Pre Gene Modal
BGIBMGA014089
Annotation
PREDICTED:_ovarian_serine_protease_isoform_X1_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.237
Sequence
CDS
ATGATTGAAACTATGAAAACAGAACGATCCTTCGAAAAACTTGGACTTCCACCTATGGAGTTGGCAGAATCAACAACTAATCGTCAAAATAATGAGGTTAAAAATAAATGGATACTTTTAATACAAAAACTAAAAACGACAATTTTACTTATTGCACTCGCTGCAGGGGTATATGTTTTATCGCTGAGATTGTTGGAAATTTTTGTCGGTACACGTAGCACTGAAATATTTGTAGTAACAGGAACATACGAATACCCGAACATTACATTATACGATGGCGACATGGAAATATTTTTACGATTGAAAAACAATACTTTAGAAGCAAACAAAAGGATGAAAAGACATGTCAGCGAACTAAGCGATAGCATAATAGAGCCTGTAGAAGAGTTCGTTTTAACCGATGAAGACTTACAGAATGCAAGAGAAATAATAGTAAAACATGATTTACTATGTAAACATGGTGACAATGATGAAACTTGTATAAAAATAACTAACCGCTTAAAAGAAATGGTTTTGAAGCCGAAGCTTAATAAAGATCAAAGCAACGAAATTCCTGTCATTCCTAAAATAAAAATTAATAGTTTGCATAGCTTAGAAGCCGATCGTGATTTAAATTCTAACAATCATGCTATTCGTAATTCTGAGGCAGTAAAAAAACGTGAAATACATTCCGTAGCAAAAACACAAAATATATTGGAATCTGTTCCTCGCACACAACTAGCATTTGCAGCTCAACCTTCAGAGAATCATATCACTGATCCATGTCTAGAGCGTCTCTTGAAGCAATATACTCAAGCACGTAACAATTATGAATTGCCTCATTCTGAATACGCACCACCTCAGTATGAGAACCCAACACTCAACAACCTACACCCAAGATACTACGATCCGGTCTCGCACCCAGCATTTCTCCAAGGTCGCGAGGTTGAAGCTAGGAAAAGCAAACTTCATCCACAAGACGTTGATATATTCATGAGCCTACTAACTCCCAAGCCCGAAGCTATTTCCACCAAAAAAATTGATGCAGAAGCACGAACTACACTTTGCTCTGATGGATCAAAACCATGTGATAATGGTGAAGGATGTATAACTGAAAAACAATGGTGTGATGGGAATGTTGATTGTTCTGATGTAAGCGACGAAGCTAAGTGTGACTGTAAATCTAGAGTAGACAAATCGAGGCTTTGTGATGGATACTTTGACTGTCCATTTGGAGAAGACGAAATGGGGTGTTTTGGGTGCAGTGAGACTACTTTCAGTTGTTTGGACGTGGATATGAATTCACAGAGTACTTGTTTCACGAAAGAGCAAAGATGCGATAATATCGAGCATTGTCCGAATCATAGAGATGAACTTGAATGTAATATGTTAGCTCCAAGCCTTTTAAAAAAGCCTCTATTTGCAGTGTCAAATACAGAAGGGTTTTTGCATAGAAATCTTAAAGGAGATTGGTACGCCGTATGCCATAATCCATATATGTGGGCGCATGACACTTGCCGTCGAGAAACTGGACTTATAATAAGACCACCTTTTATACAAATAGTCCCTGTTGATCCGATGTCGAAAGTCAGTTACTTGAGCACGGGTCCAGGTGGTATATTACAAACAAGTGAGACTTGCTTCAACTCTTCCGCCGTTTACGTCACCTGCCCAGATCTGCTATGTGGCACTCGAGTCCCAAGCACGTCACAGCTACTGAGAGAAAACGCTGCTATGGAAAATAGACTTTTTGGAAGAAATAAAAGATTCCTTATAGATGGCCATCCATATCCATTTATGTTTTTCGGCAACCGACAAAAACGATCATTAGTATATCATAACTACGACCTATTAAATTACTGGAGAAATCGCAATGAGTTAAATCGACCTTGGTATATTAGAAATATGCGATCGGAAAGCCGAGTGGTTGGTGGAAAACCAAGTCAACCCACGGCTTGGCCATGGACGGTAGCCATATACAGAAACGGCATGTTTCATTGTGGTGGAGTTATTATCACTCAAAACTGGGTTATATCTGCTGCGCATTGCGTACATAAATTTTGGGATCACTACTATGAAGTTCAAGCAGGTATGCTTCGGCGTTTCTCGTTTTCACCGCAAGAACAAAACCATCAAGTAACACATGTGATTGTAAACCAGCATTACAAACAAGACGATATGAAAAATGACTTGTCTCTACTAAGGGTCGAGCCAATTATTCAGTTCAGTCGATGGGTTCGTCCAATATGCTTACCGGGACCTGATACTGCTGGTCCTGATTGGTTATGGGGCCCATCACCCGGTACTATCTGCACTGCTGTAGGCTGGGGAGCTACAGTTGAACATGGACCAGATCCTGATCATCTTCGCGAAGTGGAAGTACCAATATGGGACAAGTGTAAGCATGAAGAGGATAGAGCCGGTAAAGAAATTTGCGCTGGACCTTCAGAAGGTGGAAAAGATGCATGCCAAGGCGACAGTGGGGGACCATTATTATGTCGAAACCCTACGAATTCTCATCAGTGGTATTTAGCCGGAATTGTGAGTCATGGGGATGGTTGCGCTCGTAAAGGTGAACCCGGGGTTTATACAAGAGTTAGTCTTTTTGTAAAGTGGATTAAGCATCATATAGCCTCGAATTCCTTACCAATAGTCAAGCCTTTACAAGAATGTCCTGGATTCAAATGTAAATCTGGAATTTCAAAGTGCATATTTAATAAAAGAAAATGTGACCAAATTATCGATTGTCTCGGAGGAGAAGATGAAATTGATTGCAATTTTGTAAAATCTACTACAACCTTAAGCGATAACGAGTTTCTTTCTGAAATGTTTAGAAGCAATGAAAGAAGTGACCGAATTGAAATAAATCGCATAACAAAAGGCGCTAATATTGAAAATAACACTTTAAAAATTATCCCAAATACCGAGGCCAGTACAGAAGAAGCGACATCAACTTCTGTTGCAGTAAATCGTTATGATGACAAAACCACTATGGAAAATAACTTTAAACATGCGTCAACACTCGAACTTCCATTTTCTTCAAGTTCTGATGAATCCCATTCTGAATCACATGAAAAATCTATAGGTTTACCTTCAATGGAAGGAACCCTATCAATTTCAGAAGAAAAAACAACAGCAAGCACTACAACAACTTTCGAAGAAATTTTCAGTAGTACAATTTTATCTACAACTGAGGAATATCGCGGAGACACAGCAATTGTCAATGAATCACTAGAATCAGATTCTACAGATTTCCAAAATGCAACAATGGATATGGAAAGCAGTGCTAATGATTTTTTTAAAAACCTTAATATACTTAATGCAAGTAATGTGGAAAATACAACAAATACTAGACCAACAGACGAAACTACTATAACAGATTCAACGACAAATATTCCAACAGAAAGTCAGTTTTCTCAGTTTACTTTGTCGACGGCTGTTACCATCGACGAATACATAAGCATGAATGCAAATGAAATTGAAAAACTTCACTTGTTAAATTTAATTACCAATATATCCAATACAAATTCAAATAATACTGATTTTAGAAATAAATCTGAAGGTTTATATATCGAACTACTTCCAAAATCTAATATAAGCATTATACAAAATACCGATGAGGATGTTAAAGAAACAACTGTAATCGAACAGCATATTACGAGCTCTACTGACAAAGGGCCTCTAAAAACTCTGATCGATATCGAATCAAAGCATGATATCATAAAAAAAATCGAAAAAATAGTTTTCTCTCAAAAAATGCCAGCAAAAATAAGAAGAAGGCACCGTATTCCCAAGGACTTCGAATGTGGAAAGATTCACCAAGTCATTTCGTACAATCTAAGATGCGACAATAAAGCGGACTGTGAAGATGGAACTGATGAACTTGGATGCACATGTATTGATTATCTATCGACTATAAATGAGAAATTTCTTTGTGATGGCAGTTTTCATTGCGCCGATGGACAAGATGAACTTGATTGCTTCAGCTGCCCTGAAGACCATTTTCTGTGTAAAAGAAGTAAATTGTGCATACCACTGAGTAATGTATGCGATGGAGTACCTGAATGTCCTCAAAATGACGACGAGTCGGACTGCTTTGCTTTAACGAATGGCAAAGAACTCCAATACGAAATCGATGATAGACCGCAAATCAATCTAGAAGGATTTGTGACGAAGAAACATTTGAATCAGTGGCATGTTGTTTGCGAGGATAAACTGACTATTGAGCAAATAGAACAAGAAGCTAATCATATTTGCCATTACTTGGGATTCAGTTCAGCAAGAACATATTCTGTGAAGTATATTAACATTAAAGAAGATGACGTTTTATTGATTGATAAAAGAACGAAAAGACAAATAGTTACTACAGTCCCTGTGCATTTTGCTTATAAAAATATTAGCGATGGTGTTAATGCGACTGAACATGTACTCATTCAAGAACCACAATTACTCAAAGAACAATGTGTCCCAAATGTAACGAAAACATGCAAATCTTTGTATGTTTTCTGTGATAGAACATTATATACTGATTTTGATGAGACACCACTTTTCTTGCGTGAAACAGAAGTTGTACAAACATTTAAGTGGCCTTGGATTGCGAAAGTATATGTAGAGGGAAATTATAGATGTACTGGCGTTTTAGTTGACTTGTCATGGGTGTTAGTCAGCCACGCGTGTCTCTGGGATACGTCACTTCACAGCTATATTTCTGTGGTTCTTGGATCACATAAAACTTTGAAGTCTGTAAAGGGACCATATGAACAAATCTACAAAGTCGACGCTAGGAAAGATTTATACAGAAGTAAAATTTCGTTGTTGCATTTAAAAAGTCCCGCAACTTATTCAAATATGGTAAAACCGATGATTGTAGCATCCACCCGCAATCATTTGGAGAAAAATAATAAATGTGTTACTGTGGGGCAATTCGATAACAACGAAACTATTAGTATTTTCCTGGAGGAAACTAATGAAAACTGCAGCTCTCATAACATATGTTTCAAACGCAAATCAATTGGAAATACTGCTGGAATGACATCTAATCATGAATGGGCTGGAATTATAAGCTGTCATACTGAACAAGGCTGGGTGCCAGTTGCATCTTTTGTAGATGGTAGAGGAGAGTGCGGCATAGGCGATCATATACTTGCTACTGATATAGACAACCTGAAAAACGAAATGAAACATTACTCGAGTAAGAAAATATTTTCGGACTCAATGGAGCAGGTAGACGTAGATACTTGTGAAGGGACAAGGTGTGGTCGGGGCTCGTGTATTGGCTTGGAGCGAATATGTGACGGTGTAAGACAGTGTGAAGATGGAAACGACGAATCCGAAGAATCCTGTCATAAAAAAGAACACATCTGTAACGGCGATCCGTTCCATTCGGGATGTGGGTGTTCATCGGGTCAAATGAAATGCCGTAACGGTAAATGCTTGTCTAAAGAGTTATTCAGAGATGGTCATGATGACTGTGGGGATGGAACAGATGAGCCTGGTCACACCACGTGCTCGGATTATTTGGCAAGAGTTATGCCTTCGAGACTTTGTGATGGAATCTTACACTGCCATGACAGAAGTGATGAAGATCCGAGCTTCTGTAAATGCTTTGCTAAAAAGGCATACAGATGTAACAGAAAATCGCGTCAATCAGAACAGTGTGTAGCTCCTGATATGTTGTGTGATGGTGTAAGAGATTGTCCAAATGGAGAAGACGAACAAACTTGTATAGGTCTCAGCGCACCAGAGGGAACTCCCTACGGAACTGGACAAGTAATTGTTCGGTCACACGGCGCATGGCATTCTAAGTGCTATCCCACGCAAAACCACACTAAATCAGAGTTAGAAGCCATTTGCAGAGAACTTGGTTTTATAAGCGGCCACGCGAAGGAAATCAAAGGGATGAAAATCCTCCACCCACACAATAGCCTACTTTTAGATCCTTTCAGAGAAGTCGTTTTGAACAACAACACTGTTATTAGAATGAGAAACACGCACGAGCCACTGGCAAAACCCATTTTTAACAAAGACATAATTAATTGTTACCCAGTTTTTATAGAATGTTATTAA
Protein
MIETMKTERSFEKLGLPPMELAESTTNRQNNEVKNKWILLIQKLKTTILLIALAAGVYVLSLRLLEIFVGTRSTEIFVVTGTYEYPNITLYDGDMEIFLRLKNNTLEANKRMKRHVSELSDSIIEPVEEFVLTDEDLQNAREIIVKHDLLCKHGDNDETCIKITNRLKEMVLKPKLNKDQSNEIPVIPKIKINSLHSLEADRDLNSNNHAIRNSEAVKKREIHSVAKTQNILESVPRTQLAFAAQPSENHITDPCLERLLKQYTQARNNYELPHSEYAPPQYENPTLNNLHPRYYDPVSHPAFLQGREVEARKSKLHPQDVDIFMSLLTPKPEAISTKKIDAEARTTLCSDGSKPCDNGEGCITEKQWCDGNVDCSDVSDEAKCDCKSRVDKSRLCDGYFDCPFGEDEMGCFGCSETTFSCLDVDMNSQSTCFTKEQRCDNIEHCPNHRDELECNMLAPSLLKKPLFAVSNTEGFLHRNLKGDWYAVCHNPYMWAHDTCRRETGLIIRPPFIQIVPVDPMSKVSYLSTGPGGILQTSETCFNSSAVYVTCPDLLCGTRVPSTSQLLRENAAMENRLFGRNKRFLIDGHPYPFMFFGNRQKRSLVYHNYDLLNYWRNRNELNRPWYIRNMRSESRVVGGKPSQPTAWPWTVAIYRNGMFHCGGVIITQNWVISAAHCVHKFWDHYYEVQAGMLRRFSFSPQEQNHQVTHVIVNQHYKQDDMKNDLSLLRVEPIIQFSRWVRPICLPGPDTAGPDWLWGPSPGTICTAVGWGATVEHGPDPDHLREVEVPIWDKCKHEEDRAGKEICAGPSEGGKDACQGDSGGPLLCRNPTNSHQWYLAGIVSHGDGCARKGEPGVYTRVSLFVKWIKHHIASNSLPIVKPLQECPGFKCKSGISKCIFNKRKCDQIIDCLGGEDEIDCNFVKSTTTLSDNEFLSEMFRSNERSDRIEINRITKGANIENNTLKIIPNTEASTEEATSTSVAVNRYDDKTTMENNFKHASTLELPFSSSSDESHSESHEKSIGLPSMEGTLSISEEKTTASTTTTFEEIFSSTILSTTEEYRGDTAIVNESLESDSTDFQNATMDMESSANDFFKNLNILNASNVENTTNTRPTDETTITDSTTNIPTESQFSQFTLSTAVTIDEYISMNANEIEKLHLLNLITNISNTNSNNTDFRNKSEGLYIELLPKSNISIIQNTDEDVKETTVIEQHITSSTDKGPLKTLIDIESKHDIIKKIEKIVFSQKMPAKIRRRHRIPKDFECGKIHQVISYNLRCDNKADCEDGTDELGCTCIDYLSTINEKFLCDGSFHCADGQDELDCFSCPEDHFLCKRSKLCIPLSNVCDGVPECPQNDDESDCFALTNGKELQYEIDDRPQINLEGFVTKKHLNQWHVVCEDKLTIEQIEQEANHICHYLGFSSARTYSVKYINIKEDDVLLIDKRTKRQIVTTVPVHFAYKNISDGVNATEHVLIQEPQLLKEQCVPNVTKTCKSLYVFCDRTLYTDFDETPLFLRETEVVQTFKWPWIAKVYVEGNYRCTGVLVDLSWVLVSHACLWDTSLHSYISVVLGSHKTLKSVKGPYEQIYKVDARKDLYRSKISLLHLKSPATYSNMVKPMIVASTRNHLEKNNKCVTVGQFDNNETISIFLEETNENCSSHNICFKRKSIGNTAGMTSNHEWAGIISCHTEQGWVPVASFVDGRGECGIGDHILATDIDNLKNEMKHYSSKKIFSDSMEQVDVDTCEGTRCGRGSCIGLERICDGVRQCEDGNDESEESCHKKEHICNGDPFHSGCGCSSGQMKCRNGKCLSKELFRDGHDDCGDGTDEPGHTTCSDYLARVMPSRLCDGILHCHDRSDEDPSFCKCFAKKAYRCNRKSRQSEQCVAPDMLCDGVRDCPNGEDEQTCIGLSAPEGTPYGTGQVIVRSHGAWHSKCYPTQNHTKSELEAICRELGFISGHAKEIKGMKILHPHNSLLLDPFREVVLNNNTVIRMRNTHEPLAKPIFNKDIINCYPVFIECY
Summary
Pubmed
Proteomes
Interpro
Gene 3D
PDB
3W94
E-value=1.30582e-42,
Score=442
Ontologies
GO
PANTHER
Topology
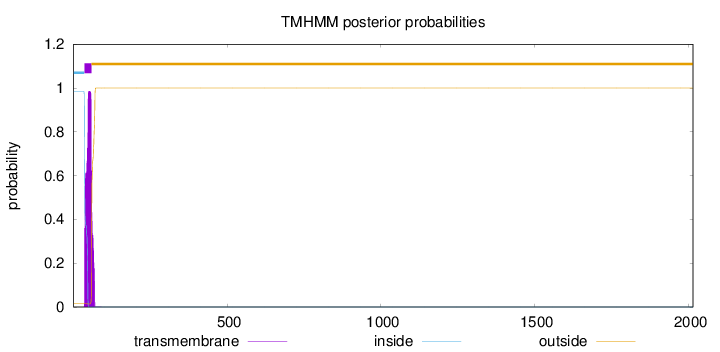
Length:
2014
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
22.03099
Exp number, first 60 AAs:
19.17444
Total prob of N-in:
0.98560
POSSIBLE N-term signal
sequence
inside
1 - 36
TMhelix
37 - 59
outside
60 - 2014
Population Genetic Test Statistics
Pi
276.552646
Theta
220.018322
Tajima's D
0.808007
CLR
0.514493
CSRT
0.606619669016549
Interpretation
Uncertain
