Gene
KWMTBOMO05179 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA012488
Annotation
PREDICTED:_uncharacterized_protein_LOC101740358_isoform_X2_[Bombyx_mori]
Full name
Sushi, von Willebrand factor type A, EGF and pentraxin domain-containing protein 1
+ More
Cubilin
CUB and sushi domain-containing protein 1
CUB and sushi domain-containing protein 3
Probable cubilin
Cubilin
CUB and sushi domain-containing protein 1
CUB and sushi domain-containing protein 3
Probable cubilin
Alternative Name
CCP module-containing protein 22
Polydom
Selectin-like osteoblast-derived protein
Serologically defined breast cancer antigen NY-BR-38
460 kDa receptor
Glycoprotein 280
Intrinsic factor-cobalamin receptor
Intrinsic factor-vitamin B12 receptor
Intestinal intrinsic factor receptor
CUB and sushi multiple domains protein 1
CUB and sushi multiple domains protein 3
Polydom
Selectin-like osteoblast-derived protein
Serologically defined breast cancer antigen NY-BR-38
460 kDa receptor
Glycoprotein 280
Intrinsic factor-cobalamin receptor
Intrinsic factor-vitamin B12 receptor
Intestinal intrinsic factor receptor
CUB and sushi multiple domains protein 1
CUB and sushi multiple domains protein 3
Location in the cell
Extracellular Reliability : 2.992
Sequence
CDS
ATGGTGCCGGCTAGTCCTAGTAATAACCATTACTGGCTCGGGCTTGCCTCAGTTGATGATCTTCGAACGAATACACTTGAATCTGCTGCCGGTGGATTAGTTTCACAATACGCTGGATTCTGGGACTTAAAACAGCCAAACCCAAAAGAAGGCGAATGCGTAGATGTTCTTGTCACATCGGATAGTCAATCTTGGGAGCTAACAACTTGCGAAACATTATTGCCCTTCATGTGCAAAGCCAACGCCTGTCCAGCCGGAACCTTCCATTGTTCTAACGGAAGATGTATCAACGCAGCCTTCAAATGTGACAAACAAGATGATTGCGGTGATGCATCAGACGAAATGGACTGCGCTTCTGAGTGTCACTTTTATATGGCGAGCAGTGGAGATGTAGTGGAATCCCCTAATTATCCACACAAATATCCATCATTTAGCGAATGCAAATGGACTCTTGAAGGGCCTCAAGGACAAAATATTCTTTTACAATTCCAAGAGTTTGAAACAGAAAAATCCTTTGATACAGTCCAAATTCTTGTCGGCGATGGTTCTGTAGAAAAGAAGGGATTCAGGGCATCATGGAAAACAGAATCTTCTAATTGTGGTGGTGTCCTTCGAGCTACACCTCAAGGCCAAGTTTTGACGTCACCGGGCTATCCAAATGGGTACCCAGGTGGCTTAGAATGCATGTATATAATCGAAGCCCAACCGGGCCGAATTGTTTCATTAGAGATTGAAGATTTAGAACTAGGAATGAACAGAGATTACATCGTTGTAAAAGACGGTAATACCCCTTCCAGTCCAGTGTTGGCCAGATTGACGGGTCCTGGTGAAGACAATGAAAAAGTTGTGATTTCGACAACAAATCATCTTTACTTGTACTTTAGAACAAGCCTGGGAGATTCTAAAAAGGGATTTAATATGCGATATTCGCAAGGCTGCAAGGCTACCATTATTGCGGCTAATGGTACATTCACATCTCCGGCATACGGTCTAACAAATTATCCCAACAACCAGGAATGTCTCTACAGAATTAAGAATCCTACCGGAGGTCCGCTTTCGTTGAAGTTTGATGAATTTAATATTCATTCTTCTGATGTAGTACAAGTTTTCGACGGCTCGAGTACAAATGGACTCAGGTTACATTCTGAAAATGGATTTACTATAAAACCTAGAATAACTTTGACTGCTTCCAGTGGTGAAATGTTAATACGATTCGTATCTGATGCATTGCATAATGGAAAAGGATGGAAGGCGACGTTTTCTGCAGATTGCCCACCACTAAAATCTGGCATAGGAGCACTAGCATCAAATAGAGATACTGCTTTCGGAACAGTCATAACGTTCTCTTGTCCAATTGGTCAGGAATTTGCTACAGGAAAACCCAGACTTACAACTAAATGCTTGGACGGTGGAAATTGGTCAACGATGTACATACCTAGCTGTCAAGAGGTATATTGTGGTCCAGTGCCGCAAATTGACAATGGTTTTTCAATCGGTTCCACAAACGTGACATATCGTGGTGTTGCCACTTATCAATGTTATGCAGGTTTTGCTTTTCCAACTGGTCAACCAATTGAAAGAATATCATGTTTATCCGACGGACGATGGGAACGAACCCCCACTTGTTTGGCTTCTCAGTGCGTAGCCTTGCCTGACGTACCGCACGCGAATGTAACGATTCTTAACGGTGGCGGTCGTAGCTACGGTACAATCGTCCGTTACGAATGCGAACCAGGCTATGTTAGATCTGGTCAACCAGTACTTCTCTGTATGAGCAACGGCACGTGGTCTGGAGACGTACCAACCTGTACAAAAACCATATGTTCTAAATTTCCCGAAATAAAAAACGGTTATATCGTAGATCAGAGCAGAACTTACATGTTTGGCGACGAAGCACGCGCGCAGTGTTTTAAAGGTTACAAATTAAATGGACCTAGCATACTAAGATGTGGGGCAAACCAAGAATTTGATCAAGCACCAACATGTGAAGATATAAATGAGTGCTTGAGTTCGCAATGCGACTCAGTCTCAACTGAATGTAAAAACACTCAAGGAGGATTCTTCTGTCCCTGTCGAACTGGTTTTGCACCCAGCTTAGATTGTAGACCTGTTGGCGATTTAGGACTTATAAACGGAGCAATCCCTGACGAGTCAATCTCGACATCAACACCAGAACCAGGATATAACAGTGGTATGGTGCGCCTTAACAACGGAGGTGGATGGTGTGGTAACAATCTCGAAGCCGGCGCGAATTGGATTTTAATCGATTTGAGAGCTCCAACAATTGTCCGAGGATTTAGAACGATGAGTGTAATGCGAGCTGATGGCAATATTGCATTTACTTCTGCCATACGCATACAGTACACAAATGATCTTACCGATGTTTTCAAAGATTACACTAATCCTGACGGGACTGCTGTAGAATTCCGTATTTTAGAACCAACTCTATCTGTACTTAATCTCCCAGTACCTATAGAAGCACAATACGTCAAGTTCAAAATTCAAGATTATGTTGGAGCACCATGTTTGAAATTAGAAGTTATGGGATGTGCGAGATTAGACTGTTTAGATATTAATGAATGCAGCGAAAACAACGGAGGATGTGAGCAAAAGTGCTTAAACACGCCCGGCAACTTTTCATGCGCGTGTAATCTTGGATTTGAATTATATTCTTCCAATGGAACAGCAGGTTTCTCAATTGAACTATCTGAAACCGGTGAAAGAGACGGAGATACATATCAAAGGAATAAATCTTGCGTACCGGTCATGTGCCCCCCACTTGCACCACCTGAAAACGGACAACTTTTATCGACAAAAAAATCTTATCACTTCGGTGATACAGTTCATTTCCAATGTGACTTTGGATATGTAATGTCAGGATTTTCGACATTACAATGCACCTCAAGTGGAACTTGGAATGGAACTGCTCCTGAATGTCAATATGCTCGATGTGTAACTTTATCTGACGACAAAAACGATGGCTTAAGAGTCATAAGGGATGATCCTGAAAGTGTTTTAGTACCATACAGAGACAATGTTACAATAACCTGCACTTCTCCTGGGAGACACCTGAGAAATACTCTCACATCTTCTTTTAGACAGTGTGTTTACGATCCTAAGCCTGGTCTTCCTGATTATTGGTTTTCTGGGGCACAACCACAATGTCCAAGACAAGACTGCGGTATCCCAATGCCAACACCTGGTGCAGAATATGGGCAATATCTTGATACTAAATATCAAAGCTCCTTTTTCTTTGGTTGCCAAAACACTTTCAAACTTGCTGGGCAGACAAGTAAACACGATAACGTTGTAAGATGTCAGGCAAATGGCATATGGGACTTCGGAGATTTGAGATGCGAAGGACCAGTTTGTGAAGACCCAGGTAGACCTGCTGACGGCTACCAAATTGCAAGAAGCTATGAACAAGGATCTGAAGTGCTATTCGGTTGTTCAAGACCTGGCTATATCCTAATAAATCCGAGACCTATAACATGCATGCGTGAACCGGAATGTAAAGTTATCAAACCTCTGGGTCTTGCTTCGGGTAGAATACCCGACTCCGCTATCAATGCTACATCAGAAAGACCTAACTATGAAGCTAAAAATATTCGACTCAATTCGGTTACGGGTTGGTGTGGTAAGCAAGAAGCTTTTACGTATGTGAGTGTAGATCTTGGTAAAGTTTACAGAGTCAAAGCTATCCTTGTAAAGGGTGTAGTAACCTCCGATATTGTGGGACGTCCTACTGAAATAAGATTTTTCTACAAACAAGCCGAAAACGAAAACTATGTTGTGTATTTCCCGAATTTCAATTTAACCATGAGGGATCCCGGAAACTATGGAGAACTAGCAATGATTACATTGCCAAAATTTGTCCAAGCAAGGTTTGTAATTTTGGGCATAGTCAGTTTCATGGACAACGCTTGTCTCAAATTTGAAGTAATGGGATGTGAAGAACCAAGCACAGAACCCTTATTGGGTTACGACTATGGTTATTCTCCTTGTGTCGATAATGAACCACCAGTGTTCCAGAACTGCCCTCAACAACCGATTGTAGTCCAAACCGATGTTAATGGTGGCTTACTTGCTGTAAACTTCACTGAACCTACTGCAATTGACAATTCTGGTGCAATAGCTCGATTAGAAGTTACACCCCAGCATTTTAAAACACCAATTCAAGTATTCCATAATATGGTAGTTCGATATGTGGCTTTCGATTTTGATGGAAATGTTGCAATTTGTGAAGTAAACATTACTGTACCTGATTACACCCCTCCTAAATTAAGCTGCCCTCAAAGCTATGTTATAGAACTGGTGGATAAACAAGACAGTTACGCTGTTAATTTCAACGAAACGAGAAGAAGAATCAACGCAACTGATTCATCCGGAGAAGTTTACTTGAAGTTCATTCCTGAAAGAGCAGTTATTCCCATTCGAGGATACGAAAACGTCACAGTTATCGCCTCAGACAAATATGGCAACAAAGCTCAATGTCACTTCCAAGTATCAGTGCAAGCTACTCCGTGCGTAGATTGGGAACTAATGCCTCCAGCAAACGGCGCAATGAATTGTATTCCGGGTGACAGGGGTATACAGTGTATAGCCACTTGCAGTCCAGGTTTTAGATTCACAGATGGAGAGCCTGTCAAGACTTTTGTCTGCGAAACGAAACGTCAATGGGTCCCATCTGCTGTTGTTCCAGATTGCGTTTCTGAAAACACTCAACAAGCTGCTTATCACGTCGTAGCCGGTGTACAGTACAGAGCTCTGGGTGCAGTTTCAAGTGCTTGTTTACCTCAATACAAAGATCTACTAGCACAATATGATAACATTCTAAACGAAAGGCTGTCACAACGTTGCTCAGCAGTTAATGTTAACATTAACGTAACTTTCGTTAAAGCTATGCCAAGTTTATTAGATGAAAATGTGGTCAAAATGGACTTTGTCTTGGCCATTACACCAGCCATTAGACAAACTCAGCTATATGATTTGTGTGGCTCAACACTAAATCTCATCTTTGATCTGTCTGTTCCATACGCAAGTGCACTTATTGAACCAGTACTAAATGTTTCATCCATCGGAAATCAATGTCCACCACTGAGAGCCATCAGAAGCTCAATAACAAGAGGATTTACTTGCAGTGTTGGAGAAGTATTAAATATGGATACAAACGACGTACCTAGATGTCTACATTGTCCTGCTGGTACTTCCGCTGGAGAAAAGCAAAAGACGTGCACAATGTGTCCACTAGGATATTTCCAGAATCAAGCACGTCAAGGTTCGTGTTTGAAATGTCCTCAAGGTACATTTACTCGAGAAGAAGGCTCAAAAGATATTTCTGATTGCATACCGGTCTGCGGTTACGGTACATACTCACCAACTGGACTGGTTCCTTGCTTAGAGTGTCCCAGAAACAGTTACACTGCCGAACCTCCAGTCGGAGGCTTCAAAGACTGTCAAGCATGTCCGATAAACACATTTACCTATCAACCAGCAGCGCCAGGTCGTGACAAGTGTAGAGCAAAGTGTGCTCCAGGAACAGGTGCAACAGGATTAGAAGAATGCATCCCTGTTGAATGTTCGAACAGCGCTTGCCAGCATGGAGGTCTATGTGTGCCGAAAGGACACGGTGTCCAATGCTACTGCCCAGCTGGATTTTCTGGACGCAGATGTGAAGTTGATATCGATGAATGTGCCAGTCAACCCTGTTACAACGGCGGTACCTGTACTGATTTGCCTCAAGGATACAGGTGCTCGTGTCCCACTGGTTACGGTGGAGTTAACTGTCAAGAAGAAAAATCTGATTGTAGAAATGATACGTGCCCAGAACGAGCTATGTGCAAAGACGAACCTGGATTCGATAACTATACTTGTTTGTGTAGATCTGGATATACTGGAATTGATTGTGATATCACAATCGATCCATGCACTGCTAACGGAAATCCTTGCTCAAACGGTGCTAGTTGTATTGCATTACAACAAGGGCGCTTCAAGTGTGAGTGCTTACCAGGATGGGAAGGACAACTTTGTGACATTAATACAGATGATTGTATCGAAAAGCCTTGTCTTCTTGGTGCACCTTGTACGGACTTAGTTAATGACTTTAGCTGCTCATGTCCACCAGGATTCACGGGAAAACGTTGTCATGAAAAAATAGATCTCTGCTCAAGCGAACCATGCAAACATGGAATATGTGTAGATAAACTCTTCGTTCATCAATGTATATGTGACCCTGGTTGGTCAGGACCATCGTGTGATATTAACATTAATGAATGTGTGATATCACCATGTGAGAACGGAGGTCAATGTATGGACGGTATCGACGATTTCAATTGCGTATGTGAAACTGGTTTTACAGGAAAGAAATGTCAACACACCATCGATGATTGTTTATCAAATCCTTGTCAAAACGGTGCAACATGTATGGATCAAATCGAAGGATTTGTTTGCAAATGCCGACCTGGATTCGTAGGTCTTCAATGCGAAACGGCCATTGATGAATGTTTGACCGAGCCATGCAACCCTACGGGAACCGAACGCTGTATAGATTTAGACAACAAATACCAATGCGTCTGTCGTGAAGGTTTCACAGGAAAAATGTGTGAAACAAACGTTGATGACTGCGCTTCAAATCCTTGCTTTAATGGTGGATCGTGCACAGACGAAGTCGGCGGATACAAATGCGCCTGTCATCCAGGATGGACTGGCAAGAGATGCGAAAAAGACATCGGTAATTGCGTAAACCAACCCTGCCAAAATCATGCTAAATGTATTGACCTATTCCAAGATTATTTCTGTGTGTGTCCTAGTGGAACTGATGGAAAACAATGTGAAACGGCCCCGGAAAGATGTATTGGAAGCCCATGTATGCACGGCGGAAAGTGTCAAGACTTTGGATCAGGCCTTAATTGCACATGTTCATCTGATTACACTGGCATTGGCTGTCAATATGAATTTGATGCCTGCGAAGCTGGTTTGTGCCAAAATGGAGCAACGTGCATCGACGAAGGCGAAGGATACCGTTGTATTTGCGCTCCTGGATTTAAAGGACAAAATTGCGACGAAGACATTATCGATTGTAAAGAAAACTCTTGTCCACCTTCGGCAACATGCATTGACCTTCCAGGGAGATTCTACTGTCAATGTCCATTTAATCTAACGGGAGATGACTGTAGAAAAACAATCAGTGTTGATTACGATATGTACTTCAGTGATCCCTTAAGGTCAAGCGCAGCCCAAGTGGTACCGTTTGATACCAATTCAGCAGATAGCTTAACTATAGCCATGTGGGTACAATACACACAACAAGACGAAGGCGGTGTCTTCTTCACAGCATATAGCGTAAGCAATTCCCACATTGCGCTTAACAGAAGACAAGTCATACAAGCACATTCAAATGGAGTTCAGGTGTCTCTATTCTCTGAACTACAAGATGTATACCTCAGTTTCGGAGAATTCGCTACGGTCAACGATGGACAATGGCACCATGTTGCGTTGGTGTGGGATGGTAGCAATGGCGGCGAACTCACATTAATCACTGAAGGACTGATTGCCAGCAAACTCGCTGGTTATGGCAGCGGTCGAACCTTGCCACGATACATCTGGGTAACATTGGGTAAGCCGCAGTCCGATAATCCAAAGGCGTATACCGAAGCCGGATTCCAAGGACATCTTACCAAGGTACAAGTCTGGAATCGAGCACTAGACGTCACTAATGAAGTTCAAAAACAAGTCCGTGACTGCAGAACGGAGCCTGTCCTTTACAGTGGTTTAACTTTGACCTGGGCTGGATATGATGACATAATTGGTGGAGTAGAACGAATCGTACCATCACATTGTGGACAAAGGGTTTGCCCTAATGGCTACAATGGTCAAAAATGTCAACAATTAGAAGTCGATAAAGAACCACCAAGAGTAGATAGATGCCCTGGTGACTTATGGGTGATTGCTAAGAATGGATCATCTATTGTCAACTGGGATGCACCTGTATTTAGCGACAATGTTGGAGTGGCAAAAGTAGTAGAAAAATCTGGACATAAGCCAGGAGAGAACCTTGCTTGGGGAGCATATGACATAGCCTACATTGCATATGACGCCGTGGGTAATGCAGCGACATGCACATTTAAGATTACAGTATTATCGGAATTCTGTCCACCTTTACCGGATCCTCTGGGTGGTTATCAATCTTGTCGCGATTGGGGCGCAGGAGGTCAATTCAAGGTCTGCGAGATTGCTTGTCGCGATGGCTTGCGATTCTCACAGCCCGTACCTCCGTTCTTTACATGCGGCGCAGAAGGCTTTTGGAGACCAACAACTGATCCAAGTTTGCCACTAATATATCCTGCTTGCTCACCTGCTTCACCTGCTCAACGTGTCTTCAAAGTATCTATGTTGTTCCCGAGTTCTGTTCTCTGCAACGACGCTGGCCAAGCCGTACTTCGACAAAAAGTACGCAGCGCTATCAATCAACTCAATAGAGATTGGAACTTCTGCTCTTACGCAATTGATGGTACTCGAGAATGCAAAGAATTGGATATTAATGTGAAATGCGATCACCGCGCCAACAGGCAGACTAGACAAGTGTCGTCCCCTCCCACAGTAACAGCTGAAGATACCTATGTTTTGGACGCTATAATTCCTGTCGAAGAGACACGAAGCAGTAGGGAGGGTCGACAAATTGGCGATACGTACAGCGTTGAAATATCTTTCCCGGCTGTCAACGACCCAGTAATCCACGGCGGTAATAACGAAAGATCGACTGTGCAACGATTACTGGAGAAATTAATTCTCGAAGACGAACAATTCGACGTTAGGAATATCCTTCCGAATACCGTACCTGATCCCGCGAGCTTGGTGCTTGCTTCTGATTACGCCTGCCCTACTGGACAGGTCGTAATGGCTCCTGACTGTGTGGCATGCGCTGTCGGTACCTTCTTAGATTCGGCCACCGACTCGTGCAAGCCGTGCCCCATGGGAAGCTACCAATCAGAAGCTGGACAATTACAGTGTATCTCCTGCCCAACGATAGCTGGCCAACCTGGAGTTACCCAAACAACAGGAGCTCGAAGCGCTGCTGACTGTAAAGAGAAGTGTGCCGCTGGTAAATACTTTGACGCTGAGGCGGAACTTTGCCGTCCATGCGGTCACGGTTCCTATCAACCAAGAGAGGGCGCCTTCTCCTGTATCTCCTGTCCCAGAGGTCAAACCACTCGAGCCACAGAAGCGGTATCTGCTGCCGAATGCAGAGACGATTGTCCTTCAGGAGAACAGTTAGGCACTGATGGAGGTTGTGAACCTTGTCCTCGAGGTACATGGCGCGCGACAGGCGCGGGAGCCGCGTGCGCGCCGTGCCCTCCTGGGACTACCACACCGCAAACAGGCGCTTCCTCTGCAGATCAATGTTCTTTGCCCGTTTGTAGACCTGGGTCATACCTCAACGTGACACTGAACACGTGCATTCAATGCAGAAAGGGTACCTACCAGTCGGAAGCACAACAGACAATATGCGTACCTTGTCCTATAAACACGAGTACCAGAGGACCGGGCGCGACCTCAGAGTCAGACTGCACAAATCCTTGCGAGATGAGCGGTCCTGAGATGCACTGCGATGTCAATGCATACTGCCTTTTGATGCCGGAGACAAGCGAATTCAAATGTCAGTGCAAACCTGGATTCAACGGCACTGGAAAAGTTTGCATAGACGTGTGCCTTGACTACTGCGACAATGGAGGCGAATGCATAAAGGACGCTAGAGGCGAACCTTCGTGCAGATGCACGGGTTCGTTCACCGGAAGACACTGCAGGGACAAGAGCGAGTTCGCATACATTGCGAGCGGTGTCGCCGGTGGAGTCATCTTTATTATATTCTTGGTCCTGCTTGTATGGATGATTTGCGCCAGGTCAACCAAGAGGAAAGAACCAAAGAAGACACTCACCCCAGCTATCGACCAAAACGGTTCCCAAGTGAACTTCTACTACGGAGCTCACACACCTTACGCGGAATCAATAGCGCCCTCGCATCATTCAACATACGCTCATTACTACGACGACGAGGAAGACGGCTGGGAGATGCCGAACTTTTACAACGAGACTTACATGAAGGAGAGTTTGCATAATGGTATGAATGGTAAAATGAACAGCTTGGCGAGGTCAAACGCCAGCATCTATGGAACGAAGGAGGATCTTTACGATAGGTTGAAGAGACACGCGTACCCGGAGAAGAGTGATAGCGACAGTGAAGGTCAATAG
Protein
MVPASPSNNHYWLGLASVDDLRTNTLESAAGGLVSQYAGFWDLKQPNPKEGECVDVLVTSDSQSWELTTCETLLPFMCKANACPAGTFHCSNGRCINAAFKCDKQDDCGDASDEMDCASECHFYMASSGDVVESPNYPHKYPSFSECKWTLEGPQGQNILLQFQEFETEKSFDTVQILVGDGSVEKKGFRASWKTESSNCGGVLRATPQGQVLTSPGYPNGYPGGLECMYIIEAQPGRIVSLEIEDLELGMNRDYIVVKDGNTPSSPVLARLTGPGEDNEKVVISTTNHLYLYFRTSLGDSKKGFNMRYSQGCKATIIAANGTFTSPAYGLTNYPNNQECLYRIKNPTGGPLSLKFDEFNIHSSDVVQVFDGSSTNGLRLHSENGFTIKPRITLTASSGEMLIRFVSDALHNGKGWKATFSADCPPLKSGIGALASNRDTAFGTVITFSCPIGQEFATGKPRLTTKCLDGGNWSTMYIPSCQEVYCGPVPQIDNGFSIGSTNVTYRGVATYQCYAGFAFPTGQPIERISCLSDGRWERTPTCLASQCVALPDVPHANVTILNGGGRSYGTIVRYECEPGYVRSGQPVLLCMSNGTWSGDVPTCTKTICSKFPEIKNGYIVDQSRTYMFGDEARAQCFKGYKLNGPSILRCGANQEFDQAPTCEDINECLSSQCDSVSTECKNTQGGFFCPCRTGFAPSLDCRPVGDLGLINGAIPDESISTSTPEPGYNSGMVRLNNGGGWCGNNLEAGANWILIDLRAPTIVRGFRTMSVMRADGNIAFTSAIRIQYTNDLTDVFKDYTNPDGTAVEFRILEPTLSVLNLPVPIEAQYVKFKIQDYVGAPCLKLEVMGCARLDCLDINECSENNGGCEQKCLNTPGNFSCACNLGFELYSSNGTAGFSIELSETGERDGDTYQRNKSCVPVMCPPLAPPENGQLLSTKKSYHFGDTVHFQCDFGYVMSGFSTLQCTSSGTWNGTAPECQYARCVTLSDDKNDGLRVIRDDPESVLVPYRDNVTITCTSPGRHLRNTLTSSFRQCVYDPKPGLPDYWFSGAQPQCPRQDCGIPMPTPGAEYGQYLDTKYQSSFFFGCQNTFKLAGQTSKHDNVVRCQANGIWDFGDLRCEGPVCEDPGRPADGYQIARSYEQGSEVLFGCSRPGYILINPRPITCMREPECKVIKPLGLASGRIPDSAINATSERPNYEAKNIRLNSVTGWCGKQEAFTYVSVDLGKVYRVKAILVKGVVTSDIVGRPTEIRFFYKQAENENYVVYFPNFNLTMRDPGNYGELAMITLPKFVQARFVILGIVSFMDNACLKFEVMGCEEPSTEPLLGYDYGYSPCVDNEPPVFQNCPQQPIVVQTDVNGGLLAVNFTEPTAIDNSGAIARLEVTPQHFKTPIQVFHNMVVRYVAFDFDGNVAICEVNITVPDYTPPKLSCPQSYVIELVDKQDSYAVNFNETRRRINATDSSGEVYLKFIPERAVIPIRGYENVTVIASDKYGNKAQCHFQVSVQATPCVDWELMPPANGAMNCIPGDRGIQCIATCSPGFRFTDGEPVKTFVCETKRQWVPSAVVPDCVSENTQQAAYHVVAGVQYRALGAVSSACLPQYKDLLAQYDNILNERLSQRCSAVNVNINVTFVKAMPSLLDENVVKMDFVLAITPAIRQTQLYDLCGSTLNLIFDLSVPYASALIEPVLNVSSIGNQCPPLRAIRSSITRGFTCSVGEVLNMDTNDVPRCLHCPAGTSAGEKQKTCTMCPLGYFQNQARQGSCLKCPQGTFTREEGSKDISDCIPVCGYGTYSPTGLVPCLECPRNSYTAEPPVGGFKDCQACPINTFTYQPAAPGRDKCRAKCAPGTGATGLEECIPVECSNSACQHGGLCVPKGHGVQCYCPAGFSGRRCEVDIDECASQPCYNGGTCTDLPQGYRCSCPTGYGGVNCQEEKSDCRNDTCPERAMCKDEPGFDNYTCLCRSGYTGIDCDITIDPCTANGNPCSNGASCIALQQGRFKCECLPGWEGQLCDINTDDCIEKPCLLGAPCTDLVNDFSCSCPPGFTGKRCHEKIDLCSSEPCKHGICVDKLFVHQCICDPGWSGPSCDININECVISPCENGGQCMDGIDDFNCVCETGFTGKKCQHTIDDCLSNPCQNGATCMDQIEGFVCKCRPGFVGLQCETAIDECLTEPCNPTGTERCIDLDNKYQCVCREGFTGKMCETNVDDCASNPCFNGGSCTDEVGGYKCACHPGWTGKRCEKDIGNCVNQPCQNHAKCIDLFQDYFCVCPSGTDGKQCETAPERCIGSPCMHGGKCQDFGSGLNCTCSSDYTGIGCQYEFDACEAGLCQNGATCIDEGEGYRCICAPGFKGQNCDEDIIDCKENSCPPSATCIDLPGRFYCQCPFNLTGDDCRKTISVDYDMYFSDPLRSSAAQVVPFDTNSADSLTIAMWVQYTQQDEGGVFFTAYSVSNSHIALNRRQVIQAHSNGVQVSLFSELQDVYLSFGEFATVNDGQWHHVALVWDGSNGGELTLITEGLIASKLAGYGSGRTLPRYIWVTLGKPQSDNPKAYTEAGFQGHLTKVQVWNRALDVTNEVQKQVRDCRTEPVLYSGLTLTWAGYDDIIGGVERIVPSHCGQRVCPNGYNGQKCQQLEVDKEPPRVDRCPGDLWVIAKNGSSIVNWDAPVFSDNVGVAKVVEKSGHKPGENLAWGAYDIAYIAYDAVGNAATCTFKITVLSEFCPPLPDPLGGYQSCRDWGAGGQFKVCEIACRDGLRFSQPVPPFFTCGAEGFWRPTTDPSLPLIYPACSPASPAQRVFKVSMLFPSSVLCNDAGQAVLRQKVRSAINQLNRDWNFCSYAIDGTRECKELDINVKCDHRANRQTRQVSSPPTVTAEDTYVLDAIIPVEETRSSREGRQIGDTYSVEISFPAVNDPVIHGGNNERSTVQRLLEKLILEDEQFDVRNILPNTVPDPASLVLASDYACPTGQVVMAPDCVACAVGTFLDSATDSCKPCPMGSYQSEAGQLQCISCPTIAGQPGVTQTTGARSAADCKEKCAAGKYFDAEAELCRPCGHGSYQPREGAFSCISCPRGQTTRATEAVSAAECRDDCPSGEQLGTDGGCEPCPRGTWRATGAGAACAPCPPGTTTPQTGASSADQCSLPVCRPGSYLNVTLNTCIQCRKGTYQSEAQQTICVPCPINTSTRGPGATSESDCTNPCEMSGPEMHCDVNAYCLLMPETSEFKCQCKPGFNGTGKVCIDVCLDYCDNGGECIKDARGEPSCRCTGSFTGRHCRDKSEFAYIASGVAGGVIFIIFLVLLVWMICARSTKRKEPKKTLTPAIDQNGSQVNFYYGAHTPYAESIAPSHHSTYAHYYDDEEDGWEMPNFYNETYMKESLHNGMNGKMNSLARSNASIYGTKEDLYDRLKRHAYPEKSDSDSEGQ
Summary
Description
May play a role in the cell attachment process.
Cotransporter which plays a role in lipoprotein, vitamin and iron metabolism, by facilitating their uptake. Binds to ALB, MB, Kappa and lambda-light chains, TF, hemoglobin, GC, SCGB1A1, APOA1, high density lipoprotein, and the CBLIF-cobalamin complex. The binding of all ligands requires calcium. Serves as important transporter in several absorptive epithelia, including intestine, renal proximal tubules and embryonic yolk sac. Interaction with LRP2 mediates its trafficking throughout vesicles and facilitates the uptake of specific ligands like GC, hemoglobin, ALB, TF and SCGB1A1. Interaction with AMN controls its trafficking to the plasma membrane and facilitates endocytosis of ligands. May play an important role in the development of the peri-implantation embryo through internalization of APOA1 and cholesterol. Binds to LGALS3 at the maternal-fetal interface.
