01000872 JAV46773.1 GGFL01001682 MBW65860.1 LNIX01000039 OXA39294.1 GEHC01000947 JAV46698.1 GAMC01017930 JAB88625.1 GEHC01000945 JAV46700.1 GGFL01005193 MBW69371.1 JXUM01034199 KQ561015 KXJ80028.1 GEHC01000955 JAV46690.1 GGFJ01000402 MBW49543.1 GGFJ01000401 MBW49542.1 AB110069 BAD01589.1 JXUM01005879 KQ560203 KXJ83865.1 BAD01590.1 OXA55408.1 GGFL01001727 MBW65905.1 D83207 BAA57030.1 GGFJ01000935 MBW50076.1 GGFJ01000432 MBW49573.1 GGFJ01000470 MBW49611.1 GGFJ01000487 MBW49628.1 GGFJ01000471 MBW49612.1 GGFJ01000306 MBW49447.1 KL367585 KFD62883.1 JYDJ01000512 KRX34809.1 JYDP01000296 KRZ01365.1 JYDQ01000499 KRY07301.1 JYDO01000040 KRZ75294.1 KRZ75306.1 JYDK01000180 KRX73317.1 GEHC01000921 JAV46724.1 JYDI01000209 KRY48378.1 FN356218 CAX83707.1 JYDW01000285 KRZ49986.1 KL367527 KFD66131.1 JYDN01000258 KRX52286.1 JYDJ01000015 KRX49522.1 JYDH01000025 KRY38464.1 JYDL01000006 KRX26626.1 JYDV01000070 KRZ36622.1 JYDV01000004 KRZ44960.1 JYDR01000106 KRY68661.1 JYDT01000008 KRY92224.1 JYDS01000555 KRZ02797.1 JYDV01000007 KRZ44161.1 JYDU01000375 KRX86446.1 AAGJ04115911
GEZM01052586 JAV74402.1 JXUM01136032 KQ568367 KXJ69026.1 LNIX01000019 OXA44855.1 LNIX01000015 OXA46575.1 LNIX01000004 OXA55241.1 LNIX01000007 OXA52015.1 JXUM01111221 KQ565482 KXJ70922.1 JXUM01127084 KQ567147 KXJ69602.1 GEHC01000872 JAV46773.1 GGFL01001682 MBW65860.1 LNIX01000039 OXA39294.1 GEHC01000947 JAV46698.1 GAMC01017930 JAB88625.1 GEHC01000945 JAV46700.1 GGFL01005193 MBW69371.1 JXUM01034199 KQ561015 KXJ80028.1 GEHC01000955 JAV46690.1 GGFJ01000402 MBW49543.1 GGFJ01000401 MBW49542.1 AB110069 BAD01589.1 JXUM01005879 KQ560203 KXJ83865.1 BAD01590.1 OXA55408.1 GGFL01001727 MBW65905.1 D83207 BAA57030.1 GGFJ01000935 MBW50076.1 GGFJ01000432 MBW49573.1 GGFJ01000470 MBW49611.1 GGFJ01000487 MBW49628.1 GGFJ01000471 MBW49612.1 GGFJ01000306 MBW49447.1 KL367585 KFD62883.1 JYDJ01000512 