Gene
KWMTBOMO05268
Pre Gene Modal
BGIBMGA002499
Annotation
PREDICTED:_uncharacterized_protein_LOC106720604_[Papilio_machaon]
Location in the cell
Nuclear Reliability : 4.543
Sequence
CDS
ATGCATAGTGTAATTTATAGAAAGTCTGACGTCCAGCACCCTCATGAAAACAACGAAGGCACGCCCTGCGCTTCGCATCTCCTTCACGTGAAACGAACACTCGGGAACAATGCTGAACTCTTCAATTTCACTGAACATCGAACATCGAAAGACGCAACTAGCAATGACACTACTGAGGATTTACGTAGCGAAATTCACAGGCGTAAGAAACGTTGGCTTCCTGAAGACGAAATGCAAGATGATCAGCCAAAGAAAAATCCCGAATTACCATTAGACTTAGACTTTCCTTACACCAGCAACGGCGACCCGTTCGATAGCAAGCTAAGCACGAGGAAACCGAAAACCAAAATTGACAAGAGCAACCTAATAACCAAGGTGCGACTCGATTCCGAAGAGTCGAGACCGAAACCAAAGACCCACGTCGAAGTGATCAAATCGAAGCCCGGCGTCGGGGTGATCAGCAAGGACATCGTTAAGAAGGAGCCGGTCGTGTACTCGGTGCTGACGGCGAACGCCAGCGACGACGGGCGACACGTTAACAAACGGGCCACCGTCGACCCGAAGAAAACCACGTGTCTGGTATACCTGCAGGCCGATCACATGTTCTATCAACGGTATGGCTCTGAGGAGGCCTGCATTGAGGTCATGACCAGACACGTGCAGAAAGTCAACGCAATATATAAAGTGACGGATTTCAATCTGGACGGAAAACCTGATAACATAACCTTCATGATCAAAAGGATAAAGGTCCACACTCTGGACGCTCTAAAAGACCCGGCTTATAGGTTCCCTAACAATTACGGCGTGGAAAAATACTTGGAGCTTTTTTCGGAGGAGGATTACGACGCATTCTGTTTGGCGTACATGTTTACGTATCGCGACTTCGAGATGGGCACGCTCGGCCTGGCTTGGACGGGCGATCTGAAGAATGCAGGCGGCGTCTGCGAAAAGAACGGGCACTATCGAGGCAGCATGAAGTCATTGAACACAGGCATCGTGACGTTACTGAACTACGGGAAGCACGTGCCTCCTGCCGTGTCGCACGTCACACTGGCGCATGAAATCGGACATAACTTTGGCTCGCCGCATGACCCAGAAATGTGCACACCATTCGGCGAAGACGGCAACTATATAATGTTCGCAAGGGCGACTAGCGGCGACAGAAAGAACAACAATAAGTTCTCCCCATGTTCGCTGAAGTCCATTGATCCAGTCTTAAATAACAAGGCCAGATCACCTAAGGGATGCTTTACAGAGCCGCAGCCCGCCATCTGCGGTAACGGCGTGGTGGAGGAGGGCGAGGAGTGCGACTGCGGCTGGGCCTCCGAGTGTACGGACGTATGCTGCCGCCCGCAAGCCGCGCGCCCTCTCTACAAACCCTGCACATTGACCGAGCACAGCGTTTGCAGTCCCAGTCAAGGTCCTTGTTGCACGGCTTCGTGCACGCTGAAGTTCGGCGACAAGTGTCGGTCGGACAACGGATGTCGCGACGCCGCGCACTGCGACGGCAAGCGTGCCGCGTGTCCCTCCAGCAGACACAAACCGAACAGGACGAGATGCGACAAAGAACTCGTCTGTTACATGGGAGAGTGCACCGGCTCAATATGCCTGGCATACGGTCTGGAATCGTGTCAGTGCTCCCCTCGAAGCGACGACCCTCGGTCCGCTTGCGAGCTGTGCTGCCGCAAGCCTGGCGGGCAGTGCCTGTCCTCCTTCCACTGGAACACCGCCCCGTACGACGTGCCCGACATGTACGCCAAGCCCGGCACGCCTTGCAATGACTACAATGGATACTGCGATGTATTCCAAAAGTGTCGTGAAGTGGACCCCTCTGGTCCGCTGGCGACTCTCCGAAAGCTGCTGTTGTCGGACGAGAGTATCGCCGGCTTCAAGCGGTGGATGCTGCGTCACTGGTACGCGGTGCTGCTCATCCTGCTGGCCGTCATCGCGTTACTGGTCGCGAGCACCCGTTTCTTCGGTCGTCACGGCAAGAAGCTGAAGTCGGTGACGATCATCCACTCGTCTACAACGGAAACCGTTCGACTGCCTGATGCTGCCGATCAAGGATTAATAGTTCATACTGCTATCAGGTCAAAAGTGCCATTAAAGAAGAAGGTAGCTCTCAGGACCAGAGCGTACCGCAACAAGAAGGATCTCAAAAACAAACAAGGCGACAAGGCACCGCTCTCAGACGGAGCCAAGAAGAGGAAGCCAACAAGTCAAGTCAAACACGAGGAACCGCAGAAAGTGATCAAGGAGACAACGGCGATCGTAACCAGCCCAGAGGGGAAGTCCCCCAAACACGTAATCCTGTCGAAACATAAAAACAAGGTTAAGAAACGGAAAATGAAACTGAAGAAGGAGACCATAGACTACAGCTCCATGCAGAAGCATTCCGCCTCGCCCACGAAAGACTCGGAGGCCCTGAGCAAAGTCCAGAAGTGGCTGTTGAGCTCGCCGCAGCCGACTGTCATACCAAAGTCCAAGTCCATCCCCCTGGGCCTCACGGAGCGGTCGCACAGGCCCACCTCGAAGGGTCCTCGGAAAACGAGACCGTCGAAGAGCGCCACCAACTTGTTGAGCGGAGAAAAGGCGAGACTCCAAGTCGTATTCAAACCGCCGTTCCGGTTCAGCGTTAAGATATGCAAGAGCGACAAGACCAAAGTGGTTCTAGACAAGTCGTCCAAACCCGACATCGAGAGGAAACGCCACGAGGCCGCCGCCCAACACCCCCCCGCGGATCCCAAACTCAACACATTCAGTAGAACGAAACCTCATAATGCCGCTCGACTTGAAAATACTCCTTCAAACGCTTCGACCGGAGAAAAGACACAGCACCAAGATAAAGGCAGTCACGGATACGAAAACTTGTTGCCCAGGAGCGCCAGTGATTGCAAACTCACCAAACAGATGTCCGACGTCAATCTCAGACACAAGAAGAGCAACTCGGTCGGCCAGAGGAAGGGGACCACCGAGAGCAAACAGAACCTCATCTGTCACGAAGACAACGACAGCGCGCACCTTTACGAGAACGTGACGTCACCGGAGACGCTCGCGCCGAAGAGCTGCAGCATGCCGCGGCGACAGCACGGCACCGCCATCGCGCGCCAGAGCAGCTACGGGCACCTGCCGCGCGCGCAGCCCCGCCCGCACCGCCGCAGCGCCACCAGCCTCGCCGCCGCCGAACCCGACCTCGACCACTTCTACAGCGTCATCGCGTCGCTGCGCCGGGACGGACGCGCACACACCAACACCGCCAGCTCCTCCGCCTCCAACAGGACCAACACAAACAGACCGGCCGGAAGGAGCTCACGACAGAACAGTTCAGTGGAAGCACCGACGCGATCCAATCCTGCTTCGCCCTCGAAGCTGAAGAGGCAAGCTAGCGAAGCGGAAATCACGAAGCAGCAATGTGACGGTGGCGTGAGAGGCTTCCAGCTAGTCGTGGGGAAGGAGAAGCTGAAACGGCAGATGAGTGATAACGAACTGTGCAAGTCTCGAGTGCAGCTAGCGATGCCAATGTCTGCGGGCGCCGAGCCGCGCCAGCCGTTCTGTTGGAACAAGCGCGCCAGTCTCGACTGCGAGGCCTCCCTGCCCGGCGCCGCGCGGCCCGCGGGCTCCAGGCTCGCTAACAAGCGCACCTACACGTTCGGCGAACTCAAGAACTCTGTCCCCAACGCGACCTCGCCCCCTCCTGATGACGTCCACATCTCCCCCGAAGACTTCTTGAAGATAATCGATAACTAG
