Gene
KWMTBOMO03433
Pre Gene Modal
BGIBMGA006367
Annotation
PREDICTED:_protein_unc-80_homolog_[Amyelois_transitella]
Full name
Protein unc-80 homolog
Location in the cell
Nuclear Reliability : 2.909
Sequence
CDS
ATGTCACGAAGATGCTCAGCGGAAGGCGGGTCGGGTGGTGGTGAGTCTGAAGTGGTGGTGCTGAAGCGGAGACGTCTGGTGGCGGCGGCGCCCCTGTACGCGGGGCTGGCGCGGTTCAGCTTCATGCTGGACGCCACGCAGCCGGGGGCCACGCCCGACGCGCTTTTCATGGCCGCACTCTTAGATTTACCACACACAGCGGTCGTAGGAAGAGCAGCTATTATGTTAGAATGTGCTCATTTAGTACACAACTGTAACAAAGGGCAATGGCCGTATTGGCTGAAATCTAACGTGAAGGGAGCAACTTCATTAAGCCCCCAACTCAGAAGACAACGGCTCGCTGGTAAACTTTTCTATCAATGGGCTGAAGCTATAGGAAACCGACTTGAAGAGATGTTGATTGAGGACAAGAAACACATCGAAACTGTCGTTAATTTGGTAAACGACCCGGATGGACAGCGCGAGCTTCTGCAGCAAGACGAGGAAGAAGACTTTCTAGACGAAGCCAGTATTCGTTTGCCTGGAAAACCGATTGGCGCCGATTGCCCTCGAGCGCTAAGAATCGTAGCCTGTGTGCTGTTGTTCGAAATCACTGCCTTTCTTCGCGAGACTTACCAAAGCTTGCCCAAGACATTCCGATCGTCTTTGAAAGAAAGAGGACCTTGGGACAGAGTCTACAGGGAAGCGAATCGTCGATGGAGTATGGCTTTATCGAGCATGGGACACTCACAAGCGTCCGCACAAAGCCTCCAGTCGATTGCAGGAGCTGAGACTGAAAGGAAAATATCTTTTGTTCTACATGAACCCGAAAATGTCTCTGGAGGCAGTAATGTCACTTTGGCAGATGCCATACCACCGATACAGGATGAGAAACGAGGGAAACTAGGGTCGAGGGGGAAGGGGGGAATGCATCGTCGCAACACACAGCAGGCGCATTCCGCCTACGGATCCTTCAAGAGACGCTCTATCAAACTGAGGCAGAAGGACAACAGGGAGGTCGATGAATTTATCACAAGAAGATCAGATTCCATACAAAGCAAACGTAAAGTATCGTCTCTCTCAGACCGGAGCGACACTTCAGAAGTCTATCCAGGAGCTGGAGGTACTGTAATAATGCCCAACGAAGTGGATAGCGGTGGTGAAGAAAGTCCCGGGGTGTTATCTGATGATCACGATCACCCGCCCGACAGTCCCGACAGCAACTCCACTGATCCCCCGGATACTAACAAGGGCTTCCCCTGGCTTAAGGTGATGGTGAAATTTTTGAATTCCTTCAATTACGTTTGCTGCCATCAAAACTTCTGCCACCCGTATTGTTTCCGGCGCAACATGCGAGCGAGTACGAGACTTATGAAGTCAGTACTTAAGATTTACGGAGAGAAGTTTGGTCCAGAACAAAACGCGGCAAGTTCTGAAGAATGTGTCGGCGAAGCTCGTCGTGGTAGACGAACACGGAAACCATCCGAACATTGCACTGATAGGATTGACAGATCGGTAATAGAGAGCGCTGGTCTCGCGTACAGAGCGGCGGGGGGCGAGCACGCGCTCCCGCACGCAGACGCGCCGCCCGCCGCCAAGCCAGGAGCTGTGCCCTATCCCCCTGGCGACCCCCCAGCCATACTGAAGTATCTCAAGGGGCAGGTTCGTGAAGCGTATCACACTCCACTTGCAACGCTAATCAAAGGAGCGACCACGATGAGTGAAGAAATGTTCGCCGAATCAGCTCGAGTGGCTTGGCAGCTGCTGTTAGAGTCGGACAGGGAACTGAGCTCGTGTGCGGCGGCGCTTTTTATATTGGCGGCCGTGAAAGCCCCTCAAGTTGCCACCGAGATAATGCATAATGATCTGAAGCACACCGAACCGGGGATAAGGATCAACGCTATTCTAAGGTTCCAAGTAATATGGAAACTCCGTTATCAAGTCTGGCCTCGTATGGAAGAAGGAGCGTCCATGACGTTTAAAGTTCCACCACCCGGCATCGAGTTTACACTGCCTTCGCCGAAGATCGGTATAGAGTCTTTAGCCGTTGTTGACCCACCATGGAGTCCACTCGTCAAAGACAAGGATATGGAGATGACGCTAAATCAAGAAAGACATCGTTCGTTAGTAACAGCAACGAAAACGCGCAAGAAACAACAGACCGAAGCGATGAAACTGGCACTACAGCAACAGAACGACAAGAAACGCGCCGAAAGAGAGAGCTTCCTCATCACCACCATACCCATCACGAGACAGGCCGCCAGGGAACCGGCTCTGGATCACGCGGCTGATGATCATATTGAACCACCAGCCGACGAAGAGATAGTAGAAGGCGTGCGGGGCACTCACCACACTCAAGCGGCGTCAGCTCTGTTCCCTTCTACTCTGTGCTCGGCGGTGGCGGAGATAGTTGCATTGTTGGACGACGCGGCTGTGTCCAGAGATGGATGCTCCGTGTATGAAGTTGCTTATCAGGTGATCTGGTGTTGTCTAGTGGAGGACTCTGCTTTATTCCTCCGTCATGTCCTCGAACGTCTAACGAGAGATCACCAGGACGAGATGTTCAAACTGCTCCGGCACCTGATAAGATTCATACCGCGCCTGCCGCAACAGGCGGCTTTCGCTCTCTATAACTACATCATTGGCTACGTCATGTTTTACGTGAGGAGTCCGCACGAGGAGGGACAGAGGCTGGTCGGTGCCGCGCTATCTATATTATGGATGGTAGTACACAGCGTGCATGGTATAATGTTTAAGGATTTGAAGCAAATCTTACGTAAAGAACAATGTGACGCATCCATATTGCTAACGGCGAACGTGCCAGCTGCCAAGAAGATTATTGTTCATGGTCCATCTGATAACGAAGGAAGCATCCCATCACAATTTCCTGTCCAAGAGGATACAGTGTTTGCTCAAATTTTGAAAGAATCCTTAGACTTCTTCAGTATACCAGAAAAATTGCACAAGGAACACTTTCTTGTTGATTTCAAAACGCGTCAAATCCACAACCCTCAGAATTACGTGCGTGATCACTATTTCTTCAAACGTTCGCAATATCCTCAGCTAGGCCTAGTCCACATGGAACCCGAGGAGGCGTTCAACAAACTGCAACAGCAAGAATTGCTTCTCAAGTTCATAGAAATAGGAAAAGTTTTGCTCACTTGGGCGATTCTCAAAAATGTTGATATGGTGGTACAGAGAGTGGTATTCTTGCACGACGAACTTATGAAACTACCCTCGTTTCCTCGCAAAGCACTCGAAGCCGATCTAACGTTGTACAGTCGGGGACACCTTGGCACCACTTTATTGGGACTCGATGTATTACACAAATTTATGTGGGTTCGTTTGATCGCACGCATGTTCGAAGCGATGGCCGGAAACTTCACGTCTTCACGCGACATACATTTGTTTTTGAACGTATTGAACGGTGCATTAATGCTTCACAGTGAAGACGCATTAATATTAAGATACGTTATTGCTACGTACGTAAACGCTGCATCGAACTTCAAAAGTATATTCTCAACAAATGGGTATTTACTGATCATGCCAACACTACTTCAAATCTATTCAAATTTTCAAACAAACAAACTTGTAACAACTACAATTGAATACGCAGTGAAACAATTTTACTTATTGAATAGAAAACCATTTATACTACAAATGTTCGGATCAGTGTCGGCCATATTGGATACTGATGAAGAATCTATTTACGGGGACGCAAGCAAAGTGCAGTCCAGTTGTTTGTTCAACTTGCTTCTCAGCTTAGAAACGCCGTCCCCGGATCCACTACACATAGCCGAACTAATCAAAGAGGACAAACCTTTGAAACCAATAGATTTTTGCTACCGTGACGAAGAGGAGATGGTCAACGTACTGGACTGCATCAGTTTGTGTGTGATGGTCGTATCATATTCAGCCGAGAGTTTCAGAGGGTATCAAATGTTGATAATACTGGAAGCAATATTGCCTTGCTACGTCAAGCAAATAGAGTCTCCCACTTATAACAGAGAAGGTAAAACGGAGAAAGAGATTATTCAACAGCTCGCCATTGCCATTAAAACTCTGGTCAACAACTGCGAGGGATTATCCAAATCGTACAATGGGCCGTATCGGACATCGCCCGAACATAAGGGTTCGTCCCAGAGAGCCGGTCAACGTACCACGGCCGCCACGATCATAGCTTTTGAAGAATCGCATTCAAAATTCGACAACTCCAAGCTGCCAGTGCAAGAATACACTGGTACCGAAGACTCGGAACTGGTGCGCGCAGAATACCGTCGTCCTAGAGACGTGCTGTTGTCGTTGGTCGGCAACTTCATAGGGCACGCCACCGCGCGCCTCATTGAACTGAACGGGTCCAAGGGCAGCGGCGGCAGCGAGGGCAAACCCGTCGAACTCTTGGACTGCAAGTCACACGCTCGCTTAGCCGAGATAGCCCACTCCCTGCTGAAGGTGTCGCCGTACGACCCCGAGTCGATGGGCTGCCGCGGGCTGCAGCGGTACATGATGGACGTGCTGCCCGCCGCCGACTGGGAGAACGACGCGCTGCGGCCCGCGCTCAACATGATCCTGCGCCGGCTCGATAAGGTCTTCCTGAAGATCGCCAAGAAACCGAGCATACGGAGGAATACAGCATGGGATTCAGCAGCGACATTACTGAAAGGCGTGTACGAAACGATGACGCGATGCACGTACATAATGCAGTGGCCACAAGTGAAGACTCTCCTCAATACGATCCAAGCGTTGATAGTGTCGGATAACAACAGCGGCGAGAACTTGTCTTCCGCGACTGCCGCGCTGATGTCTCAGCCGCCACCTCCACACTTTTGCAGCACCGTCGTCCGACTAATTGCACTGCAAGTCATTAACACCGGGGATAGCTACTCTTTAGAACAAATGTGTGGTGGCAGCGCGATATTTCCTACAGCCGAGAAAACGGAGAATATGCTTATGAATCTATTCATGCCTCTGTGCTTAAGAGTCGGCAGTGGGAGAAAAGACGTTCCTCCGTTGCGGCAGTCGGACGTGAGCTACTTGGTGTCGGTGGTGCTGAACGCGCTGTGCCCGCCGGCGCCGCCCGGGCAGCTCGCGGCCGTCAACGCCAAACTGAACGCGTCCGACGCGCGCGTCAACTCGCTCACCTTCACCGGCAGCAGGGACACCAGGAACACGACCAGGCTGTCCAACCAACTCTACCGGATCGCGTTCCTAGCGTTGAAGGTGTTGTGCGCGTGCTTCACGAGCGAGCTGTGCTCGGAGTGGGGGAGGATAGCGCGCGCCATGCGGGAGCTCGGCCGCCGGAACGAGGCAGCGCATCACTTGTGGGACTTCCTCGAGCACGTGGTCACCTACCGCACGCCGCTCTACATACTGCTACAGCCCTTCATCGTGCACAAATTGTCCCAGCCGCCGATCGGCGACAACGAGCGTCACATGCAGTTCGTGGTCCGCGAGCGCGTCCGCGGCCTCAAGCTGCCCGCGGCCCGCGCGCGCGGCGCCCTACTCGCGGAACTCGCACGGGAACTCCGCAACATGAGAGAGACACACGACCAGTTTAAATTCGAACAAATAGCTGAAAATCTTGGACAAGCGGGGGGTAAGCGCGCGTCTGAAGTGTTCCCGCGGCCTCCAAACATGTCGGACAAACATCAACAGCACCGGCCCTCGTTGATCTCCATGCTGGTGGGGCGGACCGGCGCGAGCATTCCGCGCACCCCCGACCATCCCTCGGCACCCCTATCTGCCCAAAGAGCTTTTGTATATTCAGAGTCACTGTCGAGCAGTTCAACGACCAGCCAACAGATGCCCACTTTCGACGTGCCTCTGATCAGTGGACGACTCAATGACAACGGCACGAACAACACGAGCAGCATCAACTCTAATATAGGTTCGCTGAACAATTACGGCAGCGATACAAAGCTCGCGGTGAGCACACCGTCGTACACGAGCGCACCCGCCAAGTTACGGTTCGTTCCTTCCGTCGAGCTGAAGTTCACGTCGGAGCAAGGCGAAGGGTCCAGGCCGTTCTCGCCGCTGTCGCCCGGAGACACGTCGTGCGGGGAAGCGCGGGGAGGAGGAGGCACGGACAGCCCTGACGACCGGCCTCGTCTGCAACGGGCCCACGGGCCTTCAAAGAAAACATTCAAGTTCCGCCGCAGCCGACACACCAAGCCGGACGCTCGTCTGGAATCTGACGAAGGTTCATCTCCCGGCGAGGGGAGACGGCTGAGCGTTGCGCCGTTACTGCAAGCCCAACCATTTCCGGATACGTCGTGTGACAGTGAACCTTCGCAAACTTCCTCTACGTCCGGATACAGGGAGAGCTACAGCCTGCAGGCCAGCATGGCGGAGTCCCCGGGCGGCACGTGCCGAGCGGCGCCCCGCAGCGCCAGCACCACGCCGCACGCCAGCCCCGACGCATCTCTAAGTTATGAATCTGGAACATCATCCGCTGAACGTACCGCGCTACTCGGAGCTGCTAGCCAGCGTTCCCTTTTGCTAAGTGGCGACTTAAGAGATGAAGATACTTTACTTTAA