KRX34809.1 JYDP01000296 KRZ01365.1 JYDQ01000499 KRY07301.1 JYDO01000040 KRZ75294.1 KRZ75306.1 JYDK01000180 KRX73317.1 GEHC01000921 JAV46724.1 JYDI01000209 KRY48378.1 FN356218 CAX83707.1 JYDW01000285 KRZ49986.1 KL367527 KFD66131.1 JYDN01000258 KRX52286.1 JYDJ01000015 KRX49522.1 JYDH01000025 KRY38464.1 JYDL01000006 KRX26626.1 JYDV01000070 KRZ36622.1 JYDV01000004 KRZ44960.1 JYDR01000106 KRY68661.1 JYDT01000008 KRY92224.1 JYDS01000555 KRZ02797.1 JYDV01000007 KRZ44161.1 JYDU01000375 KRX86446.1 AAGJ04115911
Proteomes
Pfam
Interpro
IPR008042
Retrotrans_Pao
+ More
IPR005312 DUF1759
IPR040676 DUF5641
IPR036397 RNaseH_sf
IPR001584 Integrase_cat-core
IPR012337 RNaseH-like_sf
IPR011011 Znf_FYVE_PHD
IPR013083 Znf_RING/FYVE/PHD
IPR001965 Znf_PHD
IPR019787 Znf_PHD-finger
IPR019786 Zinc_finger_PHD-type_CS
IPR001878 Znf_CCHC
IPR006094 Oxid_FAD_bind_N
IPR016166 FAD-bd_PCMH
IPR016164 FAD-linked_Oxase-like_C
IPR041588 Integrase_H2C2
IPR016170 Cytok_DH_C_sf
IPR015213 Cholesterol_OX_subst-bd
IPR036318 FAD-bd_PCMH-like_sf
IPR016169 FAD-bd_PCMH_sub2
IPR016167 FAD-bd_PCMH_sub1
IPR001841 Znf_RING
IPR000477 RT_dom
IPR008737 Peptidase_asp_put
IPR000253 FHA_dom
IPR000048 IQ_motif_EF-hand-BS
IPR021109 Peptidase_aspartic_dom_sf
IPR001969 Aspartic_peptidase_AS
IPR036875 Znf_CCHC_sf
IPR005312 DUF1759
IPR040676 DUF5641
IPR036397 RNaseH_sf
IPR001584 Integrase_cat-core
IPR012337 RNaseH-like_sf
IPR011011 Znf_FYVE_PHD
IPR013083 Znf_RING/FYVE/PHD
IPR001965 Znf_PHD
IPR019787 Znf_PHD-finger
IPR019786 Zinc_finger_PHD-type_CS
IPR001878 Znf_CCHC
IPR006094 Oxid_FAD_bind_N
IPR016166 FAD-bd_PCMH
IPR016164 FAD-linked_Oxase-like_C
IPR041588 Integrase_H2C2
IPR016170 Cytok_DH_C_sf
IPR015213 Cholesterol_OX_subst-bd
IPR036318 FAD-bd_PCMH-like_sf
IPR016169 FAD-bd_PCMH_sub2
IPR016167 FAD-bd_PCMH_sub1
IPR001841 Znf_RING
IPR000477 RT_dom
IPR008737 Peptidase_asp_put
IPR000253 FHA_dom
