Gene
KWMTBOMO04030 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA010275
Annotation
Uncharacterized_protein_OBRU01_03354_[Operophtera_brumata]
Location in the cell
PlasmaMembrane Reliability : 1.928
Sequence
CDS
ATGCGGTTGTCTCATTGGATGGCTTTGGCCGTCCTTTTCGGAGGTACGGTAACCGGTGATATTGTCAACGAACTACCTCCAGAAGAGTTCGACGTCAAAATCGGCGAAACAGTAGCCGTTTCCATCGCATCAAATGATGGATTCACTAATACCGAGTGTCTAATTCAGACTCCAGATGGCGGGCCACATTCTCTTCAAGAACTTGACTTTATTGATGTTATAACCGAAGCGGGGGTTGATTGCAGCATTAAGATTAAAGTAACCGAAGAGATAGAAGGCGCCTGGACTCTTATTAGCCGAGCCACGTCGTTCGGTAGTCCTGTGAAGAGAACATTACCCTTCACTATCAATATAGTTCCAGGTGAACACGATGAATCTGATGATGAAAAAACAGAATCAGAAGAAGAAAAAGAAAAAGAAAAAGAATCAGAAGAAAAACAAGAAACGGATGAAGACGATGGCAAAACTATATGGTTAACTGAAATCAGACGCTTCACGAGAACTGAACAAATCGTTGATGTGTCATTACCGAACATTGGATACGATGAAATATGCACTGTCATTACTCCTGACAGAAAAACCATTACGGCCGCAGAAATAGAAATTCCAGGAGTTAAAGTACAAAGTAAAAGCGTTTTTGTTTCGTGTAGAATCAGTATCGGGCCGCTGAAGTCAAATTTACTGGGCAAGTGGACTCTCTGTGGAAGACGAGATGGTGCTGAGGAGCGAAGATGTCAGGTCGTCACTATTGAATGGAACAGTGAGAACGCACCCCATGCGTTATGGGACTCCAGAACTCAGCCTCTTTTCAACCATCCCGTCAATCTCAATGGAATTTTGACACCGGTCGTTATAGGTTCAGGATCTTTGTTAACGTGCCATATTGTTACGCCAAATGGTGAAGATTTAGTCGTCTTACCAGAGACGAAATACCCTGGCATCATCCGCGCAGAATCCGGTACAACGGGTTGTAGTATCGCAATTGGTCCCATAACACAGGATATGTTGGGACAATGGGAACTTTATGGAATGTTTAGATCAGTGCTAGGACTGAATGAAGTCCGTTTGCCTATGAACTTTGAGTTGTATGATACTGACAACCCTTACAACCAAGCTTACAATTTAACTGTTTTGGATGCAAAAAGACATGTGATCAATTTGGGTTCTACAATATCAGTAGAAGTTAGCGGTCACGGAACAATGGACAACTGTGAATTTGTTGCTCCTTCAGGGCAAGCTTATCAAAGTACTGGCAAGAACAATTTCGAAGGAGTTCAGTTTGTAAATGTAGACGGCATTACAGCTTGCCGTATCTCGATCGGTCCCATTACCGAAGTAATGCTTGGGAAATGGCAAATTGTCGGGAAATTCAATGATGGAAATATATTTAACGAGAGACAATTGCCTTTTGAAGTCATACGCGAAGATCCTGCAAATCCTATTGACGACGTTGACAGAATTGTAACCACGATTGACGATAGGAAATACGATACTGAAATCGGCGCGACTCACGAGATCATCATAAATCGTGGAGACTTCATTAAAAGTGAATCCTGTCAGATCAGGACACCTTCGGGAAGACAGTACACCTTAATGGATGGCTTCAACCTACAAGGGATAGAGATTATAGAAGATACGAATGTGGAATGTGGAATAAGAATGACTGTGCTATCTGAAGATATGGTCGGCGAATGGGTGCTAATTTCAAAAGTTACGATGCTCTCTGATCCTATGGAAAGAAGACTCGTGTTTAAAATTCACATTGAAGAGCGCGTCGAACCTAATTCTGCAAGCATTACAATAACTGAAGGCAACGATTTATACCTTAGACTGAAGAATCCAGTAGACAAACAAGACACCTGCAAACTCATTGCTCCTAACTCACGTGCTTTCGAAATAGATGAACCAAACGCGAGACTGTGTGGATTCTTGGCTAGAGCCGTTTCGGATCAGGATAGTGGAGAATGGGAAATACAATATGGAGATACAATTTTATACAGAGCTGTAATAAATGTTAATGTTGTCGAAAGAAGTACAATACAAGTGCAAGATTTAACAATAATTGAAGGTAGTAAGCTGATTACGGAAATCGGTCCAGATGATTTGGTGTTTTGTAAACTAGAAGATCCATTAGGCATGACCGTATATGAAGGTTTCGGCAGATGCGTGATCCGTGTCGATCGAGCGACAAGAAACCATAATGGCAAATGGAAGATGTCTATTGGATTACAAGGGCGTATTCTACTTGAAGAACTCACTTTTACAGTTCACGTTAGAAGTGCAGGATCCAGACAAGTACAGACTTCCGTGCGCAGGGAACGTCCTTCGGTGGTCATATCATGTTCGCTTACGAGCAACGTCGAAGTCCGCGCTTGTAAGTTCCGCGATCCCCGCGGCAAAGTCCTGATCGCTTCACGCGGAGTCGGAGAGGACAGATACGCTTACCACGGCTCCGAAGTGACCTACAAGTCCGACTTGTCCAGCCACGAGTGCGGGATCCGACTGACGAACCCTTCGGAGGAAGACCTGGGTCTGTGGCGCTGCGGCATGGAAACTGAAACCGAGACTCACTATGGCTTTCTACCGGTTATTTGTCCTTGGTTACTGGACACATCGGAAATCCAAGACAAGGTTGTCACTGAGCCAATCCTGAGTGCGGATACAAGTTACGTGTCGTCTCCTGAAGGTCAGGCCGTTGTGATGTCGTGCTCTGTGTCCGCTACGATACAATACTGTTACTTCAGGGCACAAAACGGAACAGTATTCAGTGTTACTCCTGGCGCCACCTCTACCTACACTGAGTATGTAGGCAATGGCTTCGCTGCCGGCGAGTGTGGAGTCAGGTTTGATGGCTTGTTGACGACTGATGGCGGTCGATGGAGTTGCCACGTGGGACTTTTGGACACTGAGCAGGAACAACGGGCGGAGATCACTCTTCATATTTTCGAGCAAATGAGAGTTAGGCATTACATCCATCCGCGCGGCCTGATGGTGGAAGCCGACGTTGAGACGCCTGAAGAGTTGGAGTACTGTAGATTCGTGCGCATAGACGGTCTAGGATTCACAAGTGAAAATGTACCGAACGGTTACCAGAGCATGAGTAATCTTCAGGAAGGTCTGTGCGCACTGTTGATGCGTGACCAGACAACGCTGAACCTTCACCCCTGGACTGTGGCCGCTAAGGTTCACGGGCAGACGGAAATAATGAGAACCAGCACCCAGAACTTGCTGTGGACCTTAAGCCAGAGGACCGCCACGGTCTATTCGATATACTTGTTCACCGTGGTGATGTTCATTCTGCTGGCGACGGTGCTGGTGGGAGTCAGCCTCGGCCCCAAGAAGAACAGGAAGTGGACGTACGACCGGGTCTCGCGTTTGAGTACCAATATCAGGAACAGCTTCCGGAAACAGAAACCCGTTGGCGGCGTTTAG
