Gene
KWMTBOMO03862
Pre Gene Modal
BGIBMGA010176
Annotation
PREDICTED:_uncharacterized_protein_LOC101740250_isoform_X2_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 4.278
Sequence
CDS
ATGTGCGAGCCTTTAGATATGGATTTAGCTATGGAGGACTTCGAATTTACGCAGGATGAATGGAAGCAAATCAACGCGTTAGAAATTTCTTTTTCGATCGCTTCTATAAACAATGACGCTCTCGTAGAATCGGATAGTGAACCCATGCAATTACCGAAAAAGAAAAGACGTTTGGTTATCGCAAGTGATAGTGATAGTGACAGTGAGTCGGCTGAAAATTTTGTTGCCGCCAATATATCGCAAAATGACCGTATTTCCTCAAAATGGTCGAGGCCAAAAAGACGACAGCCATCAGTGATTCCTTTCACCGAGTTCGAGGGTATGAAACCTCCATATTCTAATTTGCTGAAAGAAGCTGGCCCTGACCAGTATTATGATCTATTGGTGCCTGAAGAAATTCTTGAAATGATTGCTGAGCAGACAAATTTGTTCGCAAGTCAAAACATCACAGCCAGGCAAACAAAGCCTGGATCAAGGTCTCATTCATGGAAGCCAACAAACAAGACAGAAATAAAACAGTTTCTTGGGCTGGTCTTGTTTATGGGCGTAGTAAAGCTGCCGAAATTAGCTTATTATTGGAGCAAAGACAAGATACTTGGACAAACTTTTCCAGCCACCGTTATGAGTAGGAACCGCTTCGAGTTACTACTGCAATACCTACACTTTAGCGACAATTTATCTGTCGACAGAAACGATCGTATTGCCAAAATAAGACCTTTAATCGATGCTCTCAATGCTACTTTCCAGAAATATTATTCACCTAAAGAAGATGTTTGTGTGGATGAAAGCCAAGTACCTTTCAGAGGTCGAATAATATTCAGGCAATACAATAAAAGTAAGCGACACAAGTATGGCATGAAGCTATTTAAGTTATGTACTGTTCCCGGATATACTTGCAAACTTAATTTGTATAGTGGGAAAAACATTGACGCAATAAATACTACGCCAACAAATCTGGTGATGGCACTATGTGAAAATATATTTGACAAAGGACACACGCTAGCAACTGATAATTGGTACACTAGCTTGCAACTGGCTTATCGGTTATTGGAGAAGCAAACCCATTTAATTGGCACATTGCGAAAAAACAGAAGAGGATTGCCTAAGGCTGTTGTTGATTCGAAACTGCAAAAAGGTGAAACAATGGCTATGGAGAATGAAGATGGAGTAACAGTGCTTAAATGGAAAGATAAGAGGGACGTGCTTATGCTGTCGACAAAGCATTCCGACAAAATTGCTGTGGTGGTGAAAAAAGGCAAACAGATTCGTAAACCAAAAGTTATTTTGGATTATAATAAATCGAAAGGGTCTGTAGACATGAGTGACCAGATGGGTGCCTATTCTTCGCCATTGCGGAAAACCGTAAAATGGTATAGAAAATTGGCAATAGAACTACTTCTAAATACGGCAGTTGTAAATGCTTGGGTCATGTACAATGAAAATAAGCAGAGCAAATCTTCAATTGTCGACTTTAGGAGGGCTCTCATAAATTATTTGACTCGGCCAGCAGATTCCCAAGAAATAATTATCAATGAAAGACCTAAAAGACTCAAGCATGTTCTAAAATTAAAGGAAGGAAAAGTAAGAGACACGCGTCGTTTTTGCGTGAAATGTTATAAAGATTCAGTACAGGCATTTGGTCGTAAAGTAGCTAAGAATAAAGCTAAGAAAATGAGCCTCCGAATAGCAAGATGCTTCTCGTACTGTAACACTGAGGGGGAGCTGCACACGTTCACCGACGCCAGCGAGAAGGCCTACGCGTGTGCAGTCTATTGGCGTCAGAGGACAGACGAGAGCACCTACCGCGTCACGCTTCTAGCAGGGAAAGCCAGGGTGACCCCACTGAGACCAGTCTCTATCCCAAAGCTGGAGCTGCAAGCTGCACTGCTGGGGACAAGGATGGCGCAGGCGATAGCGGACGAATTGGACATCGCGGTCGGTGGAAGGACGTACTGGACTGACTCCAGCACAGTCCTGACATGGATAAAGACCGACCCACGCACGTTCAAGCCTTTCGTCGCGCACCGACTTGCCGAGATAGAAGAGTCAACGAAGCCCCAAGAATGGCGATGGGTGCCTGGCTCGCAAAACCCAGCAGACGACGCAACTAGAGAGGCGCCGGCGGATTTCGACCATAGGCATCGGTGGTTTAACGGACCCGAGTTCCTGACGTGGGATGAATCGCGCTGGCCCAAGCCGCGAACATTCAAGCAAGAACCGTCTGGAGAAGAGAAAGAGGCCTTCCTGGTGGCCACGGCGAGGACCGCTGACGCTCGACCCACGCCCGATCCGCACAGATTCTCGAGCTGGGTCAAGTTATTGAGAGCAACAGCCAGGGTCCTCCAATTTATTGAGCTGTGTCGACCCCGGAAGGAGAGCGCCTGCGTGTCCAGACAATTGAAGCAGCAAGATCCCACGTGGAGGACGACACGAACGAAGCAACCCCGATCCACATGGCAGTTAAGGACCCCGGAAGCACCTAAAGAAGCAACGAGCGGCGGTCTGCTTAAGAGACCTGCCTCCAAGATGATCCTGCTGGTGCCTGCAACGAGCGACGAGCCCACGCCCATAGAGTCGCCACTACAAGGAGTCGGTGCTACGCACGAGGGGGAGGATGTATTACAACGCGACGTGGAATGTCATGGACGTATAGTCAGCTCAGTGGTGCGGTTGTGCCGCGGCGGTGACGCAGCCCGCGCCCTAGAACGACGCTGGCATCTCCTGTACCTCCGAGCCATCGAGTGGCAGTGTCACCTAGAGGCCTGTTTGACCAAGATTAACACTCAGGGTGGAACATCAATTGAAGCTGTAAGTGACAGTGATGACGAACCGGCTCTAAAACAACCGAGACTCAGCAGAAAAGGCTCTCCGCGGAGTCCAAGAATACCGAGAAGTCCACGTAGACAACGCACTCCGGTTAATGCTCGCTGCAGAGAAAACTCTACTGACAGTCGACAGTCAGCATCAGAGGAGGAACAAGAATATGTACTGACGTATACGTGGAGGGGATTCGGATCTGACTGCGAATCGGAACTGATGAGGGAACAAAGCAACATGGCAGACGAGAGGAGAGTACCCGGCTCGTTTGAGGACATGGACGTAAGAACCACTGACCAGACTGTACCTGTCACTGTTGACCAACTTGACGGCCTCGATATAAACAGCTCAGTTATTATAGAGGAGAAACTCAAAACGCCACCGACAGTGATTAAACGTAAGAAACCAATAGACACGTCGAAATTCAATCAGACCGATCGAAAATCCAAACATCTAGCAATCTTCTACTTCAAACACCACGATACGGATTCAGACAGACAAGTTATTGAAACGGACGAAAAAAGCCAAGAGGAATCTTCCGAAGAAGAGTGGACGTACGTTGGCGGTGCTAAAATAGCCAACGAAGACTCAACTGATCTGATGACGTCATCTGTGGAAATACAATGTGAGCTACCAGTTGACAATCAGAAAGACACACCGGCATCCCCGAAACTGAAACTAGAATCATCGACGCCTGATTTACTGCGAGTCGAAAATACTAGATGTAAAGACATAGAGAGATTAGTGAACCAGGCTGAAGAAATGGTGCATAAAAAGGCTATGGCAAAGAAGAAGGGAATTAGGAACTTCAAGCCATTGAGCTTGGAAACTGACGGAAAAAATGTTAGCAGGAACAAAATGTCCAGGATCAAGGAATGGCTGAATCAAAGTCCGGATGGAAAGAACGAAAACAATCAGAACACGGAAAGCTATGATGCGTCTGGCGAATACACGACGGAAAGCGAAGTGGACACATCACTTACATCTGAAGAACGGAACCTACACTCCTCCATGGATATGAGCACCTCCACTTGTACAGTAACGCCGACACATCATGCCAAGGTTACATTAAGAAAGAAACGCGCCGGTAACAGCACTAGGCCTTGGTCCGTATCGTGTTTGTCTCAACTGAGCGGTGCGGGCGCATCCCTAGCCGCCACGCCGACAGCGGCGGACGCGCCGAACATGACACACAACATGTCCATATCGGAATCTGCGCTAAACACGCTAGCCTCCCCGCATACAGTCACGCCTTCGAACTCTAACTCGAAATTAAGGGGCAGCTCTACAACTGTACAGGGTCACGTATCAAGCACGAACACAATGACGGAAGCCTGCACGTCGTGCGTCGAAGCCAACGACAAACAGTGCTGGTTACGGCGCAAGCGTTTCAAGCTCCGCCGCCACAACGCACCGCAAAATTCCAGGAGGGAGAGGCTGGTCAAGTCTCTGTCGTTCTGCGGAAGGCTCAGCCCTGAAATAGAAGATAAAAATGAGAGGAGCGCCGCGAGTGACCCGGCTACAAGAAAGAGCAGGTTCGACACGACCTCAACCTCGGGCAACGACAGCGACGAGGAACTGATAAAGCAACAGTTGGCAGCGATGGCGAACCTACGCAAGAGCATCGAGAAGACCCACATATCGACACGCGAAGACGGTGCCATCCCGGAGCAGAACGAACAAAACGATCCAGAAAACACGTCCAAACCCGAATTCAAACTCGGGCCGGCCGGCGGAACGGTTCGACCGAGGTTAGCGAGGAGCTTGGAAAGGGAACGGAACTTCTTGGCGCTAAGCCTCGGCGATCCGAACCAGCTCTGGGATCTGAGTTTGGACAAAGATTCGGACGTGGACAAAAGCGTGACGGCTGGCACAGAAGAGCACAGCTCGTTCTCGGAACAAGCCTGGGACTTTTATCAAGTGAGTCTAGGCTCTTAA
Protein