Protein
MHSVIYRKSDVQHPHENNEGTPCASHLLHVKRTLGNNAELFNFTEHRTSKDATSNDTTEDLRSEIHRRKKRWLPEDEMQDDQPKKNPELPLDLDFPYTSNGDPFDSKLSTRKPKTKIDKSNLITKVRLDSEESRPKPKTHVEVIKSKPGVGVISKDIVKKEPVVYSVLTANASDDGRHVNKRATVDPKKTTCLVYLQADHMFYQRYGSEEACIEVMTRHVQKVNAIYKVTDFNLDGKPDNITFMIKRIKVHTLDALKDPAYRFPNNYGVEKYLELFSEEDYDAFCLAYMFTYRDFEMGTLGLAWTGDLKNAGGVCEKNGHYRGSMKSLNTGIVTLLNYGKHVPPAVSHVTLAHEIGHNFGSPHDPEMCTPFGEDGNYIMFARATSGDRKNNNKFSPCSLKSIDPVLNNKARSPKGCFTEPQPAICGNGVVEEGEECDCGWASECTDVCCRPQAARPLYKPCTLTEHSVCSPSQGPCCTASCTLKFGDKCRSDNGCRDAAHCDGKRAACPSSRHKPNRTRCDKELVCYMGECTGSICLAYGLESCQCSPRSDDPRSACELCCRKPGGQCLSSFHWNTAPYDVPDMYAKPGTPCNDYNGYCDVFQKCREVDPSGPLATLRKLLLSDESIAGFKRWMLRHWYAVLLILLAVIALLVASTRFFGRHGKKLKSVTIIHSSTTETVRLPDAADQGLIVHTAIRSKVPLKKKVALRTRAYRNKKDLKNKQGDKAPLSDGAKKRKPTSQVKHEEPQKVIKETTAIVTSPEGKSPKHVILSKHKNKVKKRKMKLKKETIDYSSMQKHSASPTKDSEALSKVQKWLLSSPQPTVIPKSKSIPLGLTERSHRPTSKGPRKTRPSKSATNLLSGEKARLQVVFKPPFRFSVKICKSDKTKVVLDKSSKPDIERKRHEAAAQHPPADPKLNTFSRTKPHNAARLENTPSNASTGEKTQHQDKGSHGYENLLPRSASDCKLTKQMSDVNLRHKKSNSVGQRKGTTESKQNLICHEDNDSAHLYENVTSPETLAPKSCSMPRRQHGTAIARQSSYGHLPRAQPRPHRRSATSLAAAEPDLDHFYSVIASLRRDGRAHTNTASSSASNRTNTNRPAGRSSRQNSSVEAPTRSNPASPSKLKRQASEAEITKQQCDGGVRGFQLVVGKEKLKRQMSDNELCKSRVQLAMPMSAGAEPRQPFCWNKRASLDCEASLPGAARPAGSRLANKRTYTFGELKNSVPNATSPPPDDVHISPEDFLKIIDN
Summary
Uniprot
EMBL
Proteomes
PRIDE
Interpro
SUPFAM
SSF57552
SSF57552
Gene 3D
ProteinModelPortal
PDB
6BE6
E-value=1.51491e-101,
Score=949
Ontologies
GO
Topology
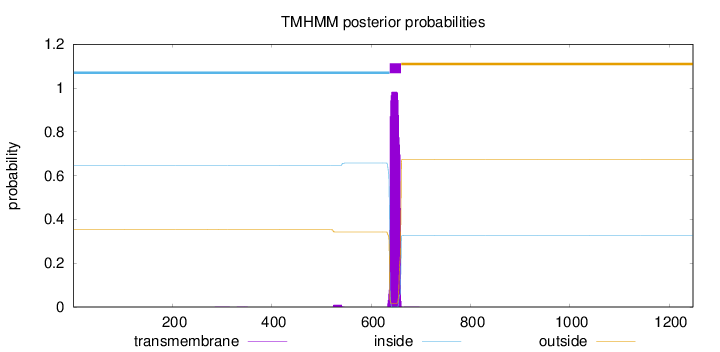
Length:
1248
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
21.80147
Exp number, first 60 AAs:
0
Total prob of N-in:
0.64662
inside
1 - 637
TMhelix
638 - 660
outside
661 - 1248
Population Genetic Test Statistics
Pi
263.287375
Theta
180.937819
Tajima's D
1.214805
CLR
0.145437
CSRT
0.714514274286286
Interpretation
Uncertain