Protein
MRLSHWMALAVLFGGTVTGDIVNELPPEEFDVKIGETVAVSIASNDGFTNTECLIQTPDGGPHSLQELDFIDVITEAGVDCSIKIKVTEEIEGAWTLISRATSFGSPVKRTLPFTINIVPGEHDESDDEKTESEEEKEKEKESEEKQETDEDDGKTIWLTEIRRFTRTEQIVDVSLPNIGYDEICTVITPDRKTITAAEIEIPGVKVQSKSVFVSCRISIGPLKSNLLGKWTLCGRRDGAEERRCQVVTIEWNSENAPHALWDSRTQPLFNHPVNLNGILTPVVIGSGSLLTCHIVTPNGEDLVVLPETKYPGIIRAESGTTGCSIAIGPITQDMLGQWELYGMFRSVLGLNEVRLPMNFELYDTDNPYNQAYNLTVLDAKRHVINLGSTISVEVSGHGTMDNCEFVAPSGQAYQSTGKNNFEGVQFVNVDGITACRISIGPITEVMLGKWQIVGKFNDGNIFNERQLPFEVIREDPANPIDDVDRIVTTIDDRKYDTEIGATHEIIINRGDFIKSESCQIRTPSGRQYTLMDGFNLQGIEIIEDTNVECGIRMTVLSEDMVGEWVLISKVTMLSDPMERRLVFKIHIEERVEPNSASITITEGNDLYLRLKNPVDKQDTCKLIAPNSRAFEIDEPNARLCGFLARAVSDQDSGEWEIQYGDTILYRAVINVNVVERSTIQVQDLTIIEGSKLITEIGPDDLVFCKLEDPLGMTVYEGFGRCVIRVDRATRNHNGKWKMSIGLQGRILLEELTFTVHVRSAGSRQVQTSVRRERPSVVISCSLTSNVEVRACKFRDPRGKVLIASRGVGEDRYAYHGSEVTYKSDLSSHECGIRLTNPSEEDLGLWRCGMETETETHYGFLPVICPWLLDTSEIQDKVVTEPILSADTSYVSSPEGQAVVMSCSVSATIQYCYFRAQNGTVFSVTPGATSTYTEYVGNGFAAGECGVRFDGLLTTDGGRWSCHVGLLDTEQEQRAEITLHIFEQMRVRHYIHPRGLMVEADVETPEELEYCRFVRIDGLGFTSENVPNGYQSMSNLQEGLCALLMRDQTTLNLHPWTVAAKVHGQTEIMRTSTQNLLWTLSQRTATVYSIYLFTVVMFILLATVLVGVSLGPKKNRKWTYDRVSRLSTNIRNSFRKQKPVGGV
Summary
Uniprot
EMBL
Proteomes
Pfam
PF08238 Sel1
Interpro
SUPFAM
SSF48726
SSF48726
Gene 3D
ProteinModelPortal
Ontologies
GO
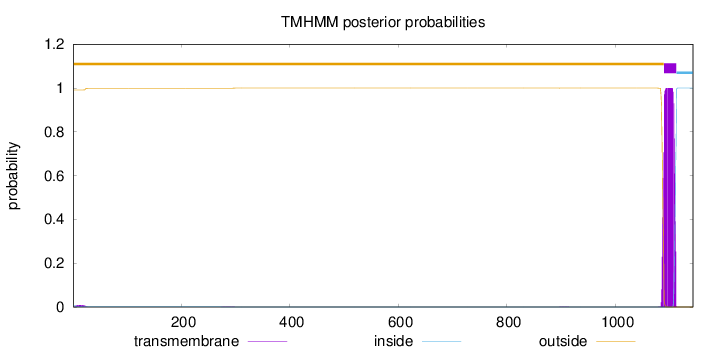
Topology
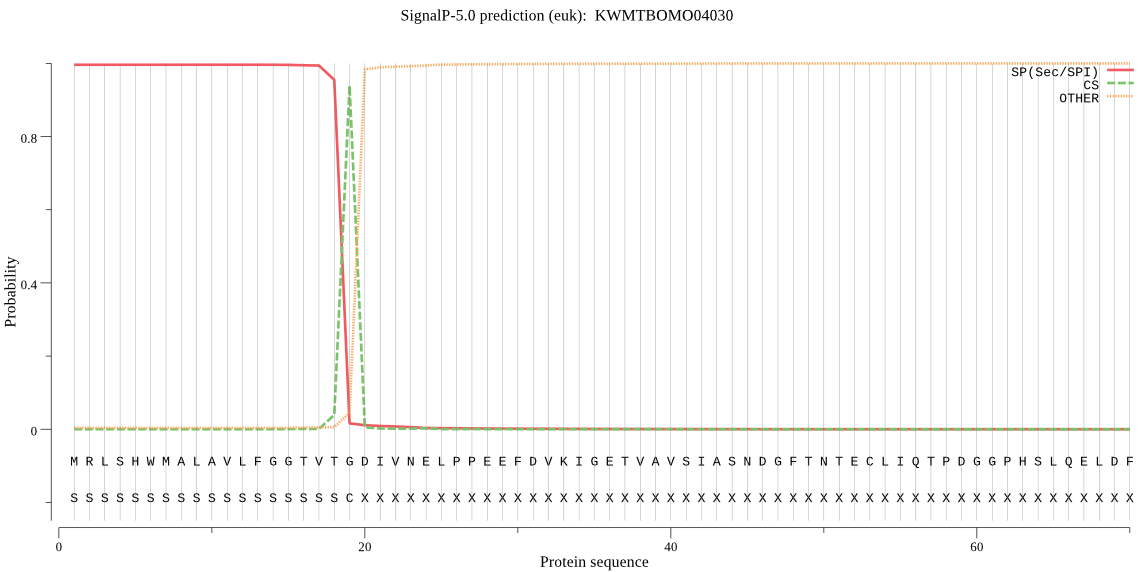
SignalP
Position: 1 - 19,
Likelihood: 0.995924
Length:
1143
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
23.09979
Exp number, first 60 AAs:
0.15458
Total prob of N-in:
0.00882
outside
1 - 1089
TMhelix
1090 - 1112
inside
1113 - 1143
Population Genetic Test Statistics
Pi
208.504547
Theta
168.315703
Tajima's D
0.819956
CLR
0.318295
CSRT
0.609219539023049
Interpretation
Uncertain