MCEPLDMDLAMEDFEFTQDEWKQINALEISFSIASINNDALVESDSEPMQLPKKKRRLVIASDSDSDSESAENFVAANISQNDRISSKWSRPKRRQPSVIPFTEFEGMKPPYSNLLKEAGPDQYYDLLVPEEILEMIAEQTNLFASQNITARQTKPGSRSHSWKPTNKTEIKQFLGLVLFMGVVKLPKLAYYWSKDKILGQTFPATVMSRNRFELLLQYLHFSDNLSVDRNDRIAKIRPLIDALNATFQKYYSPKEDVCVDESQVPFRGRIIFRQYNKSKRHKYGMKLFKLCTVPGYTCKLNLYSGKNIDAINTTPTNLVMALCENIFDKGHTLATDNWYTSLQLAYRLLEKQTHLIGTLRKNRRGLPKAVVDSKLQKGETMAMENEDGVTVLKWKDKRDVLMLSTKHSDKIAVVVKKGKQIRKPKVILDYNKSKGSVDMSDQMGAYSSPLRKTVKWYRKLAIELLLNTAVVNAWVMYNENKQSKSSIVDFRRALINYLTRPADSQEIIINERPKRLKHVLKLKEGKVRDTRRFCVKCYKDSVQAFGRKVAKNKAKKMSLRIARCFSYCNTEGELHTFTDASEKAYACAVYWRQRTDESTYRVTLLAGKARVTPLRPVSIPKLELQAALLGTRMAQAIADELDIAVGGRTYWTDSSTVLTWIKTDPRTFKPFVAHRLAEIEESTKPQEWRWVPGSQNPADDATREAPADFDHRHRWFNGPEFLTWDESRWPKPRTFKQEPSGEEKEAFLVATARTADARPTPDPHRFSSWVKLLRATARVLQFIELCRPRKESACVSRQLKQQDPTWRTTRTKQPRSTWQLRTPEAPKEATSGGLLKRPASKMILLVPATSDEPTPIESPLQGVGATHEGEDVLQRDVECHGRIVSSVVRLCRGGDAARALERRWHLLYLRAIEWQCHLEACLTKINTQGGTSIEAVSDSDDEPALKQPRLSRKGSPRSPRIPRSPRRQRTPVNARCRENSTDSRQSASEEEQEYVLTYTWRGFGSDCESELMREQSNMADERRVPGSFEDMDVRTTDQTVPVTVDQLDGLDINSSVIIEEKLKTPPTVIKRKKPIDTSKFNQTDRKSKHLAIFYFKHHDTDSDRQVIETDEKSQEESSEEEWTYVGGAKIANEDSTDLMTSSVEIQCELPVDNQKDTPASPKLKLESSTPDLLRVENTRCKDIERLVNQAEEMVHKKAMAKKKGIRNFKPLSLETDGKNVSRNKMSRIKEWLNQSPDGKNENNQNTESYDASGEYTTESEVDTSLTSEERNLHSSMDMSTSTCTVTPTHHAKVTLRKKRAGNSTRPWSVSCLSQLSGAGASLAATPTAADAPNMTHNMSISESALNTLASPHTVTPSNSNSKLRGSSTTVQGHVSSTNTMTEACTSCVEANDKQCWLRRKRFKLRRHNAPQNSRRERLVKSLSFCGRLSPEIEDKNERSAASDPATRKSRFDTTSTSGNDSDEELIKQQLAAMANLRKSIEKTHISTREDGAIPEQNEQNDPENTSKPEFKLGPAGGTVRPRLARSLERERNFLALSLGDPNQLWDLSLDKDSDVDKSVTAGTEEHSSFSEQAWDFYQVSLGS
Summary
Uniprot
ProteinModelPortal
Ontologies
GO
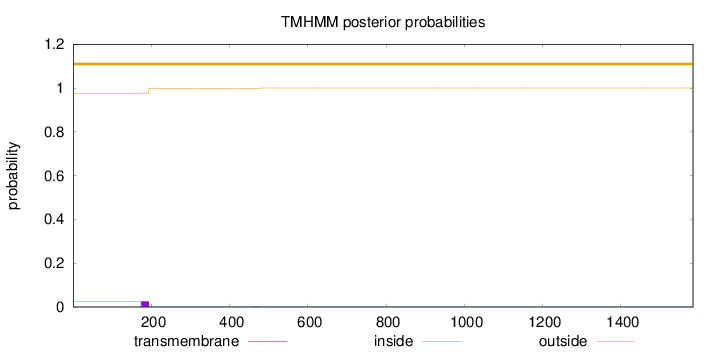
Topology
Length:
1584
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.539169999999999
Exp number, first 60 AAs:
0.00017
Total prob of N-in:
0.02624
outside
1 - 1584
Population Genetic Test Statistics
Pi
318.606298
Theta
194.284796
Tajima's D
2.684148
CLR
0.532092
CSRT
0.95895205239738
Interpretation
Uncertain
