Gene
KWMTBOMO02966 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA003573
Annotation
PREDICTED:_uncharacterized_protein_LOC101744237_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 1.953
Sequence
CDS
ATGAGTGGTCTACGATCCGTTCAGGTAGTCAATGTGAATGACAATCACAATTATGTGCTTGAAGATAACACACTCCAGAGAATTTTACTGCGTGAGGATGTAAAAGATCTGCCGCTGGTGGTGGTTAGCGTAGCGGGCGCCTACCGTGGAGGAAAGTCCTTCTTGCTAAGCTACTTCCTCCGCTACCTCAACTCACCGACGGAAAAGCGAAACGAAAATGGCGACTGGTTGGGGAACGAAACAGACCCTTTAATCGGATTCAGCTGGAAGGGAGGATCTGAAAGGCATACTACGGGCATACTAATGTATCCGGAGCCATTTATCACCACTACAGCTGCAGGAGAAAAGGTGGCAGTGCTGTTAATGGATACACAAGGCACCTTCGACTCCAGCAGCACAGTGCGAGATTGCTCCATAATATTTGCGCTCTCTACCCTAATATCGTCCGTTCAGATCTATAATCTCAAAGAGAATCTTCAAGAGGACGATCTTCAATACTTACAGTTATTTACCGAGTACGGGAAACTACTTAAAAACGAAGACGGCTCCAAAGCGTTTCAGATGCTAATGTTCCTTATCAGAGATTGGCCTTACTATTATGAACATGCTTTCGGTGCCAAAGGAGGTGAAGAGCTATTAAAAAAGAGACTTGAAATTACAGATAAAATGCCAAAAGAGCTATGTGACCTCCGGGAACATATTCGTTCTTGCTTCGATAAGGTTTCATGTTTCCTTATGCCTCACCCCGGTTTCAAAGTTTCGAATCCAAGCTACAACGGAAACTTTTCTGAGCTTTCGACAGAATTCAGAAACGCTCTTAAAGAGCTTGTACCGTCTATATTTGCGCCTGAAAATTTGAATATAAAAAAGATAAATGGAGTTAAAGTAACATGCGCTGATATGTATACATATTTCCAAACTTATATGACTGCTTTCAACAGTGATTCTATGATAACTCCTAGCAGTATCTTCGAGAATACCAAGAGGGCGGCATTGATGGCAGCTATTCGGGAAGCTACCAGTAAGTACACGAAGATCATGGATGCTGCGTGCAATACCGACACGCCAAGTATGCCAGGTGAAGGAGTTCGTGTTACTCATAACCAAGCATTGGCTAAAGCAATCGAAGCGTTCAACAAAAAAGGGAAAATGGGCTCACAAAAAGAGATCGGTGCATACCTAACTCAATTAAAGCGTGATTTAGAAGATCAATTACCACGTTATGGCCTTATGAACGACGGCAAGTATCGGAAACTAGCATTCGAAGCAAAAGAAGTATTTGATAATACAGTCAAAGCAGTGCACGGTGAAAATTTATTTTGCTTGCATCCGAATGATGTAGAACCATTGTTCAATGAAGCCGTTTTAGCCGCTTCTACTTACTTTGATTCCAAAAGACAAAAAATTCCAAATGTCATTGATGAAGAAAAGAATAAATTCATCCAGTATTTAGGCAAAGAACTGAAGTGTCTCCAAGCATTAAATCTACAAAACAACAGACACGTTATAACTGAACTCAAGATGAACTTCTCTAGTTTCATGGAAGGCTTAGTCAACAAGGAACCTCCATTAGATGACAACGAATATGAAGCCAAGTACCAAGAAAGCTACAGAAAAGCCATTGAGACATTCGACCAGCGACGAAATAGGCCTACAGAATTTCCAGAAGATGTATTCAAACTATCTCTGATGCAGCACATGGCAGCTCAATTTATTAACTTGCAAGCAATCAATAGAAGTAAAAATAGGAAACAATTCATGATGGCGTTGTCATTCTACACGAATCACATGAGTCTTTTCTGGGATCCCGATACATGCTGCTTACATCCAAACGACTTGGCAAACGAACATAAATTAGCATCAGAACAAGCGTTGAAACTATTTCACCCCGAATTGCCAGATGAGATGGAGAGAGAAATACTTAAACAGTTCATCAAGTCGAAGTATGACGATCTGCGCGAACTGAACGATGCTGCGAATGAAACAGCTATTGCTACAGCTGTTAACGTGTATGTAGAAAAAATGGAGAAAGCCACAGAATTTAAGGGCTGGTGGATCCCAACTTTGGGGATTCCGTATCTTGTCAACCTGGCTAATAGATCTTCCTATCACGAGGAAGCCAAAGAAGCTGCTCTTCTTAATTTCTACTCGAATCGTCGCGATCGCATGAACAGCGCTCCCGATAAATACTACAATGAACTTATTAAGGGCTTGGGCGAAATCCGCCTCCCTGGCCCCCGCTCGAAGGCGGCGGGCCTGTGCGTCTCTCACGCACCCCGCCGCCTCCTTCTGCAAGATGGTGCACTCGCAGAAGTCGATCATCGCCTTCCACGACTCGTCGTCACCGAGCATCGATACCACAACACTCGGCAACGACAAGTCGTTTCGTATTTTTGCGACGAGGACACGGCACCACCCCTCCCATTCGGGGCAGGCGACAAGCGTGTGCTCCGCCGTGTCCAAGTCACAACCACAATGGTGGCACTCTGCCGTCGGCTCGGCTCCGATCCGGTACAGGAACTCACCGAAGCAACCGTGCCCAAAGCAGTTCAGAGTTTGATTATATACTCTTTGCTGCTGTATAGAAAAATTGGACAATTTGAGTACTGGAGAGTCTACTTGGAGGACAGATCGGTCACGTGTACCGGACACGGTGGGATCGTGCACCGGTTCCCGGTCGTGCGCGGTGTTCCACAGGGGTCGGTGCTCGGCCCTCTTTTGTGGAATATCGGGTATGACTGGGTGCTGAGGAGTGCCCTCCTCCCGGGCCTGAGCGTAATCTGTTACGCAGACGACACGTTGGTCGTGGCCCGGGGGGGGAGTTTTGCTGAGTCTGCCCGTCTTGCTACGGCTGGGGCCCCGGAGAGTGCCACCTGTCGATGCCCATATCGTGGTTGGAGGCGTCCGTACTGGGTCGGGGTGCAGTTGAAGTACCTCGGCCTCATTCTAGACAGTCGTTGGACCTTCCGTGCTCACTTTCAGAATCTGGTCCCTCGTTTGTTGGGGGTGGGCGGCGCGTTAAGCTGGCTCCTTCCGAATGTTGGGGGGCCTGACCAGGTTACGCGCCGTCTCTATACAGGGGTGGTGCGATCAATGGCCCTATACGGGGCGCCCGTGTGGGGCCAGTCCCTGGCCGTGGGGGTAGCGAAGCTGCTGCAACGGCCGCAACGCACCATCGCGGTCAGGGTCATCCGTGGTTATCGCACCATCTCTTTCGAGGCGGCGTGTGTACTGGCTGGGACGCCGCCTTGGGTCCTGGAGGCGGAGGCGCTCGCTGCTGACTATCAGTGGCGGGCTGACCTTCGTGTCTGGGGCGTGGCGCGTCCCAGCCCCAGTGTGGTCAGAGCGCGGAGGGCCCAATCTCGGCGGTCCGTGCTGGAGTCATGGTCCAGACGGCTGGCCGATCCTCTGGCTGGTCGTAGGACCGTCGAGGCGATTCGCTCGGTTCTTGTGAACTGGGCAATTGAATCTAACAGGTATATTGAAGACCTAATCAATATGAGTGGGCCACGATGCGTTCAAGTAGTTAATAGGAATGAAAATCACAATTATGTGCTTGAAGATAACGCACTCCAGAGAATTTTATTGCGTGAGGATGTAAAAGATCTGCCGCTGATGGTAGTTAGCGTCGTGGGTGCCTACCGTGGAGGAAAGTCCTTCTTGCTAAACTACTTCCTCCGTTACCTCAACTCACCGACGGAAAAGCGAAACGAAAATGGCGACTGGTTGGGGAACGAAACAGACCCTTTAGTCGGATTCAGCTGGAAGGGAGGATTTCAAAGGCATACTACGGGTATACTAATGTATTCGGAGCCATTTATCACCACTACAGCAACAGGAGAAAAGGTGGCAGTGCTGTTAATGGATACACCAGGCCTCTTCGACCCCAACAGCACAGTGCGCGATAGCTCCATAATATTTGCGCTCTCCACCCTAATATCGTCTGTTCAGATCTATAATCTCATCGGGAATCTTCAAGAAGACGATCTTCAGTGGTTACAGGTAGATTTCAATACTCGGCTTATATACCCTGCAGTGGTTCTGAAAACGTGCGCTCCTGAGCTGACGCCTGCGCTAACGCGTTTGTATCGCCTCTCTTATTGCGCTAACAGGGTTCCGTCTTCATGGAAAACCGCCCACGTCCACCCTATCCCCAAGAAGGGTGACCGGTCGGACCCATCGAGCTACAGGCCTATCGCGATAACTTCTTTGCTTTCCAAGGTGATGGAGCGAATAATAAATGTACAACTCCTGAAGTATCTTGAAGATCGCCAGCTGATCAGTGACCGACAGTACGGTTTCCGTCACTCAGCTGGCGATCTTCTTGTATACCTTACTTACAGCACGGGGGATGCGCGATATATCGGTCATCAGAGCCTCTCTCGGAGCGTGGTGCAAGAGAGACGATCTAAGCTTGTGTCTGAAGTGGAGAACTCTCTGGGGCGAGTCTCCAAATGGGATGAATTGAACTTGGTTCAGTTCATCCCGTTAAAGACACAAGTTTACGCGTTCACTGCGAAGAAGGACCCCTTTGTCATGGCGCCGCAATTCCAAGGAGTATCGCTGCAACCTTCCGAGAGTATCGGGATACTTGGGGTCGACATTTCGAGCGATGTCCAGTTTCGGAGTCATTTGGAAGGCAAGGCCAAGTTGGCGTCCAAAATGCTGCGAGTCCTCAACAGAACGAAGCGGTACTTCACGCCTGGACAAAGGCTTTTGCTTTATAAAGCACAAGTCCGGCCAAGCGTGGAGTACTGCTCCCATCTCTGGGCCAGGGCTCCCAAATACCTGCTTCTTCCATTTGACTCCATACAGAGGAGGGCCGTTCGGATTGTCGATAATCCCATTCTCACGAATCGTTTGGAACCTCTGGGTCTGTGGAGGGACTTCTGTTGCCTCTGTATTTTGTACTGTATGTTCCAAGGGGAGTACTCTGAGGAATTGTTCGAGATGATACCGGCATCTCGTTTTTACCATCGCACCGCCTGCCACCGGAGTAGAGATTGGTTTTACCCTTATGAACATGCTTTCGGTGCCAAAGGAGGTGCCGAGCTATTAAAAAAGAAACTTGAAAATACCAAGAGGGCGGCATTGACGGCAGCTACGCGGGAAGCTACCAGTAAGTACACGAAGATCATGGATTCTGCATGCAATACCAACACGCCAAGTATGCCAGGTGAAGGAGTTCGCGTTACTCATAACCAAGCATTGGATAAAGCAATCGAAGCGTTTAACAAAAAAGGGAAATTGGGCTCACAGAAAGAGATTGATGCATACCTAACTCAATTAAAGCGTGATTTAGAAGAACAATTACCACGTTATGGCCTTATGAACGACGGAAAGTATCGGAAACTAGCATTCGAAGCAAAAGAAGTATTTGATAATACAGTCAAAGCAGTGCACGGTGAAAATTTGTTTTGCTTGCATCCGAATGACGTAGAACCATTATTCAATGAAGCCGTTTTAGCCGCTGTTACTTACTTTGATTCCAAAAGGCAAAAAATTCCAAATGTCTTTGATGAAGAAAAGATTAAATTTATTCAGTGCTTAGGCAAAGAACTGAAGTTTCTCCAAGCGTTGAATCTACAAAACAACAGACACGTTGTAACTGAACTCAAGATGAACTTCTCTAGTTTCATGGAAGGCTTAGTCAGCAAGGATCCTCCATTAGATGACAACGAATATGAAGTCAAGTACCAAGAAAGCTACAGAAAAGCCATTGAGACATTCAACCAGCGACGAAACAGGCCTACAGAATTTCCAGAAGATGTATTCAAACTATCTCTGATGCAGCACATGCCAACTCAATTCACTGACTTAAAAGAAATCAATAGAAGTAAAAATAGGAAACAATTCATGCTGTCGCTGTCATTCTACGTGAATTACATGAGTCTTTTCTGGGATCCCGATACATGCTGCTTACATCCGAACGACTTGGTAAACGAACGTAATTTAGCATTAGAACAAGCGTTGAAACTATTTCACCCCGAATTGCCAGATGACATGGAGAGAGAAATACTTAAACAGTTCATCAAGTCGAAGTATGACGATCTGCGCGAACTGAACGATGCTGCGAATGAAACGGCTATTGCTTCAGCTGTTAATGTGTATATAGAAAAAATGGATAAAGCCACAGAATTTAAGGGCTGGTGGGTCCCAACTTTGGGGATTCCGTATATTGTCAACCTGGCTAATAGATCTTCCTATCACGAGGAAGCCAAGAAAGCTGTTCTTCTTAATTTCTACTCGAATCGTCGCGATCGCATGAACAGCGCTCCCGATAAATACTACAATGAACTTATTAAGGAGATCAACTACGCTCGGATGAAATATTAA
Protein
MSGLRSVQVVNVNDNHNYVLEDNTLQRILLREDVKDLPLVVVSVAGAYRGGKSFLLSYFLRYLNSPTEKRNENGDWLGNETDPLIGFSWKGGSERHTTGILMYPEPFITTTAAGEKVAVLLMDTQGTFDSSSTVRDCSIIFALSTLISSVQIYNLKENLQEDDLQYLQLFTEYGKLLKNEDGSKAFQMLMFLIRDWPYYYEHAFGAKGGEELLKKRLEITDKMPKELCDLREHIRSCFDKVSCFLMPHPGFKVSNPSYNGNFSELSTEFRNALKELVPSIFAPENLNIKKINGVKVTCADMYTYFQTYMTAFNSDSMITPSSIFENTKRAALMAAIREATSKYTKIMDAACNTDTPSMPGEGVRVTHNQALAKAIEAFNKKGKMGSQKEIGAYLTQLKRDLEDQLPRYGLMNDGKYRKLAFEAKEVFDNTVKAVHGENLFCLHPNDVEPLFNEAVLAASTYFDSKRQKIPNVIDEEKNKFIQYLGKELKCLQALNLQNNRHVITELKMNFSSFMEGLVNKEPPLDDNEYEAKYQESYRKAIETFDQRRNRPTEFPEDVFKLSLMQHMAAQFINLQAINRSKNRKQFMMALSFYTNHMSLFWDPDTCCLHPNDLANEHKLASEQALKLFHPELPDEMEREILKQFIKSKYDDLRELNDAANETAIATAVNVYVEKMEKATEFKGWWIPTLGIPYLVNLANRSSYHEEAKEAALLNFYSNRRDRMNSAPDKYYNELIKGLGEIRLPGPRSKAAGLCVSHAPRRLLLQDGALAEVDHRLPRLVVTEHRYHNTRQRQVVSYFCDEDTAPPLPFGAGDKRVLRRVQVTTTMVALCRRLGSDPVQELTEATVPKAVQSLIIYSLLLYRKIGQFEYWRVYLEDRSVTCTGHGGIVHRFPVVRGVPQGSVLGPLLWNIGYDWVLRSALLPGLSVICYADDTLVVARGGSFAESARLATAGAPESATCRCPYRGWRRPYWVGVQLKYLGLILDSRWTFRAHFQNLVPRLLGVGGALSWLLPNVGGPDQVTRRLYTGVVRSMALYGAPVWGQSLAVGVAKLLQRPQRTIAVRVIRGYRTISFEAACVLAGTPPWVLEAEALAADYQWRADLRVWGVARPSPSVVRARRAQSRRSVLESWSRRLADPLAGRRTVEAIRSVLVNWAIESNRYIEDLINMSGPRCVQVVNRNENHNYVLEDNALQRILLREDVKDLPLMVVSVVGAYRGGKSFLLNYFLRYLNSPTEKRNENGDWLGNETDPLVGFSWKGGFQRHTTGILMYSEPFITTTATGEKVAVLLMDTPGLFDPNSTVRDSSIIFALSTLISSVQIYNLIGNLQEDDLQWLQVDFNTRLIYPAVVLKTCAPELTPALTRLYRLSYCANRVPSSWKTAHVHPIPKKGDRSDPSSYRPIAITSLLSKVMERIINVQLLKYLEDRQLISDRQYGFRHSAGDLLVYLTYSTGDARYIGHQSLSRSVVQERRSKLVSEVENSLGRVSKWDELNLVQFIPLKTQVYAFTAKKDPFVMAPQFQGVSLQPSESIGILGVDISSDVQFRSHLEGKAKLASKMLRVLNRTKRYFTPGQRLLLYKAQVRPSVEYCSHLWARAPKYLLLPFDSIQRRAVRIVDNPILTNRLEPLGLWRDFCCLCILYCMFQGEYSEELFEMIPASRFYHRTACHRSRDWFYPYEHAFGAKGGAELLKKKLENTKRAALTAATREATSKYTKIMDSACNTNTPSMPGEGVRVTHNQALDKAIEAFNKKGKLGSQKEIDAYLTQLKRDLEEQLPRYGLMNDGKYRKLAFEAKEVFDNTVKAVHGENLFCLHPNDVEPLFNEAVLAAVTYFDSKRQKIPNVFDEEKIKFIQCLGKELKFLQALNLQNNRHVVTELKMNFSSFMEGLVSKDPPLDDNEYEVKYQESYRKAIETFNQRRNRPTEFPEDVFKLSLMQHMPTQFTDLKEINRSKNRKQFMLSLSFYVNYMSLFWDPDTCCLHPNDLVNERNLALEQALKLFHPELPDDMEREILKQFIKSKYDDLRELNDAANETAIASAVNVYIEKMDKATEFKGWWVPTLGIPYIVNLANRSSYHEEAKKAVLLNFYSNRRDRMNSAPDKYYNELIKEINYARMKY
Summary
Uniprot
ProteinModelPortal
PDB
3X1D
E-value=3.51066e-113,
Score=1051
Ontologies
GO
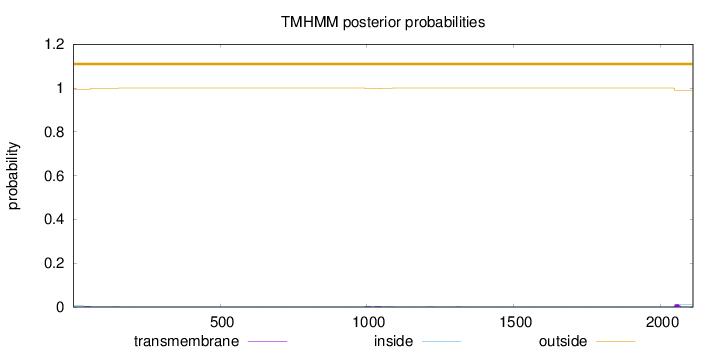
Topology
Length:
2111
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.50576
Exp number, first 60 AAs:
0.10266
Total prob of N-in:
0.00521
outside
1 - 2111
Population Genetic Test Statistics
Pi
246.292631
Theta
207.928943
Tajima's D
0.394663
CLR
1.112552
CSRT
0.48287585620719
Interpretation
Possibly Positive selection