Protein
MSRRCSAEGGSGGGESEVVVLKRRRLVAAAPLYAGLARFSFMLDATQPGATPDALFMAALLDLPHTAVVGRAAIMLECAHLVHNCNKGQWPYWLKSNVKGATSLSPQLRRQRLAGKLFYQWAEAIGNRLEEMLIEDKKHIETVVNLVNDPDGQRELLQQDEEEDFLDEASIRLPGKPIGADCPRALRIVACVLLFEITAFLRETYQSLPKTFRSSLKERGPWDRVYREANRRWSMALSSMGHSQASAQSLQSIAGAETERKISFVLHEPENVSGGSNVTLADAIPPIQDEKRGKLGSRGKGGMHRRNTQQAHSAYGSFKRRSIKLRQKDNREVDEFITRRSDSIQSKRKVSSLSDRSDTSEVYPGAGGTVIMPNEVDSGGEESPGVLSDDHDHPPDSPDSNSTDPPDTNKGFPWLKVMVKFLNSFNYVCCHQNFCHPYCFRRNMRASTRLMKSVLKIYGEKFGPEQNAASSEECVGEARRGRRTRKPSEHCTDRIDRSVIESAGLAYRAAGGEHALPHADAPPAAKPGAVPYPPGDPPAILKYLKGQVREAYHTPLATLIKGATTMSEEMFAESARVAWQLLLESDRELSSCAAALFILAAVKAPQVATEIMHNDLKHTEPGIRINAILRFQVIWKLRYQVWPRMEEGASMTFKVPPPGIEFTLPSPKIGIESLAVVDPPWSPLVKDKDMEMTLNQERHRSLVTATKTRKKQQTEAMKLALQQQNDKKRAERESFLITTIPITRQAAREPALDHAADDHIEPPADEEIVEGVRGTHHTQAASALFPSTLCSAVAEIVALLDDAAVSRDGCSVYEVAYQVIWCCLVEDSALFLRHVLERLTRDHQDEMFKLLRHLIRFIPRLPQQAAFALYNYIIGYVMFYVRSPHEEGQRLVGAALSILWMVVHSVHGIMFKDLKQILRKEQCDASILLTANVPAAKKIIVHGPSDNEGSIPSQFPVQEDTVFAQILKESLDFFSIPEKLHKEHFLVDFKTRQIHNPQNYVRDHYFFKRSQYPQLGLVHMEPEEAFNKLQQQELLLKFIEIGKVLLTWAILKNVDMVVQRVVFLHDELMKLPSFPRKALEADLTLYSRGHLGTTLLGLDVLHKFMWVRLIARMFEAMAGNFTSSRDIHLFLNVLNGALMLHSEDALILRYVIATYVNAASNFKSIFSTNGYLLIMPTLLQIYSNFQTNKLVTTTIEYAVKQFYLLNRKPFILQMFGSVSAILDTDEESIYGDASKVQSSCLFNLLLSLETPSPDPLHIAELIKEDKPLKPIDFCYRDEEEMVNVLDCISLCVMVVSYSAESFRGYQMLIILEAILPCYVKQIESPTYNREGKTEKEIIQQLAIAIKTLVNNCEGLSKSYNGPYRTSPEHKGSSQRAGQRTTAATIIAFEESHSKFDNSKLPVQEYTGTEDSELVRAEYRRPRDVLLSLVGNFIGHATARLIELNGSKGSGGSEGKPVELLDCKSHARLAEIAHSLLKVSPYDPESMGCRGLQRYMMDVLPAADWENDALRPALNMILRRLDKVFLKIAKKPSIRRNTAWDSAATLLKGVYETMTRCTYIMQWPQVKTLLNTIQALIVSDNNSGENLSSATAALMSQPPPPHFCSTVVRLIALQVINTGDSYSLEQMCGGSAIFPTAEKTENMLMNLFMPLCLRVGSGRKDVPPLRQSDVSYLVSVVLNALCPPAPPGQLAAVNAKLNASDARVNSLTFTGSRDTRNTTRLSNQLYRIAFLALKVLCACFTSELCSEWGRIARAMRELGRRNEAAHHLWDFLEHVVTYRTPLYILLQPFIVHKLSQPPIGDNERHMQFVVRERVRGLKLPAARARGALLAELARELRNMRETHDQFKFEQIAENLGQAGGKRASEVFPRPPNMSDKHQQHRPSLISMLVGRTGASIPRTPDHPSAPLSAQRAFVYSESLSSSSTTSQQMPTFDVPLISGRLNDNGTNNTSSINSNIGSLNNYGSDTKLAVSTPSYTSAPAKLRFVPSVELKFTSEQGEGSRPFSPLSPGDTSCGEARGGGGTDSPDDRPRLQRAHGPSKKTFKFRRSRHTKPDARLESDEGSSPGEGRRLSVAPLLQAQPFPDTSCDSEPSQTSSTSGYRESYSLQASMAESPGGTCRAAPRSASTTPHASPDASLSYESGTSSAERTALLGAASQRSLLLSGDLRDEDTLL
Summary
Description
Component of the na (narrow abdomen) sodium channel complex. In the circadian clock neurons it functions with na and unc79 to promote circadian rhythmicity.
Subunit
Interacts with unc79 and na. Can interact with unc79 independently of na.
Similarity
Belongs to the unc-80 family.
Keywords
Complete proteome
Membrane
Reference proteome
Transmembrane
Transmembrane helix
Feature
chain Protein unc-80 homolog
Uniprot
A0A2A4JCE8
A0A2A4JBF5
A0A2A4JBI4
A0A2A4JD08
A0A194PXL4
A0A2H1V856
+ More
A0A212F3A3 A0A194RNK8 A0A139WNA1 A0A139WNA3 A0A139WNP9 D7EIC7 A0A1Y1MLL3 A0A1Y1ME41 A0A182N426 A0A182QX20 Q16MS2 W5J732 A0A182TL33 A0A182GR59 A0A182F7L8 A0A182MTD3 A0A182JQJ5 A0A182VZ79 A0A182IQ49 A0A182PGS7 A0A182UPQ0 F5HML1 Q8T5I0 A0A182WSD6 A0A182HL87 A0A1B6DLL7 A0A1B6C773 A0A1B6C7W4 A0A084VFZ1 B0X1Z5 A0A336K3J7 K7IXP9 B4GNX6 A0A3L8DLM5 B4JRX7 E0VJG7 A0A1I8PB18 A0A1I8PB72 A0A1I8PB64 A0A1I8PB09 A0A1I8PB14 A0A1I8PB08 A0A1I8PB77 A0A1I8PB17 A0A1I8PB33 A0A1I8PB82 A0A1I8PB59 A0A2A3E5T5 A0A1I8PB13 A0A1W4UPQ4 A0A1W4UPZ1 A0A1W4URK7 A0A1W4UCL6 A0A1W4UCM1 A0A1W4UPP8 A0A1W4URK2 A0A182R661 A0A034VR23 A0A1W4UCM6 B4KB92 A0A0R1E847 A0A0B4KHR1 A0A0B4KH56 A0A0R1E5K1 A0A0R1E9G6 A0A0R1E518 A0A1W4UD65 A0A0B4KI46 A0A0R1EA26 A0A0R1E4Y7 B4PRB5 A0A0R1E4Z1 A0A1W4UPQ8 A0A0R1E6A3 B3LX38 B4IGU7 Q9VB11 A0A1W4UPZ8 B4M624 A0A0R1EA21 A0A0R1E4Z3 A0A0R1E5F2 A0A0B4KHA4 B4NAR2 A0A0R3NKC8 Q29BG7 B3P5Y9 A0A0R3NKF9 A0A3B0JF06 A0A3B0JEF5 A0A3B0KAW1 A0A0R3NFD4 A0A0R3NLI1 A0A0R3NF00
A0A212F3A3 A0A194RNK8 A0A139WNA1 A0A139WNA3 A0A139WNP9 D7EIC7 A0A1Y1MLL3 A0A1Y1ME41 A0A182N426 A0A182QX20 Q16MS2 W5J732 A0A182TL33 A0A182GR59 A0A182F7L8 A0A182MTD3 A0A182JQJ5 A0A182VZ79 A0A182IQ49 A0A182PGS7 A0A182UPQ0 F5HML1 Q8T5I0 A0A182WSD6 A0A182HL87 A0A1B6DLL7 A0A1B6C773 A0A1B6C7W4 A0A084VFZ1 B0X1Z5 A0A336K3J7 K7IXP9 B4GNX6 