Cotransporter which plays a role in lipoprotein, vitamin and iron metabolism, by facilitating their uptake. Binds to ALB, MB, Kappa and lambda-light chains, TF, hemoglobin, GC, SCGB1A1, APOA1, high density lipoprotein, and the CBLIF-cobalamin complex. The binding of all ligands requires calcium. Serves as important transporter in several absorptive epithelia, including intestine, renal proximal tubules and embryonic yolk sac. Interaction with LRP2 mediates its trafficking throughout vesicles and facilitates the uptake of specific ligands like GC, hemoglobin, ALB, TF and SCGB1A1. Interaction with AMN controls its trafficking to the plasma membrane and facilitates endocytosis of ligands. May play an important role in the development of the peri-implantation embryo through internalization of APOA1 and cholesterol. Binds to LGALS3 at the maternal-fetal interface (By similarity).
Involved in dendrite development.
Cotransporter which plays a role in lipoprotein, vitamin and iron metabolism, by facilitating their uptake.
Cotransporter which plays a role in lipoprotein, vitamin and iron metabolism, by facilitating their uptake. Binds to ALB, MB, Kappa and lambda-light chains, TF, hemoglobin, GC, SCGB1A1, APOA1, high density lipoprotein, and the CBLIF-cobalamin complex. The binding of all ligands requires calcium. Serves as important transporter in several absorptive epithelia, including intestine, renal proximal tubules and embryonic yolk sac. Interaction with LRP2 mediates its trafficking throughout vesicles and facilitates the uptake of specific ligands like GC, hemoglobin, ALB, TF and SCGB1A1. Interaction with AMN controls its trafficking to the plasma membrane and facilitates endocytosis of ligands. May play an important role in the development of the peri-implantation embryo through internalization of APOA1 and cholesterol. Binds to LGALS3 at the maternal-fetal interface.
Cotransporter which plays a role in lipoprotein, vitamin and iron metabolism, by facilitating their uptake. Binds to ALB, MB, Kappa and lambda-light chains, TF, hemoglobin, GC, SCGB1A1, APOA1, high density lipoprotein, and the CBLIF-cobalamin complex. The binding of all ligands requires calcium. Serves as important transporter in several absorptive epithelia, including intestine, renal proximal tubules and embryonic yolk sac. Interaction with LRP2 mediates its trafficking throughout vesicles and facilitates the uptake of specific ligands like GC, hemoglobin, ALB, TF and SCGB1A1. Interaction with AMN controls its trafficking to the plasma membrane and facilitates endocytosis of ligands. May play an important role in the development of the peri-implantation embryo through internalization of APOA1 and cholesterol. Binds to LGALS3 at the maternal-fetal interface (By similarity).
Involved in dendrite development.
Cotransporter which plays a role in lipoprotein, vitamin and iron metabolism, by facilitating their uptake.
Subunit
Component of the cubam complex composed of CUBN and AMN (By similarity). The cubam complex can oligomerize and form cubam trimers. Interacts with LRP2 in a dual-receptor complex in a calcium-dependent manner. Found in a complex with PID1/PCLI1, LRP1 and CUBNI (By similarity). Interacts with LRP1 and PID1/PCLI1 (By similarity).
Interacts with LRP2 in a dual-receptor complex in a calcium-dependent manner (By similarity). Component of the cubam complex composed of CUBN and AMN. The cubam complex can oligomerize and form cubam trimers. Found in a complex with PID1/PCLI1, LRP1 and CUBNI (By similarity). Interacts with LRP1 and PID1/PCLI1 (By similarity).
Interacts with LRP2 in a dual-receptor complex in a calcium-dependent manner. Component of the cubam complex composed of CUBN and AMN. The cubam complex can oligomerize and form cubam trimers. Found in a complex with PID1/PCLI1, LRP1 and CUBNI. Interacts with LRP1 and PID1/PCLI1 (By similarity).
Interacts with LRP2 in a dual-receptor complex in a calcium-dependent manner. Component of the cubam complex composed of CUBN and AMN. The cubam complex can oligomerize and form cubam trimers. Found in a complex with PID1/PCLI1, LRP1 and CUBNI. Interacts with LRP1 and PID1/PCLI1.
Interacts with LRP2 in a dual-receptor complex in a calcium-dependent manner (By similarity). Component of the cubam complex composed of CUBN and AMN. The cubam complex can oligomerize and form cubam trimers. Found in a complex with PID1/PCLI1, LRP1 and CUBNI (By similarity). Interacts with LRP1 and PID1/PCLI1 (By similarity).
Interacts with LRP2 in a dual-receptor complex in a calcium-dependent manner. Component of the cubam complex composed of CUBN and AMN. The cubam complex can oligomerize and form cubam trimers. Found in a complex with PID1/PCLI1, LRP1 and CUBNI. Interacts with LRP1 and PID1/PCLI1 (By similarity).
Interacts with LRP2 in a dual-receptor complex in a calcium-dependent manner. Component of the cubam complex composed of CUBN and AMN. The cubam complex can oligomerize and form cubam trimers. Found in a complex with PID1/PCLI1, LRP1 and CUBNI. Interacts with LRP1 and PID1/PCLI1.
Miscellaneous
CSMD1 may be a candidate for oral and oropharyngeal squamous cell carcinomas (OSCCs). PubMed:12696061 and PubMed:14506705 are however in disagreement: while PubMed:14506705 considers CSMD1 as a strong candidate for OSCCs, PubMed:12696061 thinks it is not.
Similarity
Belongs to the CSMD family.
Keywords
Alternative splicing
Calcium
Cell adhesion
Complete proteome
Cytoplasm
Disulfide bond
EGF-like domain
Glycoprotein
Membrane
Polymorphism
Reference proteome
Repeat
Secreted
Signal
Sushi
Cholesterol metabolism
Cleavage on pair of basic residues
Cobalamin
Cobalt
Direct protein sequencing
Endosome
Lipid metabolism
Lysosome
Metal-binding
Phosphoprotein
Protein transport
Steroid metabolism
Sterol metabolism
Transport
Cell membrane
Coated pit
3D-structure
Disease mutation
Endocytosis
Receptor
Transmembrane
Transmembrane helix
Feature
chain Sushi, von Willebrand factor type A, EGF and pentraxin domain-containing protein 1
splice variant In isoform 3.
sequence variant In dbSNP:rs3818764.
propeptide Removed in mature form
splice variant In isoform 3.
sequence variant In dbSNP:rs3818764.
propeptide Removed in mature form
Uniprot
Pubmed
16206243
14702039
15164053
15489334
17974005
12747765
+ More
11062057 22171320 15057822 17139625 9478979 9153271 9691015 10400683 10811843 11805171 12724130 15616221 16641100 20237569 19468303 11856751 10766831 11278724 14983511 15342463 19349973 21183079 10552972 9572993 15164054 10371504 11717447 11606717 14576052 17124247 10080186 10887099 16959974 21355061 21248752 23114252 11472063 16141072 15815621 16751668 12975309 11572484 12696061 14506705 26566883 12693553 27033969 9851916 12754521 17761667 12906867 12943675
11062057 22171320 15057822 17139625 9478979 9153271 9691015 10400683 10811843 11805171 12724130 15616221 16641100 20237569 19468303 11856751 10766831 11278724 14983511 15342463 19349973 21183079 10552972 9572993 15164054 10371504 11717447 11606717 14576052 17124247 10080186 10887099 16959974 21355061 21248752 23114252 11472063 16141072 15815621 16751668 12975309 11572484 12696061 14506705 26566883 12693553 27033969 9851916 12754521 17761667 12906867 12943675
EMBL
AJ619977
AY916667
AK023591
AK075235
AK027870
AL158158
+ More