IPR000048 IQ_motif_EF-hand-BS
IPR021109 Peptidase_aspartic_dom_sf
IPR001969 Aspartic_peptidase_AS
IPR036875 Znf_CCHC_sf
SUPFAM
ProteinModelPortal
A0A2A4IX21
Q2MGA5
A0A1Y1LL75
A0A182G158
A0A226DH22
A0A226DM06
+ More
A0A226EEI4 A0A226E2P7 A0A182H5B8 A0A182HCB4 A0A1W7R6M1 A0A2M4CKI9 A0A226D351 A0A1W7R6A0 W8AJC8 A0A1W7R6F7 A0A2M4CVY8 A0A182HDB0 A0A1W7R6E5 A0A2M4B931 A0A2M4B962 Q76C95 A0A182HEF9 Q76C94 A0A226EDU9 A0A2M4CKZ8 O02006 A0A2M4BAL5 A0A2M4B963 A0A2M4B9E1 A0A2M4B9W9 A0A2M4B9D0 A0A2M4B8T6 A0A085N087 A0A0V0T6X5 A0A0V1GTE8 A0A0V0Z419 A0A0V1MV06 A0A0V1MUH2 A0A0V0WCL3 A0A1W7R6D5 A0A0V1CGE6 C7C204 A0A0V1KSQ0 A0A085N9I5 A0A0V0ULI0 A0A0V0UE53 A0A0V1BN71 A0A0V0SIP4 A0A0V1JNT0 A0A0V1KCJ6 A0A0V1E497 A0A0V1G1T1 A0A0V1GX78 A0A0V1KA91 A0A0V0XF38 W4XEJ7
A0A226EEI4 A0A226E2P7 A0A182H5B8 A0A182HCB4 A0A1W7R6M1 A0A2M4CKI9 A0A226D351 A0A1W7R6A0 W8AJC8 A0A1W7R6F7 A0A2M4CVY8 A0A182HDB0 A0A1W7R6E5 A0A2M4B931 A0A2M4B962 Q76C95 A0A182HEF9 Q76C94 A0A226EDU9 A0A2M4CKZ8 O02006 A0A2M4BAL5 A0A2M4B963 A0A2M4B9E1 A0A2M4B9W9 A0A2M4B9D0 A0A2M4B8T6 A0A085N087 A0A0V0T6X5 A0A0V1GTE8 A0A0V0Z419 A0A0V1MV06 A0A0V1MUH2 A0A0V0WCL3 A0A1W7R6D5 A0A0V1CGE6 C7C204 A0A0V1KSQ0 A0A085N9I5 A0A0V0ULI0 A0A0V0UE53 A0A0V1BN71 A0A0V0SIP4 A0A0V1JNT0 A0A0V1KCJ6 A0A0V1E497 A0A0V1G1T1 A0A0V1GX78 A0A0V1KA91 A0A0V0XF38 W4XEJ7
Ontologies
GO
Topology
SignalP
Position: 1 - 30,
Likelihood: 0.981129
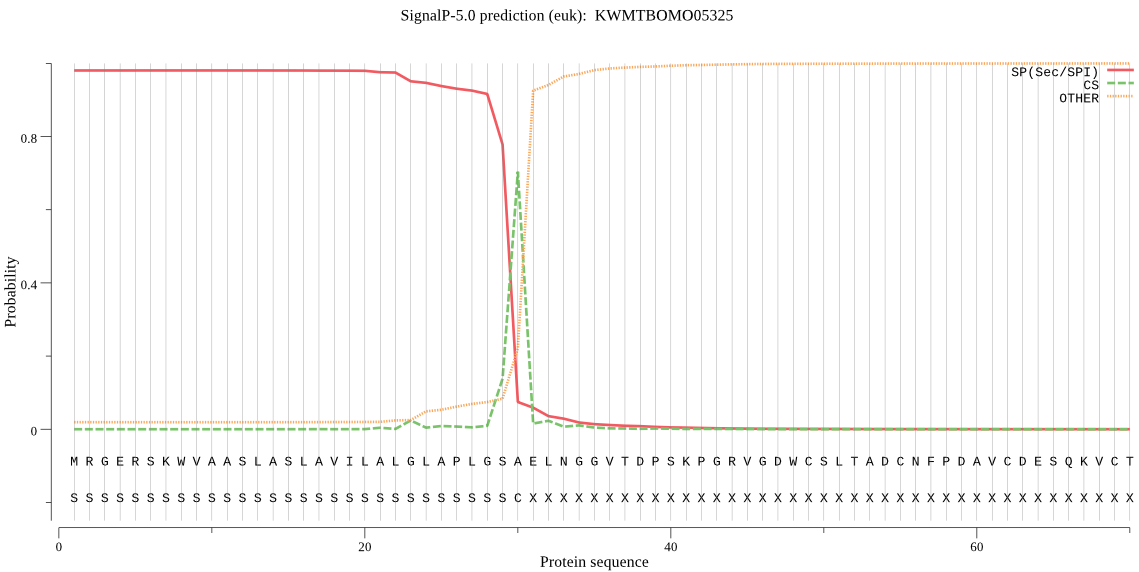
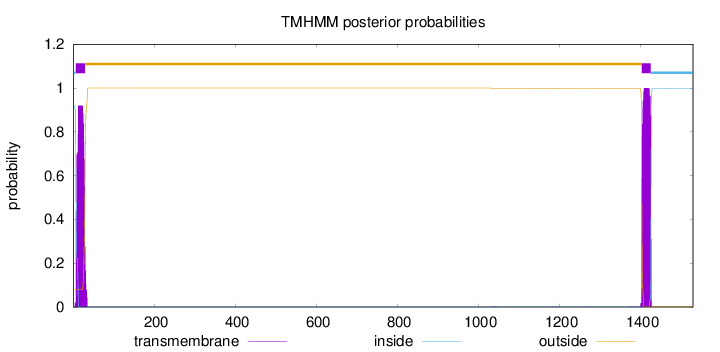
Length:
1530
Number of predicted TMHs:
2
Exp number of AAs in TMHs:
41.87857
Exp number, first 60 AAs:
19.30428
Total prob of N-in:
0.91991
POSSIBLE N-term signal
sequence
inside
1 - 6
TMhelix
7 - 29
outside
30 - 1403
TMhelix
1404 - 1426
inside
1427 - 1530
Population Genetic Test Statistics
Pi
285.968808
Theta
181.094001
Tajima's D
1.623165
CLR
1.089143
CSRT
0.814009299535023
Interpretation
Uncertain