A0A3L8DLM5 B4JRX7 E0VJG7 A0A1I8PB18 A0A1I8PB72 A0A1I8PB64 A0A1I8PB09 A0A1I8PB14 A0A1I8PB08 A0A1I8PB77 A0A1I8PB17 A0A1I8PB33 A0A1I8PB82 A0A1I8PB59 A0A2A3E5T5 A0A1I8PB13 A0A1W4UPQ4 A0A1W4UPZ1 A0A1W4URK7 A0A1W4UCL6 A0A1W4UCM1 A0A1W4UPP8 A0A1W4URK2 A0A182R661 A0A034VR23 A0A1W4UCM6 B4KB92 A0A0R1E847 A0A0B4KHR1 A0A0B4KH56 A0A0R1E5K1 A0A0R1E9G6 A0A0R1E518 A0A1W4UD65 A0A0B4KI46 A0A0R1EA26 A0A0R1E4Y7 B4PRB5 A0A0R1E4Z1 A0A1W4UPQ8 A0A0R1E6A3 B3LX38 B4IGU7 Q9VB11 A0A1W4UPZ8 B4M624 A0A0R1EA21 A0A0R1E4Z3 A0A0R1E5F2 A0A0B4KHA4 B4NAR2 A0A0R3NKC8 Q29BG7 B3P5Y9 A0A0R3NKF9 A0A3B0JF06 A0A3B0JEF5 A0A3B0KAW1 A0A0R3NFD4 A0A0R3NLI1 A0A0R3NF00
Pubmed
EMBL
NWSH01002013
PCG69436.1
PCG69437.1
PCG69435.1
PCG69434.1
KQ459589
+ More
KPI97499.1 ODYU01001175 SOQ37033.1 AGBW02010586 OWR48218.1 KQ459896 KPJ19423.1 KQ971310 KYB29508.1 KYB29509.1 KYB29507.1 EFA11788.2 GEZM01033851 JAV84087.1 GEZM01033850 JAV84089.1 AXCN02000022 CH477851 EAT35636.1 ADMH02001961 ETN60267.1 JXUM01081933 JXUM01081934 JXUM01081935 KQ563278 KXJ74140.1 AXCM01003048 AAAB01008987 EGK97533.1 AJ439353 CAD27932.1 EAA00911.2 APCN01000884 GEDC01010741 JAS26557.1 GEDC01028119 JAS09179.1 GEDC01027705 JAS09593.1 ATLV01012582 ATLV01012583 ATLV01012584 KE524806 KFB36885.1 DS232275 EDS38925.1 UFQS01000014 UFQT01000014 SSW97293.1 SSX17679.1 CH479186 EDW38859.1 QOIP01000007 RLU21092.1 CH916373 EDV94517.1 DS235222 EEB13523.1 KZ288357 PBC27123.1 GAKP01014707 JAC44245.1 CH933806 EDW16820.2 CM000160 KRK04291.1 AE014297 AGB96404.1 AGB96403.1 KRK04287.1 KRK04289.1 KRK04285.1 AGB96405.1 KRK04290.1 KRK04283.1 EDW98479.2 KRK04284.1 KRK04286.1 CH902617 EDV43877.2 CH480837 EDW49065.1 CH940652 EDW59100.2 KRK04292.1 KRK04288.1 KRK04293.1 AGB96402.1 CH964232 EDW80876.2 CM000070 KRS99732.1 EAL27031.4 CH954182 EDV53389.1 KRS99740.1 OUUW01000005 SPP80705.1 SPP80707.1 SPP80708.1 KRS99738.1 KRS99733.1 KRS99736.1