AL354982 AL592463 BC030816 BX537918 BX538049 AF308289 AABR03040659 AABR03041327 AABR03041522 AABR03042206 AABR03044351 AABR03044745 AABR03045322 AF022247 AL773538 AL928807 AF197159 AF137068 AF034611 EF444970 AC067747 AL365215 AL596445 AL731551 AY017475 AK038679 AK082377 AC101229 AC122323 AC122839 AC122911 AC123819 AC123866 AC123984 AC124351 AC125132 AC125354 AC132578 AC144939 AC154107 AF333704 AC021523 AC023296 AC087692 AC026991 AC135324 AY017307 DQ384438 DQ384439 DQ384440 DQ384441 DQ384442 KF458667 KF458665 KF458666 AY358174 AB067477 AK126936 AK140264 AK015672 AC099596 AC099600 AC099711 AC101706 AC101771 AC129189 AC130669 AC137905 AC154881 AC157584 AC158907 AK122567 Z74046 Z74473 AY210419 AB114604 AB114605 AB067481 AK126252
AL354982 AL592463 BC030816 BX537918 BX538049 AF308289 AABR03040659 AABR03041327 AABR03041522 AABR03042206 AABR03044351 AABR03044745 AABR03045322 AF022247 AL773538 AL928807 AF197159 AF137068 AF034611 EF444970 AC067747 AL365215 AL596445 AL731551 AY017475 AK038679 AK082377 AC101229 AC122323 AC122839 AC122911 AC123819 AC123866 AC123984 AC124351 AC125132 AC125354 AC132578 AC144939 AC154107 AF333704 AC021523 AC023296 AC087692 AC026991 AC135324 AY017307 DQ384438 DQ384439 DQ384440 DQ384441 DQ384442 KF458667 KF458665 KF458666 AY358174 AB067477 AK126936 AK140264 AK015672 AC099596 AC099600 AC099711 AC101706 AC101771 AC129189 AC130669 AC137905 AC154881 AC157584 AC158907 AK122567 Z74046 Z74473 AY210419 AB114604 AB114605 AB067481 AK126252
Proteomes
Pfam
Interpro
IPR009030
Growth_fac_rcpt_cys_sf
+ More
IPR001881 EGF-like_Ca-bd_dom
IPR035976 Sushi/SCR/CCP_sf
IPR036465 vWFA_dom_sf
IPR013320 ConA-like_dom_sf
IPR000152 EGF-type_Asp/Asn_hydroxyl_site
IPR001759 Pentraxin-related
IPR011641 Tyr-kin_ephrin_A/B_rcpt-like
IPR003410 HYR_dom
IPR002035 VWF_A
IPR013032 EGF-like_CS
IPR018097 EGF_Ca-bd_CS
IPR000742 EGF-like_dom
IPR000436 Sushi_SCR_CCP_dom
IPR000859 CUB_dom
IPR035914 Sperma_CUB_dom_sf
IPR024731 EGF_dom
IPR001881 EGF-like_Ca-bd_dom
IPR035976 Sushi/SCR/CCP_sf
IPR036465 vWFA_dom_sf
IPR013320 ConA-like_dom_sf
IPR000152 EGF-type_Asp/Asn_hydroxyl_site
IPR001759 Pentraxin-related
IPR011641 Tyr-kin_ephrin_A/B_rcpt-like
IPR003410 HYR_dom
IPR002035 VWF_A
IPR013032 EGF-like_CS
IPR018097 EGF_Ca-bd_CS
IPR000742 EGF-like_dom
IPR000436 Sushi_SCR_CCP_dom
IPR000859 CUB_dom
IPR035914 Sperma_CUB_dom_sf
IPR024731 EGF_dom
SUPFAM
Gene 3D
ProteinModelPortal
PDB
4XBM
E-value=3.21297e-59,
Score=587
Ontologies
GO
GO:0007155
GO:0005737
GO:0005509
GO:0005576
GO:0003682
GO:0016020
GO:0006766
GO:0020028
GO:0010008
GO:0001701
GO:0032991
GO:0030492
GO:0016324
GO:0006898
GO:0038024
GO:0070207
GO:0007584
GO:0005905
GO:0008203
GO:0031526
GO:0005765
GO:0043202
GO:0031419
GO:0042802
GO:0030666
GO:0008144
GO:0005798
GO:0015889
GO:0030135
GO:0042366
GO:0005886
GO:0038023
GO:0045177
GO:0042953
GO:0005794
GO:0005768
GO:0030139
GO:0009617
GO:0070062
GO:0005783
GO:0042803
GO:0005903
GO:0015031
GO:0009235
GO:0031232
GO:0001894
GO:0005829
GO:0034384
GO:0042359
GO:0042593
GO:0016021
GO:0001964
GO:0050773
GO:0006629
GO:0005515
GO:0003824
GO:0019001
GO:0031683
GO:0007165
GO:0001664
GO:0005525
GO:0016491
Topology
Subcellular location
Secreted
Cytoplasm
Membrane
Endosome membrane
Lysosome membrane
Apical cell membrane Colocalizes with AMN and LRP2 in the endocytotic apparatus of epithelial cells. With evidence from 1 publications.
Cell membrane Colocalizes with AMN and LRP2 in the endocytotic apparatus of epithelial cells. With evidence from 1 publications.
Coated pit Colocalizes with AMN and LRP2 in the endocytotic apparatus of epithelial cells. With evidence from 1 publications.
Endosome Colocalizes with AMN and LRP2 in the endocytotic apparatus of epithelial cells. With evidence from 1 publications.
Cytoplasm
Membrane
Endosome membrane
Lysosome membrane
Apical cell membrane Colocalizes with AMN and LRP2 in the endocytotic apparatus of epithelial cells. With evidence from 1 publications.
Cell membrane Colocalizes with AMN and LRP2 in the endocytotic apparatus of epithelial cells. With evidence from 1 publications.
Coated pit Colocalizes with AMN and LRP2 in the endocytotic apparatus of epithelial cells. With evidence from 1 publications.
Endosome Colocalizes with AMN and LRP2 in the endocytotic apparatus of epithelial cells. With evidence from 1 publications.
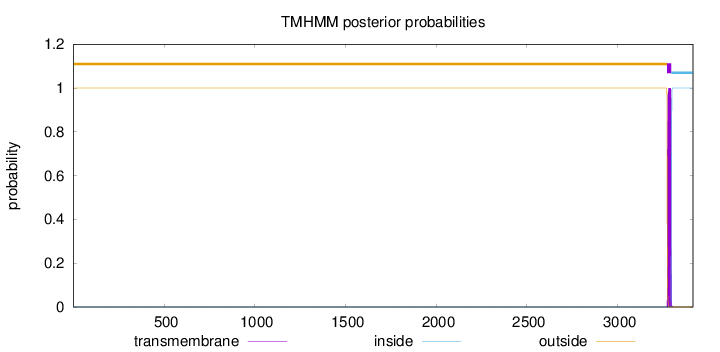
Length:
3415
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
22.86951
Exp number, first 60 AAs:
0.00057
Total prob of N-in:
0.00012
outside
1 - 3272
TMhelix
3273 - 3295
inside
3296 - 3415
Population Genetic Test Statistics
Pi
231.405845
Theta
189.663755
Tajima's D
0.595603
CLR
0.854302
CSRT
0.544972751362432
Interpretation
Uncertain
