Gene
KWMTBOMO05237
Pre Gene Modal
BGIBMGA002483
Annotation
PREDICTED:_uncharacterized_protein_LOC101744043_isoform_X2_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 4.102
Sequence
CDS
ATGATAAAGTTTCGGTACAAACGTAAAGAGGCGAGCGATGGTGGAGGAACTAGTGGAACGGCGATACAGAAGCAGAAGATCGAGGGTCTGCGAGACCGGGAACTGTTACCTCCTAAGGACATGCTGTTAGCTGGCTCGCTGGCCGGAGTGAGACATAATACGCTCCCGCGCTCGCGTCCGCCGTCATCCTGCAGACGCGACGCACCCGAACTTCAGCTTATCAGTTCAACGACATTGTCTTTGTTTAGAGAACTATTCTCACAGTTACAATGGTCCGCGGAACGCGCGCCCGCTGCGGACGCACTCCGCCGAGCTTTGGGAGGTGGTGGGGCAAGATTTCAATTAGGCTGCATGGCGGACGCTAGCGAGTGCTTCGAGCATCTCCTGTTGAGGGTCCACGCTCACGTGGCGGCCGCGGGGGACAGGAGAGACGACGATGCCTGCAGAGCCCCACACTGTGTGCCACATCGCAAGTTTGCGATGATGCTCGTTGAGCAATCTGTATGTGGTGCATGCCAGGCTACGTCTGAACCACTGCCCTTCACCCAGATGGTACACTACGTGTCAGCTACAGCTTTGACAGCTCAGGCAGCTTTAGGGGAACATGGAGATAGCTTTGGACTTTTGTTAAAAAAGGCTGGCGGAATGGGTGACATCAGAGATTGTCCTAACGCATGTGGTGCTAAAATACAAATTTGCCGAACTTTGATGAATCGCCCCGAAGTGGTGTCGATCGGGATGGTGTGGGATTCAGAGCGTCCTTCTGCAGAGCATGTTGCCGCCGTATATGCAGCCATCGGCACAGAGCTGCGGCCCACCGACGCATTCCATGCCTGCGTCGATCGGGCTTGGGCCGCCCGAGCCACTCATCATCTCGTTGGAATTGTGACTTATTACGGGAAACACTACTCAACGTTCTTTTTTCATAGCAAATTGCGCCTATGGATATACTTCGACGACGCTGACGTGAAAGAAATTGGCCCGGAGTGGTCTTACGTGGTCGATAAATGTAGAAGAGGAAGATTTCAACCTCTGCTATTACTTTACGCAGCGGTCGATGGAACGCCGTGCGACACCAGGAATGCACCGAAAGATGTCGTGCCGTTCCCCGCGCCAGAACCCAGACGCGCTATTACACCTGCGCCGGAACGCCCCGCTAATGGGTACGCGAGACGAGCTGTCACTCCGGGACCAGACAATGATAGCGATTACATGAATAGAAAGGTCATGGAGAGTGCAAACATTTTAGACGCACAAGCCGCCAGGCGAGCTCCGTTAGTGCGAAGTCTCAGCACGGGCTCCACATCGGACTCTAATGAACGACCTCGGGCTAGAAGAGATTCTGGCAACTGGAGTGGCGATCGTAACAGTGCATCGTCAGCCTCGTCCTCTACAGCAGAAAGCCCGTACATGTACACTAGGGGTCGCGGCCCTGGGAGTGTTCCAAGTAGTCCCACTCGCAAAGGGGAACTCTCAAGTGGTGGTTCATGCGATGCCGGCTATGATTCGTATTCGCTTTCATCGACAGACAGCTTACCGCTTCAGCAGGGACTGCGCCATAACTTGCAACGCGCACAACAAATGCCGGAGATAAAAACACGAGGTGATTGTGAAGCGCTGTGTTCAGAAGCTGATGCGCTTTTAGAGAAAGCGCGTAAAGCCGAAGAGGCGGCGGATTTTGAAACAGCTTTGGTACTCTGTGACGCCGCTATAGCAAAATCCCGCGAGGCCATGGATGCTCCTTACAACAATCCTCACATGATGGCATTCGCACGAATGAAACAGAACACTTGCGTGATGCGGTCTCGTAATCTTCAAAGGAGAATGGGAGGCATGTCCCGAATATCAGAAGCGCAGCAAACGGCTCCCGTGAGGAATACAAAAAGTGGATTGGAAAACTCACCGGTCACCATTGAAATATACGCAACGCTGCCCAAAAAGAAAAACTCGAAGAAATCTCCAAAAAACATAGACGATGACATTGACAATGTGACCCGTGAGCGGCCGCCTCGTCACAAGTCGCGTGACGAGGAGAAAGGTAGAGAAAAACGCTCGAGAAGCGAAGACAGAAGCCGGGCCAGAAAGGAAATAACTGTCACGGCAGAAAAAAAGGAAGAAGTAACCGAAGACAAAAAGACTAATAAAAAGCAACACAAGATTCGAAGAAAGTTATTAATGGGAGGATTGATACGAAGGAAAAACCGATCGATGCCCGATTTAACAGAGGGTGCTGACGGCAACAAAGAAAATTCTAATAAAGAAAAACGTGTCTCCTCCGTTGACGACACTGACGTAGGACGAAAGACGAACGATGATAAATCTCCTTTAAGTGGTTATCTCTCCGAGGGGCACTTGGAGTATTCTGCTGCAAGTGGGACGAACCCTAACTTGGAACGAAGTAAGCTTATGCGCAAGAGTTTTCATGGTAGCGCCGGTAAAATATTGACCGCTGCTAAAGTTCCTCCACCACCACCGGTGCGCACCACATCCCAGCTTAGCGGGACTAAGTACGGATATGTGGATCACAATAATGACAACTACTGCCCCGAAATAGAGGAAGACGGTGGCTTCTCTGAACAATACGGAGATGAACCACAATCTATGCCTTTCCTACATTCCTACGACGATTCACACGTTAATCATTATGATATAATGGAGAGTCCGCAGTCACAAAACTTTCACACTGTTGTCACGAAAGCCATGATCCACCAAGAACAAAGCCCTGTGAAGAGAGACTTCATGCCACCAATACAGCCCTCGCATAACAACATCCAAAACATGAACTTGGCATTTGACAACGGTATGGACGTGGTTGATTGCGCGTTGCCTATGAGTAGATCACCGCCAACATTTGAGCTACCCCCTTATCCCAGTCCCATGAATTCTGTGAGTCATTCACGTCAGCCTAGTGAAGAGTTTCCGCCACCTCCACCGCCGATAGATTTAACACCGCTGCAAGAGGAACTGCAGAAAATACAAAATATAAATGAAGTTTCAAATACAAATGAAACGCAAGCACCGCAGGGCACACTGTTAGCGCAGTTGCAAGAGAAGCGTAACCAAATTCTTAAAAACGAAAATCTGACTAAACCGCATCAAGTGGAAACAGTTAATCACACTGGCGATAGTTTAGTGAGAGAGCTGCAGGCTGCGTTGAAACTTAAAAGATCTGGGTCTCTAGAAGGCCAGCTGTCCAGTCCTTCTGAAAAAACTATCGAGAACAACATCAACGTTAGAAACATTGCGTCCAGATTTGAAAACAACACACAGAACGCACATCCGGATAACGAAAGACCGCATATTTCATTAGCGGGGATGAGCGGAACCCGAGACGTCATAAACTGTTCCGATCAATGTAATATCGGTATTTACAGCAGAAGAGCATCGTCCTCGTCCATTGATGCGAAACAAATGGACCAAGAGATAGCGGATCAGAGACCCGTCCACAATACATATTCCGATCGAAGCAAACCTAAAAAGAAATCGGTCTCTTTCTGTGATCAAGTGATTTTAGTTTCGACCGCTGAAGATCAAGAAGACGATAGCTATATCCCTAATCCGATCTTAGAAAGGGTTTTGAAATCTGCAATGAACAAGCCAGAGCTGACAACGATGCCGTTACAATCGGAAAAGCCCGCATTGCAGCGGCAAGATTCATTCGACAGTCAGTCGTCGCGGTCTACCATATCCTCGCTCTCGCAGAACTCGTTCGTCGGTGCCGATGGAAACCACGCTGAATACGTCCGTCTCCAGAACACTTACCCGACATACCAGACGGCGCAGTCGCGACTCCAACCTCAGTATAACGTGCAGAAAAGTGTTGGAGTGTACGGTACAAGCCCTACAGCACCGCCCAATCAAACGCCAAACGCATTAAACGGCAATCAAATATACCAATCATTGCCGACGAGTGTACCTCAAAACGTTCAGAGCCCGATACCGTACACGCAGCCGCCGCCAGTTTATTCAAACCAGAGTAACGCGAGCCCACCGAACTTTAGTCAAAACCCTGTGAATAGACTGACGCCGACCGCGCAAAACGCCACCTACCCGATAAAACACGCCGCAAACTTGCAACGGAACGTTCCTAACCAATACCCACCAAACCAACGCGCTCAAATTAATCAATTGCCTACGAACGCGTATTACCACAGATTACCCCAAAATTCGACGTCTTCCAATATACCTAACAATAGTCACAATATCAATCGTCAGTATGGCAACACTGTTCCACAAAGCAACACATTACCGTACCAGAGCGTATCGAGCAATACGTCCGCATACCAAAACTACCACAACCCACCGACGAGCTACATCACTGCTGAATATTCTAGTCGATTTCCGCAAACGAACGCGAACCATTATAACCAATCGCCTTATCAAAGGGTTCCGCCGCCGCATGGCGATGTCCCTGTTGACGGTTACAATAACAATACATACCAGAAACTGAATACCAATTATTATGTTGATAATGCGAGTCAACCGCGTGCTGTAGACACGAGGCCGTACCCTCCGGCGCAACGTCCGATGTATAATCAAAACGTTGAAACATCTAACAACGAACAACATGGTCAATTTCAATATACACAAAATAATTATAATAATAATTCGTATCAACACGTGCCAGCCTTGAAGCAATTGCAGAAAAAATCTGTATCGTTTGAGCCCGGCACAAAAGGCGGCACCGATTCACCGGTGCCTCTTCAGTTCAATCCATACCCCTGTGTGGACAACAGTGGAGATAAGACTCCTTGTAATTTGTGCCGTAAAAGAATTGTCACATCTCCCGCCATGTACTGCACGGATTGTGATTACTACATGTCTAGGTTTAAACCTCGTTCGTAG
Protein
MIKFRYKRKEASDGGGTSGTAIQKQKIEGLRDRELLPPKDMLLAGSLAGVRHNTLPRSRPPSSCRRDAPELQLISSTTLSLFRELFSQLQWSAERAPAADALRRALGGGGARFQLGCMADASECFEHLLLRVHAHVAAAGDRRDDDACRAPHCVPHRKFAMMLVEQSVCGACQATSEPLPFTQMVHYVSATALTAQAALGEHGDSFGLLLKKAGGMGDIRDCPNACGAKIQICRTLMNRPEVVSIGMVWDSERPSAEHVAAVYAAIGTELRPTDAFHACVDRAWAARATHHLVGIVTYYGKHYSTFFFHSKLRLWIYFDDADVKEIGPEWSYVVDKCRRGRFQPLLLLYAAVDGTPCDTRNAPKDVVPFPAPEPRRAITPAPERPANGYARRAVTPGPDNDSDYMNRKVMESANILDAQAARRAPLVRSLSTGSTSDSNERPRARRDSGNWSGDRNSASSASSSTAESPYMYTRGRGPGSVPSSPTRKGELSSGGSCDAGYDSYSLSSTDSLPLQQGLRHNLQRAQQMPEIKTRGDCEALCSEADALLEKARKAEEAADFETALVLCDAAIAKSREAMDAPYNNPHMMAFARMKQNTCVMRSRNLQRRMGGMSRISEAQQTAPVRNTKSGLENSPVTIEIYATLPKKKNSKKSPKNIDDDIDNVTRERPPRHKSRDEEKGREKRSRSEDRSRARKEITVTAEKKEEVTEDKKTNKKQHKIRRKLLMGGLIRRKNRSMPDLTEGADGNKENSNKEKRVSSVDDTDVGRKTNDDKSPLSGYLSEGHLEYSAASGTNPNLERSKLMRKSFHGSAGKILTAAKVPPPPPVRTTSQLSGTKYGYVDHNNDNYCPEIEEDGGFSEQYGDEPQSMPFLHSYDDSHVNHYDIMESPQSQNFHTVVTKAMIHQEQSPVKRDFMPPIQPSHNNIQNMNLAFDNGMDVVDCALPMSRSPPTFELPPYPSPMNSVSHSRQPSEEFPPPPPPIDLTPLQEELQKIQNINEVSNTNETQAPQGTLLAQLQEKRNQILKNENLTKPHQVETVNHTGDSLVRELQAALKLKRSGSLEGQLSSPSEKTIENNINVRNIASRFENNTQNAHPDNERPHISLAGMSGTRDVINCSDQCNIGIYSRRASSSSIDAKQMDQEIADQRPVHNTYSDRSKPKKKSVSFCDQVILVSTAEDQEDDSYIPNPILERVLKSAMNKPELTTMPLQSEKPALQRQDSFDSQSSRSTISSLSQNSFVGADGNHAEYVRLQNTYPTYQTAQSRLQPQYNVQKSVGVYGTSPTAPPNQTPNALNGNQIYQSLPTSVPQNVQSPIPYTQPPPVYSNQSNASPPNFSQNPVNRLTPTAQNATYPIKHAANLQRNVPNQYPPNQRAQINQLPTNAYYHRLPQNSTSSNIPNNSHNINRQYGNTVPQSNTLPYQSVSSNTSAYQNYHNPPTSYITAEYSSRFPQTNANHYNQSPYQRVPPPHGDVPVDGYNNNTYQKLNTNYYVDNASQPRAVDTRPYPPAQRPMYNQNVETSNNEQHGQFQYTQNNYNNNSYQHVPALKQLQKKSVSFEPGTKGGTDSPVPLQFNPYPCVDNSGDKTPCNLCRKRIVTSPAMYCTDCDYYMSRFKPRS
Summary
Uniprot
EMBL
Proteomes
PRIDE
Pfam
PF00443 UCH
SUPFAM
SSF54001
SSF54001
ProteinModelPortal
Ontologies
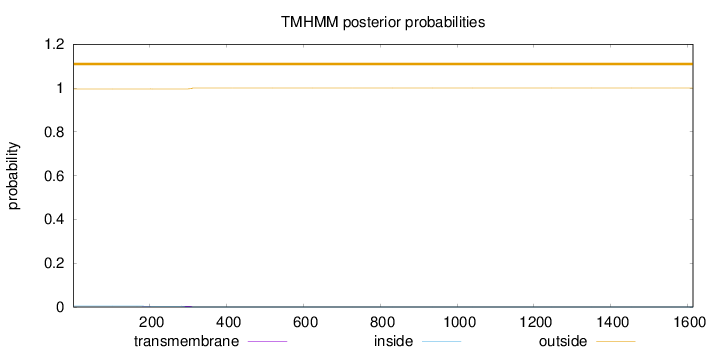
Topology
Length:
1614
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.08422
Exp number, first 60 AAs:
0.00032
Total prob of N-in:
0.00429
outside
1 - 1614
Population Genetic Test Statistics
Pi
202.143981
Theta
177.861101
Tajima's D
0.608512
CLR
0.507422
CSRT
0.545972701364932
Interpretation
Uncertain