KPI97499.1 ODYU01001175 SOQ37033.1 AGBW02010586 OWR48218.1 KQ459896 KPJ19423.1 KQ971310 KYB29508.1 KYB29509.1 KYB29507.1 EFA11788.2 GEZM01033851 JAV84087.1 GEZM01033850 JAV84089.1 AXCN02000022 CH477851 EAT35636.1 ADMH02001961 ETN60267.1 JXUM01081933 JXUM01081934 JXUM01081935 KQ563278 KXJ74140.1 AXCM01003048 AAAB01008987 EGK97533.1 AJ439353 CAD27932.1 EAA00911.2 APCN01000884 GEDC01010741 JAS26557.1 GEDC01028119 JAS09179.1 GEDC01027705 JAS09593.1 ATLV01012582 ATLV01012583 ATLV01012584 KE524806 KFB36885.1 DS232275 EDS38925.1 UFQS01000014 UFQT01000014 SSW97293.1 SSX17679.1 CH479186 EDW38859.1 QOIP01000007 RLU21092.1 CH916373 EDV94517.1 DS235222 EEB13523.1 KZ288357 PBC27123.1 GAKP01014707 JAC44245.1 CH933806 EDW16820.2 CM000160 KRK04291.1 AE014297 AGB96404.1 AGB96403.1 KRK04287.1 KRK04289.1 KRK04285.1 AGB96405.1 KRK04290.1 KRK04283.1 EDW98479.2 KRK04284.1 KRK04286.1 CH902617 EDV43877.2 CH480837 EDW49065.1 CH940652 EDW59100.2 KRK04292.1 KRK04288.1 KRK04293.1 AGB96402.1 CH964232 EDW80876.2 CM000070 KRS99732.1 EAL27031.4 CH954182 EDV53389.1 KRS99740.1 OUUW01000005 SPP80705.1 SPP80707.1 SPP80708.1 KRS99738.1 KRS99733.1 KRS99736.1
Proteomes
UP000218220
UP000053268
UP000007151
UP000053240
UP000007266
UP000075884
+ More
UP000075886 UP000008820 UP000000673 UP000075902 UP000069940 UP000249989 UP000069272 UP000075883 UP000075881 UP000075920 UP000075880 UP000075885 UP000075903 UP000007062 UP000076407 UP000075840 UP000030765 UP000002320 UP000002358 UP000008744 UP000279307 UP000001070 UP000009046 UP000095300 UP000242457 UP000192221 UP000075900 UP000009192 UP000002282 UP000000803 UP000007801 UP000001292 UP000008792 UP000007798 UP000001819 UP000008711 UP000268350
UP000075886 UP000008820 UP000000673 UP000075902 UP000069940 UP000249989 UP000069272 UP000075883 UP000075881 UP000075920 UP000075880 UP000075885 UP000075903 UP000007062 UP000076407 UP000075840 UP000030765 UP000002320 UP000002358 UP000008744 UP000279307 UP000001070 UP000009046 UP000095300 UP000242457 UP000192221 UP000075900 UP000009192 UP000002282 UP000000803 UP000007801 UP000001292 UP000008792 UP000007798 UP000001819 UP000008711 UP000268350
PRIDE
Pfam
PF15778 UNC80
SUPFAM
SSF48371
SSF48371
ProteinModelPortal
A0A2A4JCE8
A0A2A4JBF5
A0A2A4JBI4
A0A2A4JD08
A0A194PXL4
A0A2H1V856
+ More
