Gene
KWMTBOMO04771 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA009891
Annotation
PREDICTED:_mucin-5AC_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.446
Sequence
CDS
ATGATTGGCTCCGAATCCACAATATGGCTGACCCTGCTATTGGCAGTGATAGCAACAACGCCAGTATCATCAAACGAACCGCGAGTGGTGTGTTACTACACGAACTGGTCGGTGTATCGGCCCGGTACGGCCAAGTTCAACCCACAGAACATCAATCCGTACCTGTGCACGCATCTTATATACGCCTTCGGGGGCTTCACGAAGGATAACACGTTGAAGCCATTCGACAAATACCAGGACATCGAGAAAGGTGGTTATGCCAAGTTCACCGGACTAAAGACGTACAACAAGAATCTGAAAACACTCCTAGCCATAGGCGGATGGAACGAGGGTTCTTCCAGATTCTCCCCTATGGTAGCGTCCAAGGAGAGAAGGAAAGAGTTCGTCAGAAACGCTATTAAGTTCCTCAGACAAAACCGGTTCGATGGTCTCGACTTGGACTGGGAGTACCCTGCCTTCCGCGACGGCAGCAAGCCCAAAGACCGGGAGAACTACTCGAGGCTGGTGCGAGAGCTACGTGAGGAGTTCGAAAGAGAATCTGAGAAGACCGGAAAACCAAGGTTGCTGCTGACCATGGCAGTGCCAGCTGGCATCGAATACATCCAGAAGGGTTATGATGTTAAAACTTTGAACAGACATTTGGATTGGATGAATCTACTATCTTATGATTACCACTCCGCTTTCGAGCCGGCGGTCAACCACCACGCACCCCTCTACCCTCTCGAGGAGCCAAACGAATACAGCGTCGACACAGAACTTAACATTGACTACACGATAAAATTCTACTTGGAAAACGGAGCAGACCGCAATAAGCTTGTGCTCGGTATCCCCACTTACGGACGTTCGTACACGCTGTTCAATACTGAAGCTGTGGAAATAGGCTCGCCTGCAGACGGTCCCGGGGAACAAGGGGACGCTACAAGAGAAAAGGGCTATTTGGCTTATTACGAGATCTGCGAAGCTCTGAAACCTAAAAGCAAGAAACGCGCCATCGACTCCGACGAAGAATATTCTGAAGAAGAGGAGGAGCAGGAAGACGAAGAATGGACGGTGATGCATCCGAACCCTAACGCTATGGGACCTATAGCCTTCAAGGGGAACCAATGGGTCGGCTATGATGACATAGATATTGTTAGGAAGAAGGCGGAATATGTGGCTGAAAATGGTCTTGGAGGTATAATGTTCTGGTCCATCGACAACGACGACTTCAGGGGGACATGTCACAGTAAACCGTACCCTCTAATCGAAGCCGCTAAAGAAGCGTACATACAGAAACTTGAATCATCGGACAATGTCATCATAACAGAGAAGCCGAGTTCAGCGAGCCGCACCAGCAACAGGAGGAAGAACCGACCGAAGACCACCAAAACCACCACCACGACTACCACTACCACAGAGAAACCCACCACAACTAAGAGCAACAAACGCAAGAGCTCCAGCACGACGCCCGCGTGGGGTCTCGTCACGCCTTCGCCCCCGACCACCCCCGACCCTGGTTCAGACTTCAAGTGCGTTGATGAAGGCTTCTTCCCTCATCCTCGCGACTGCAAGAAGTACTTCTGGTGCCTCGACTCCGGACCCTCGGACCTCGGTATCGTCGCTCATCAGTTCACGTGTCCATCAGGACTGTACTTTAACAAAGCGGCCGATTCGTGTGACTTCGCCCGGAACGTCCTCTGCAAGACCGCCACCACCACGAAGGCCCCCACCACCAGGGCTCCCACTACCAAGCCTCCCACGACAAAGACCACCGTCACGACGACGACCACCACCACTACCAGGAAACCAATTAAGATTAGCACGAGGAACTCCCTGCTGTTTCGAACTACCACCACCACAACCCCGGCGCCTGAACCTGAGAGCGATGAGGAATACCAAGATGAAGTCTCCGAAGACACGTTCGATGACGCCGAGGATCCGAAAGTCATCAAGGAACTTATTGACCTCATCAAGAAAGTCGGTGGCATTGAACAGCTGGAGAAACAATTGCACCTGTCAGAAGCGTCGGCCAGCACCGACGGCGCCAGCACCACCACTCCCTCATCTTTCAACAAGAAGCTTTACCAGAAAGTTCTGGAGAGAACCCGTGGGAAGAATAAGTACAGCCAAAACAGCGTCTTCGAGAACAATCGCCGAGCGCCGCAGAGTCAGGGTGGGGAGCTCGCCGCCGACGGAGACCAACTGCCGCGGAAGGACCGACCACAGTACGTGACCATCAATCGACAACGTCCATCAACATCGACCACAGCTGAACCAGAGAGCGAGTATTCGGAAGAAGAGGAGGAAGATGAAGAAGAAATTCCGGAGCCCATCAGAGCCAGACCGGCTGAATCATCGGGCAGAGTGGGAACGACGGCGAAACCATTGCAGTACGTTAACATCCGAAGAGGCAGACCCACCGCTACTACGTCAGAGCCCGCCGATGATACAGCTTCCAGAAATGCCCTCTTTGAACGCCAAGAGCCGGCCGTGACGAGCTCGCTAAGTAAACTGGACGTTCTGAACGCACGTAAAGAGAACCTTCCCGAATATGTCACTATAAGACGCCAGCGACCGACCACAGAGGAGACCACGACAGTGCAATACCAAGCTGAAGAATCAGAAGAAGATTCACGTCAAACTGCATTGGAGAGAGAAATATCTTCTCAACCACAATACAATTCTATAATTCGTACTCGCTCTACAACTTTTGCGCCAGTCGAAGAATCAACTAGTCCCATACCCTTTACATCAAGAGCTCGGTCCACAACCCTCCCTCCAGTTGAAGAACCCAGCAGTCCTGAACCCACTACAGTTCTCACTGTCCAAATATCCTCTCTGATCAATTCTCTAAACTCCGAAATCGATTACCCCGTACCTGAAACCACATTGGCCCAAGCTACTGAGCCTGCAGAAGCTCCTACGACAACAAGCACAACGGTCACTACCACCACCACAATGACAACGACAGCGGCGCCTTCGTCCATCCCACCACGTAGAACAGTTCTTAGGAGACGAGGCTCCACATCTACCACCACCACCACCACTACTGCATCAACTCCTGTGTCCTCAACTCAGGTGAGTCCAAGGAATTACGCTTTCCGCCGTCGCCGGCCGCTAGCAAGTCAAAACGAAATTTCTTCTGAAACTGAAGAAGACGTTTTGCTGTCACGTAAAATTAGGTCAACAACTCCTGACAGTCGAGAGGTAGACAGGGCTAAGGCAAACAGAGAAACTGGTAGGAGATATAGAAGTAGGTTCCAAGCACGAGCGTTGCAAAATGAAGACTCAATACCTGCTGCAGCTTCTCCTGTATCGAGTATAAACACAGACGAAGTTGCATCATTGACACCTGTTGACATAGAAACTCAAGTAGAACCTCGGAAGAGTTTCACTCCGAGGTTTGAACGTCGTTTTCGCGGTAGGACAACTGTGGCTGAAGCGATAGCAGACAGCGAAGCATCGGCAGCAACAGTGGAAGTCAGACGACCTGATTTTGCGTCCAGAGGTCGTAGCAGATTTACACTTAATTCAACCACTGAACCAGCCTCCCAAGCTTCGGTCACAAGTTCGACAGCTGGACAGAGGCGGCCCACATTCGGACGGTTAACTCCAAGGCCTTTCGCTCGGACTACTTCCACAACTGTAACGCCAGATGATGATTACAACGACGAAGTCGAACCAGTCACTTCTAAAACTCCATCACGATTAGCTTTTGGAAGAAATCGACCTTCAGCAATACCTCGAACTCCTTTAATCCAAGCTAGAAAACTACCATTCCCAACACGTCAATCAACGACGCAGAAACCTATCGATAAAGAAAACGAAGATTATGATGAAACTGAAACAAAAAATGATGACATAACTCTATCAGAAACGACTATAGAAGAAAAAGAAGTTAATGAAGAAAATACTGAAGAGACGCCAATACGAAGGGTTATCATTAAAAAAGTCAAAACTCCAGGATCTACAGATAATTCAGAAGCAATTCCTGTTGATGAGTCGGGAAGAAAGCGATTTAGGATAATCCGAAGAAAACCAATAGTAACAACAACTACACCTGAAATCGATGAAGTCATAACTTCAACAGCAGCTATACCAAGGATTCGAAAGATAATTCGTAAGAAAATAAAACCAGTTGAAAAAGAACCAAAAATAGCAACAACGGCATTTATAGACGATCAAACTCCAGAACCATTAGTTAACTATGGAGAGAAAACTAAAGCAACAACTGAATCAGCATTTACAAATTCGCCTACAAAACTTGAAACAGAAGGTACGCCTGAACCGATTACACTAACCGTAAATGATGAACAGATTAATCGTAACGAAGATACTGAAAATCTTAAAGATGATGAAAAAGAATTGAAAACTGAAATTGTCAAAACGAACGATACACCACAGGAAATTCCTAGAAAACCGGAAACTACAACTATAAAACCAGAAAACAAAGAGCAAGATGAAAATAGTACAAATGATTATGAAAAGGCACTTGAAATAACAAGTACAACACCTACTGTTCCTGCTGCAGAAACAAAATTAGATGAAACGGAACAAACATCTCTTTATATTTCTGGTAACGAAACCATATCTGTAGATGCCACGACTATAGCATCATCAGACTTATTAGTGGATTCCATTACCACCGTATCTGAAGAAAACCTACCAGAAACTACAACAACAAGTACAACTCTATCAACACCGTCGTCTTCGATCCGTACAAGGTTACCTTACAGACCACCTAAACGCCTATTTACATCAACAACTGCAGCAGCCACTATCGCAAGCAGTAGAATATTCAGCCGCAAGTATAACCCCGGCGTTTACACCAGCCCTTCTACAATTGAACGGGAACCGTTTAGACCATCAGGTAGAAGACCGTTCTCTTCTAAAGTTTTCACGAGGAAACCATTCACGACCGTCAGTACAACGCCGAAAGAAGAGGAATATGAGGAAGAATACACTGACGATGAAGAACTTTTGGAAGAGGAGCCTGAAAATCCATTTGCTTTCGTTCCGTCCAGTCAACTATTTACTAGGAAACCAGAGGAGGATGAAGAGGAAACTTTAGACGAAGAAGACGAATCAGAGGAAATTTTAGACGAAGAAGAAGATGTTGACGAAGCTAAACCAGTAAATGTGTTCTCGTCTACCACTAAAAGAACGCCATTCAAGCCCAGACTTATAAATTCGAATACATTCCGAACAACGACGTCAACAACTGAGCTACCCAGACCCAGTCTATTTGGTTCTTCGCAAAATCGAAGCGGTGTCTTTACTAGATTTGGAAGCCCTAAGCCATCTAATGATACAAAAAAACGAGTACAAAATGTTCCGATCGGTTACAATAGTCCCGTCTCTAGTCCAAAGCCAAGTATCGAAGTTGCACCTAAAAACGAAAATCAACCGTCTACAGAACTATCACAAGATATTACTACAACAATTTCTAGTATAACAGAGACCGACTTTACCACTGACATTGACGATGATTATTTATCAGCAACAGAAACTCTGAACACTACATCGGACTTAAATAGATTCAGTGATTTCGTGACGAATGTTATGGAAAATGAAACAACGACTCAACTAATGGAAGTAATGACAGACACAGATGATTACTTAGAAGATAGCACAACAAGCCAAACAACTGTTCCAGAGATTACAATTACCACACAAACCGGACCCGTATATGAACCTCCTGTATTAACCAGTACTGCTAAATCAACTACTTTATCGATTACTGGTGAAATGACTCCTGAAACTACTTCAACTGCAGCGCCTATTGTTAAGACGCAATTCGATAAATTATTCTCCATAAGCAGAGTAGTTGAGGTGTCATCCAAATTAGATAAGCACCGTGTAAATAAAAACAATGAAACGACGCGGATTGAAGAAGGAAAAATTGTTGTGGAAAAACAACCAGTTGTTGACAAAATAGGGGAGGTTAGCAGATTTAGTCTTATTAAAATTGTCGAAGACGAAATTCCGATTTATTTGACTAAGCTTGGTCATGTCTACCCAGTCGCAAATCCACCTGACAACCCGATCCGAATCGATGAAGCGCGAAACGCCAGAGCTTTAAATTATTTCGAAATACCAAGGGAAAATCTAGTAGCTTCCGAGAGTATAAACGAAGCATACAGACATAACAAAGATATCACTGACAAAGACCGCGTGGAACATTTACAGCAAGATGACTTTCTAAGTTACGTAAATGAAGATAAAAATGACGACAAAGAACAGGACGAGACCTACACTCAATGGCAATTTGTACCGGCTGCTTACGAAACTGAAAAACAAAAGGCAGCGAAAAATTTCGAAATAGTTACACCCCGATCAATGCTCACGTATCCATCAACTTTACCCTTAGAAGGACTTTTTAAAACCGAAACACCAACTGCGAGGAAAGTAATTAATGACCCAAACCAACCGTTTGTGGTTTATTCGGCCCCAGCTGCAACTGAAGAAGACACAGTCAATATAGTTAAGCTGAAGGTTTTAAAGCCAGAGACTGGACGCAGCATTATAACATTTGCGAAAGGTCAACAATTCAGCGGTGCGCCTACTACAGAAGAATCCACAGTAAAATATCCAATCAATATTTCGATTTTGCCCAGTCCAGAGGTTTCTACTACACCAGCAGATGTTTCCACGACGAGCACTACAACTGAATCCGTTGAAAGATTGATTACTACTAGTCCGTTAATAGATTTACTAGTCACCCAAATGATAACCGAAGCTACTACGACAACAACTGCTCCTCCAAGTACAATCGTTTCCACAACAGACGCAACTTCGGCAACAGAAACGATCACAGAAGAAACAACAACATCATCCGCTGTTGATATTAAAAAGGGTAAATTTGCATTTCCAAGAAGACCAATAATCAGGCCGTTGAACTTCACGAGGCCCGCTCCGAGATCGACAAAAAAAGTTAACGCAACACAATCAGACAATTCGATTCAGAAAACGAATAAGACGGCCACTTTTACGCCATTAAAATCCAGGTTTTCGTCTAGCAGAAAACAAAATGTACCAATAGACGTTAAGAAGAAAACGGGAGACATAAAACCAACAACAAGGTCATATACAACCGAAACACCAAGAGCTACAACGGAAAGGAGAGTTTTCATAAAATCTTTAAGACCCGGATTCCAAAGACCGGCTTTTGTACCGAGAAAAACTACAGCCACAACACAGAGCAGTGGCGACACTTAA
Protein
MIGSESTIWLTLLLAVIATTPVSSNEPRVVCYYTNWSVYRPGTAKFNPQNINPYLCTHLIYAFGGFTKDNTLKPFDKYQDIEKGGYAKFTGLKTYNKNLKTLLAIGGWNEGSSRFSPMVASKERRKEFVRNAIKFLRQNRFDGLDLDWEYPAFRDGSKPKDRENYSRLVRELREEFERESEKTGKPRLLLTMAVPAGIEYIQKGYDVKTLNRHLDWMNLLSYDYHSAFEPAVNHHAPLYPLEEPNEYSVDTELNIDYTIKFYLENGADRNKLVLGIPTYGRSYTLFNTEAVEIGSPADGPGEQGDATREKGYLAYYEICEALKPKSKKRAIDSDEEYSEEEEEQEDEEWTVMHPNPNAMGPIAFKGNQWVGYDDIDIVRKKAEYVAENGLGGIMFWSIDNDDFRGTCHSKPYPLIEAAKEAYIQKLESSDNVIITEKPSSASRTSNRRKNRPKTTKTTTTTTTTTEKPTTTKSNKRKSSSTTPAWGLVTPSPPTTPDPGSDFKCVDEGFFPHPRDCKKYFWCLDSGPSDLGIVAHQFTCPSGLYFNKAADSCDFARNVLCKTATTTKAPTTRAPTTKPPTTKTTVTTTTTTTTRKPIKISTRNSLLFRTTTTTTPAPEPESDEEYQDEVSEDTFDDAEDPKVIKELIDLIKKVGGIEQLEKQLHLSEASASTDGASTTTPSSFNKKLYQKVLERTRGKNKYSQNSVFENNRRAPQSQGGELAADGDQLPRKDRPQYVTINRQRPSTSTTAEPESEYSEEEEEDEEEIPEPIRARPAESSGRVGTTAKPLQYVNIRRGRPTATTSEPADDTASRNALFERQEPAVTSSLSKLDVLNARKENLPEYVTIRRQRPTTEETTTVQYQAEESEEDSRQTALEREISSQPQYNSIIRTRSTTFAPVEESTSPIPFTSRARSTTLPPVEEPSSPEPTTVLTVQISSLINSLNSEIDYPVPETTLAQATEPAEAPTTTSTTVTTTTTMTTTAAPSSIPPRRTVLRRRGSTSTTTTTTTASTPVSSTQVSPRNYAFRRRRPLASQNEISSETEEDVLLSRKIRSTTPDSREVDRAKANRETGRRYRSRFQARALQNEDSIPAAASPVSSINTDEVASLTPVDIETQVEPRKSFTPRFERRFRGRTTVAEAIADSEASAATVEVRRPDFASRGRSRFTLNSTTEPASQASVTSSTAGQRRPTFGRLTPRPFARTTSTTVTPDDDYNDEVEPVTSKTPSRLAFGRNRPSAIPRTPLIQARKLPFPTRQSTTQKPIDKENEDYDETETKNDDITLSETTIEEKEVNEENTEETPIRRVIIKKVKTPGSTDNSEAIPVDESGRKRFRIIRRKPIVTTTTPEIDEVITSTAAIPRIRKIIRKKIKPVEKEPKIATTAFIDDQTPEPLVNYGEKTKATTESAFTNSPTKLETEGTPEPITLTVNDEQINRNEDTENLKDDEKELKTEIVKTNDTPQEIPRKPETTTIKPENKEQDENSTNDYEKALEITSTTPTVPAAETKLDETEQTSLYISGNETISVDATTIASSDLLVDSITTVSEENLPETTTTSTTLSTPSSSIRTRLPYRPPKRLFTSTTAAATIASSRIFSRKYNPGVYTSPSTIEREPFRPSGRRPFSSKVFTRKPFTTVSTTPKEEEYEEEYTDDEELLEEEPENPFAFVPSSQLFTRKPEEDEEETLDEEDESEEILDEEEDVDEAKPVNVFSSTTKRTPFKPRLINSNTFRTTTSTTELPRPSLFGSSQNRSGVFTRFGSPKPSNDTKKRVQNVPIGYNSPVSSPKPSIEVAPKNENQPSTELSQDITTTISSITETDFTTDIDDDYLSATETLNTTSDLNRFSDFVTNVMENETTTQLMEVMTDTDDYLEDSTTSQTTVPEITITTQTGPVYEPPVLTSTAKSTTLSITGEMTPETTSTAAPIVKTQFDKLFSISRVVEVSSKLDKHRVNKNNETTRIEEGKIVVEKQPVVDKIGEVSRFSLIKIVEDEIPIYLTKLGHVYPVANPPDNPIRIDEARNARALNYFEIPRENLVASESINEAYRHNKDITDKDRVEHLQQDDFLSYVNEDKNDDKEQDETYTQWQFVPAAYETEKQKAAKNFEIVTPRSMLTYPSTLPLEGLFKTETPTARKVINDPNQPFVVYSAPAATEEDTVNIVKLKVLKPETGRSIITFAKGQQFSGAPTTEESTVKYPINISILPSPEVSTTPADVSTTSTTTESVERLITTSPLIDLLVTQMITEATTTTTAPPSTIVSTTDATSATETITEETTTSSAVDIKKGKFAFPRRPIIRPLNFTRPAPRSTKKVNATQSDNSIQKTNKTATFTPLKSRFSSSRKQNVPIDVKKKTGDIKPTTRSYTTETPRATTERRVFIKSLRPGFQRPAFVPRKTTATTQSSGDT
Summary
Uniprot
ProteinModelPortal
PDB
1GUV
E-value=3.21129e-80,
Score=767
Ontologies
PATHWAY
GO
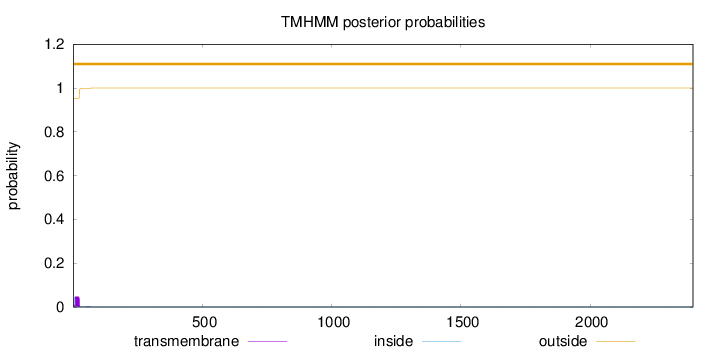
Topology
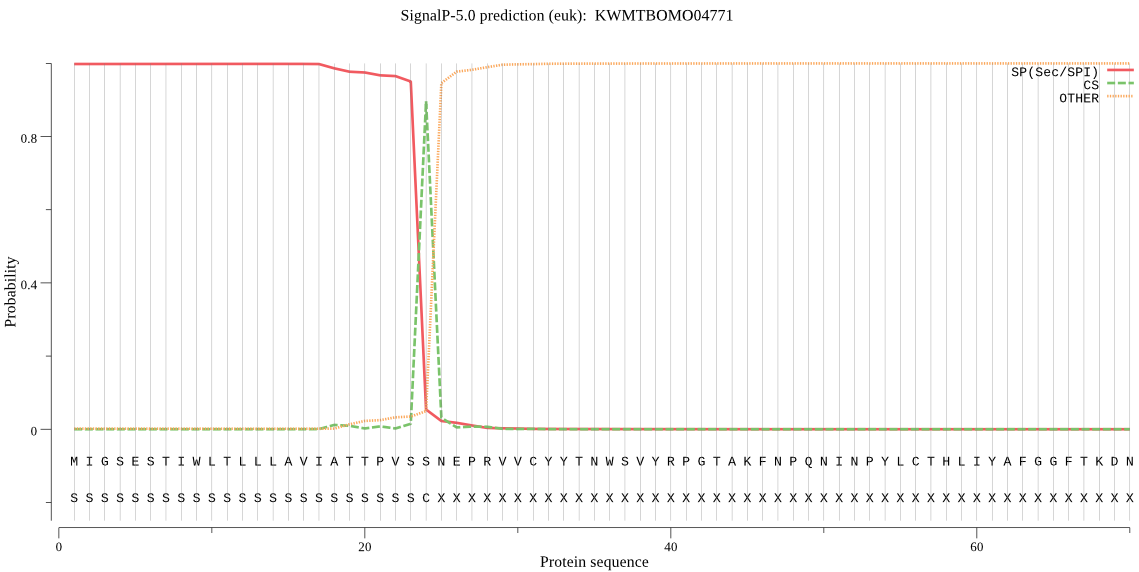
SignalP
Position: 1 - 24,
Likelihood: 0.998537
Length:
2398
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.917019999999998
Exp number, first 60 AAs:
0.90508
Total prob of N-in:
0.04714
outside
1 - 2398
Population Genetic Test Statistics
Pi
23.45987
Theta
25.831881
Tajima's D
-0.6711
CLR
1.508135
CSRT
0.204439778011099
Interpretation
Uncertain