A0A212F3A3 A0A194RNK8 A0A139WNA1 A0A139WNA3 A0A139WNP9 D7EIC7 A0A1Y1MLL3 A0A1Y1ME41 A0A182N426 A0A182QX20 Q16MS2 W5J732 A0A182TL33 A0A182GR59 A0A182F7L8 A0A182MTD3 A0A182JQJ5 A0A182VZ79 A0A182IQ49 A0A182PGS7 A0A182UPQ0 F5HML1 Q8T5I0 A0A182WSD6 A0A182HL87 A0A1B6DLL7 A0A1B6C773 A0A1B6C7W4 A0A084VFZ1 B0X1Z5 A0A336K3J7 K7IXP9 B4GNX6 A0A3L8DLM5 B4JRX7 E0VJG7 A0A1I8PB18 A0A1I8PB72 A0A1I8PB64 A0A1I8PB09 A0A1I8PB14 A0A1I8PB08 A0A1I8PB77 A0A1I8PB17 A0A1I8PB33 A0A1I8PB82 A0A1I8PB59 A0A2A3E5T5 A0A1I8PB13 A0A1W4UPQ4 A0A1W4UPZ1 A0A1W4URK7 A0A1W4UCL6 A0A1W4UCM1 A0A1W4UPP8 A0A1W4URK2 A0A182R661 A0A034VR23 A0A1W4UCM6 B4KB92 A0A0R1E847 A0A0B4KHR1 A0A0B4KH56 A0A0R1E5K1 A0A0R1E9G6 A0A0R1E518 A0A1W4UD65 A0A0B4KI46 A0A0R1EA26 A0A0R1E4Y7 B4PRB5 A0A0R1E4Z1 A0A1W4UPQ8 A0A0R1E6A3 B3LX38 B4IGU7 Q9VB11 A0A1W4UPZ8 B4M624 A0A0R1EA21 A0A0R1E4Z3 A0A0R1E5F2 A0A0B4KHA4 B4NAR2 A0A0R3NKC8 Q29BG7 B3P5Y9 A0A0R3NKF9 A0A3B0JF06 A0A3B0JEF5 A0A3B0KAW1 A0A0R3NFD4 A0A0R3NLI1 A0A0R3NF00
A0A212F3A3 A0A194RNK8 A0A139WNA1 A0A139WNA3 A0A139WNP9 D7EIC7 A0A1Y1MLL3 A0A1Y1ME41 A0A182N426 A0A182QX20 Q16MS2 W5J732 A0A182TL33 A0A182GR59 A0A182F7L8 A0A182MTD3 A0A182JQJ5 A0A182VZ79 A0A182IQ49 A0A182PGS7 A0A182UPQ0 F5HML1 Q8T5I0 A0A182WSD6 A0A182HL87 A0A1B6DLL7 A0A1B6C773 A0A1B6C7W4 A0A084VFZ1 B0X1Z5 A0A336K3J7 K7IXP9 B4GNX6 A0A3L8DLM5 B4JRX7 E0VJG7 A0A1I8PB18 A0A1I8PB72 A0A1I8PB64 A0A1I8PB09 A0A1I8PB14 A0A1I8PB08 A0A1I8PB77 A0A1I8PB17 A0A1I8PB33 A0A1I8PB82 A0A1I8PB59 A0A2A3E5T5 A0A1I8PB13 A0A1W4UPQ4 A0A1W4UPZ1 A0A1W4URK7 A0A1W4UCL6 A0A1W4UCM1 A0A1W4UPP8 A0A1W4URK2 A0A182R661 A0A034VR23 A0A1W4UCM6 B4KB92 A0A0R1E847 A0A0B4KHR1 A0A0B4KH56 A0A0R1E5K1 A0A0R1E9G6 A0A0R1E518 A0A1W4UD65 A0A0B4KI46 A0A0R1EA26 A0A0R1E4Y7 B4PRB5 A0A0R1E4Z1 A0A1W4UPQ8 A0A0R1E6A3 B3LX38 B4IGU7 Q9VB11 A0A1W4UPZ8 B4M624 A0A0R1EA21 A0A0R1E4Z3 A0A0R1E5F2 A0A0B4KHA4 B4NAR2 A0A0R3NKC8 Q29BG7 B3P5Y9 A0A0R3NKF9 A0A3B0JF06 A0A3B0JEF5 A0A3B0KAW1 A0A0R3NFD4 A0A0R3NLI1 A0A0R3NF00
Ontologies
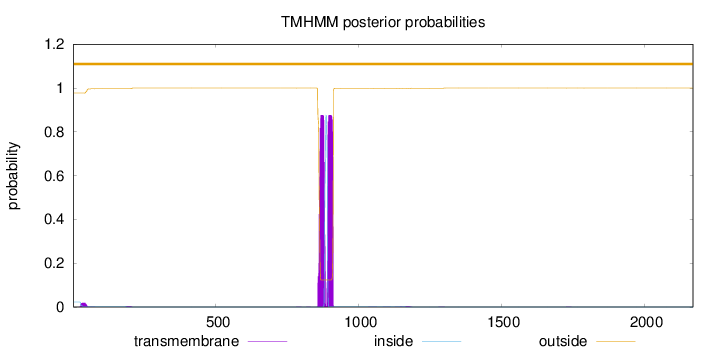
Topology
Subcellular location
Membrane
Length:
2171
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
36.0391100000001
Exp number, first 60 AAs:
0.40599
Total prob of N-in:
0.02303
outside
1 - 2171
Population Genetic Test Statistics
Pi
194.566957
Theta
166.804212
Tajima's D
0.113872
CLR
118.146871
CSRT
0.39718014099295
Interpretation
Uncertain
