Gene
KWMTBOMO02404 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA013530
Annotation
PREDICTED:_uncharacterized_protein_LOC101745669_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 2.849
Sequence
CDS
ATGTCGTTCTGCAGAATTACGGGCCGCAGTAGAGGGCTGCCGAAGCCCAACTACTTTCCTCTTCTCGCACCGATTTCCCCTGCCGATGCGAAGCGCTGCTGCAGGATCACCGGCAAGTCTTACGGGCTGCCTTCACATCATTACATTCCAGTACTACTCACGGCTCGCTCTACGAAGGCTAAATGTAAAATTACGAATATATCCGGTGAACTGGGACCGCATCATTATTCGCCGGAAATTAATTATGGAAACAGAAAACACGAGATGCTGCCGGACTACAGATATATTTTCCCTGTTCTAGACGGTTCGACTGAAGCACAGAAAGGATTGATAGAGTTGCTGTTAGGGAAACAAGTTACGGAAGACAAACGTTATGTTTACACAGTGCAGGAAAGAAGATGTAGTCTAGTGTTTTCTGCTCAGATGGAAGCGGCGGTTCGCGACGGCGACGTTAGGGACGTTATGCTTGCCAAAGATTCGGACACTGTACTTATCAAGACTAAACAGGGTCGCAGCGTTTCAATGGACTTTAAAGATTTTACCGAAGACGTGGAGATGTTCGAAGGTGAGGGACCAAATGCAGAAGTACTTAAACAAAGAGAAATGGAAGAATTAGAAGAAAAAAAGAAGAAAAGGAAACGCACAGCTGGATTATCGTCTATGAAGAAAATTTTTGAAAATAAAGAAAAACTGGCTGATGTTCAAGAATTAGAAGAAGAAAAACAGCGCCAAGATCGAAAAGCGAAAAAAGCCAAGATGGAGGAATTCAAGCATGAGAAACACGACGTGAAATGCTTCACTTACGACAACTTTGATTTGAATCATATGCGCTCAAAATCGAGCATTGTGACGTGTTCTGGAGAATGGAGAAATCAGTTACACCCTCTAGGAGAGTCTTGGAGTTGGGATGAATTTGAAAAAGATATTATTGATGAGAATTTTATACCGAAAGTAACACAACTACCGACGCCCTTAAAGATAGCGCCATATCATTGTGAAGCAGAGATATATGAAGTTAACAAAAATATTAGCGATGTGTCAGTTTCTTTAGAGAGTGTGCCATGCGTTAACCCCCTTAAGCCAGTGAAAGCTCGACCTGAACAGACAGTGTTGAGTGGAATTAAAGAGCTATCAAGTGAAAAGTTGATAGAAACGGCTAATGTTGCTGAAAGATTAATCGAAAACGGAAAAACTGATCTGCTCCCGACCATCGATTGTTTGCCGGAGGTGGTCAAGAATATTAAAAAGGGTAAAAGAAATAAAATAGCTGCAATTTCTGGTCTTACGTTAGACATAAACAAAGCCAAGAAATTTGTTCCTGGACAAATGCTGAATACACCCCAAGGTACTGTTTTTGTGCCGGGACAGACTATTGAGACGCCAGATGGCCCAATATTTGTGCCCGGTCTAAGTGTCAACACGCCTGCCGGACCGGCTCTTATACCAGGTCACATAGTTATGAACGAAAACAACAATGAGCCTTTATTTCTTGCTGGCCAAAATTTAATGACAGCAAATGGTGAAGAGTTTGTTTGCGGTCAAACAATCAAAACCAAGAATGAAACTTATCGGTTCCTTGAAGGTCAAACAGTGCTTTCTGAAGAAGGACTGAAATTCGTACCCGGAAAAACTATTAGCACAGGATCCGAAGAAGTTTTTGTTCCTGGTCAGGCGATTATGACACCGGACGGCGTTCAATTTATTCCCGGTCAAACAATAACAGAAGACACAGAAATCACTTTTACGCCGGGGCAAAATGCGAAAATTAACAATGAGTGGCAGTTCGTTCCCGGGCAAGTACTACAGCAAGACGACGAGTTACACTTTGTTCCTGGTGCCACGATAGCAACACCGAATGGCTTGAAATTTGTTCCCGGTCAAACAATTACTGTCAACGGAGAAAGTTGCTTTGTCCCCGGTATTTCTAAAACTACCAGTGATTCTTCTCTTCAGTTTGTTCCCGGAACAACGTTAGAAACTATTGATGGGCCGAAATTTGTTGAAGGTCAAGTCGTCATTACGAACCACGGGGAAAAATTTGTACCAGGGAAAACTATTGTGCAGGCTGATGGTCACGTAGAGTTTTCTGTTGCCAAATCTGTTGAAGACATAACGTTTACAGAAAGTACACCTACTGGTTTACCAATAGATATCAAAACCTGTTCATTATCAGAAGAATCCCTTTACGTATTCGGGCATATGATACAAACAACTAAGGGCATAGAGTTCTATCCTGGCCCTAGGATCCCGAAAGTGGAAGGTAAAGTTGTGCCTGGAAGACTGGTGAAAAATGATTTAAATCAATCCCGCTTTGTACCTGGTACTATGGTGGAAGGCATTTTCGTACCTGGGCAAATCGTGTTTACTGAAAACGGAGAGCAGTTTGTACCGGGTCAAGTTGTTGATACGGCAGATGGACCAAAATTTGTACCGGGTCAAGTTGTGAATACTAAATCGGGACCAAAGTTCGTTCCCGGTCAGACTATACATACCATCGATGGTCCTCGCTTCGTTCCTGGACAGATTATAGAAACGAAGGCTGGTCCAACATTCATACCTGGTCAAGTAATATCTACAGATGAAGGCTCTAGATTCGTTCCCGGTCAAGTTGTAGATACCGAAGAAGGGCCCAGATTTGTTCCTGGAAGAGTGGTAGAAACTGATGATAATGGAGTCACTTTCGTTCCTGGTCAAATCGTTCAAACACCTGAAGGACTTAAATTCGTAGCCCCCGATCTAACCGAAGGTGAAGAAGGCTTGGAATTTTCAGTGCAAAGTTTCGTTGTCACCCCTGAAGAGCTCAAATTACTCAAAGTAAAAACTAATCCTAATGACACAACGTCTACGAAAGGCGAGCTGACTATCGACACTAAAATGTTAAGGCAGCTCTCAGAAGCAGGTATGTCAATCGGTAGACAGGTTCCAGCCGATTTACCATCAATCAGTGTTATATTAAATCAAACTAAAAACGTAGAAGCCTTGAAGGCATTCGTGACAGACTTCGGTTTAAAAGACGAAGTTGCGAACCAATTGATGGATGTTATTTCATCGATTATTGAAATGAGTGCTCATATAAAGTCTGAAATGCACGACAGTGATAGAAGTGACTCCTCAGCATCATCTGAAATCAAGAAAATCAGAGGAACCAAAAAGCGTATGGATATTCAGGAAAGCGTTGGTTTCATTGGAGGTAATGGACAGTCTGCACATCAAGAACGAGTGAAAAATTCAATTGCTGCCGCAGTTTTGGCAGCCCTGGTAACTGCTGAACAATTTGAAGAAATAAACAATAATAATAGTAAAGAGAAATATCAAATGATTTTGAAATCGATTGACACAATTCTAGGAAAGGCTCTTGATGAAGATTTTGTATCGGCTATGTACGCGATACTTCAAAAAGAGGAAGATAAAGAAATGCTCTGTGATGAAATTCTTGATAATACGTCGGAATCTAAAGTAGAATTAATAAAATTGGCCGTAAATAATGCTTTAAACAAACATTCCATCAATGAAGATGAAATTATTGAAAAATTTGGAGAATTTCTTGGTGCCGAGAACGAAGTATTAGGCCCGGCATTCAAAAATATTTCTAAATGCGACACGAAACTTCTACAACACATACTTGGACGTATTTCTGAGTCAATATATTTCGTAAACACCGACCATGAAGCCACTGAAACGTTGCAAAAAGCGATCGTGTCAGCGGTCCAAGATTCGAGCAGTCAAGAAATAAAAATATTACTAAACGAGAAGTGTGAACAAGAAAACGTGAAGGAATTAATCGCACAGTCAGTCGGGCTCGCTAAACTACTCGGAATGAGAGACATCGCCACAAAACTAATGGCTATTGTGAACAGTGAAGAGGACTTGTCTAAAATAGCATCCGACGATACAAGCCTTAGCATATTAAAACGTTTAATTGTTATGAGGAAGCTCGCGGAAAAATCTCCCAGCTTGCTTTCTGCTTTACGTAAGTTGGAAACCAATCCAGAGTTGGCTCGCACGGACCCTAATCTTAGGGACTTGGTGCGAGAAAGCGCCGCGCTGATGATCATTCCAGAAGAACCACCTCTCATGTCATCACAAGACGTCCCGTTGAGTCTACTTCAGCCTGAAAATAGTCTCGCCATGGAAGACTTTTTGTTCCAGCGTAAGAAGAAAGTCTCTGGGGCTCTGTTGATCATGAAAAAAGGATTGCAAGCTGTGGTTCCTAGAGAAGCCAGTCGCGCGGTTTTAACCGGACAAGTGGCGTACACAGTTCTAGATGAAAATGGAATTCAACATTTCGAACCCCTACACGTATTCTCAGCTTTAAACTTAAGTCAGCCCTCGGCTCATCGCTTCTCAATGTACAGCTGTCCTATTGTGGACAACCAAGATGAAGATCTGGAAACTTTTAACGGCTATTGCAATATCAGTAATAGTCAGATCATAACGAGAATGAGCGGTTGGGGCAGGAAATACAGCGGGGTTTTACTAGATAGGGAGAATACTAGGAGTAGGATGAGCAGCTTGGAAAATACACCCAGTTACAAACGATATCCTTCGCGTTCACTGTCTAGATCTCGTTCCAGCTGTAGCAGGAGTCCTCCTAAGGTGGACGACGTGGTGGTAGCGTCTTCGGACTACACCGCCGCTACCGAAGACGAAGTCTCGTTGAAGACAGGCGACATAGTCGAGGTTCTCGACACGAAAACTGCTCTCGGAGCCAAGAGGCCAAAATTAGCGGACTTGGACGTCGAGGCGAGCCTCCTGGACACATCAGCAGCGAAGCACAAGATTGCTATACGACCGAAGAAAAATCACCCGAAGAACAAATCCGGAAAGAGAGTCAATGAGAACGAAGACAGATGGCTAGTGCGTGTGATAGAAGACGTCAGCGGTGGCGAGATAACGACGCGACAGGGTCTGGTGCCGGCTAGCGTGCTGCACGAGAAGCAGACGTCGGAGGATGATCAGACTGCCCTCGCTGCCAGGCGACAGTGA
Protein
MSFCRITGRSRGLPKPNYFPLLAPISPADAKRCCRITGKSYGLPSHHYIPVLLTARSTKAKCKITNISGELGPHHYSPEINYGNRKHEMLPDYRYIFPVLDGSTEAQKGLIELLLGKQVTEDKRYVYTVQERRCSLVFSAQMEAAVRDGDVRDVMLAKDSDTVLIKTKQGRSVSMDFKDFTEDVEMFEGEGPNAEVLKQREMEELEEKKKKRKRTAGLSSMKKIFENKEKLADVQELEEEKQRQDRKAKKAKMEEFKHEKHDVKCFTYDNFDLNHMRSKSSIVTCSGEWRNQLHPLGESWSWDEFEKDIIDENFIPKVTQLPTPLKIAPYHCEAEIYEVNKNISDVSVSLESVPCVNPLKPVKARPEQTVLSGIKELSSEKLIETANVAERLIENGKTDLLPTIDCLPEVVKNIKKGKRNKIAAISGLTLDINKAKKFVPGQMLNTPQGTVFVPGQTIETPDGPIFVPGLSVNTPAGPALIPGHIVMNENNNEPLFLAGQNLMTANGEEFVCGQTIKTKNETYRFLEGQTVLSEEGLKFVPGKTISTGSEEVFVPGQAIMTPDGVQFIPGQTITEDTEITFTPGQNAKINNEWQFVPGQVLQQDDELHFVPGATIATPNGLKFVPGQTITVNGESCFVPGISKTTSDSSLQFVPGTTLETIDGPKFVEGQVVITNHGEKFVPGKTIVQADGHVEFSVAKSVEDITFTESTPTGLPIDIKTCSLSEESLYVFGHMIQTTKGIEFYPGPRIPKVEGKVVPGRLVKNDLNQSRFVPGTMVEGIFVPGQIVFTENGEQFVPGQVVDTADGPKFVPGQVVNTKSGPKFVPGQTIHTIDGPRFVPGQIIETKAGPTFIPGQVISTDEGSRFVPGQVVDTEEGPRFVPGRVVETDDNGVTFVPGQIVQTPEGLKFVAPDLTEGEEGLEFSVQSFVVTPEELKLLKVKTNPNDTTSTKGELTIDTKMLRQLSEAGMSIGRQVPADLPSISVILNQTKNVEALKAFVTDFGLKDEVANQLMDVISSIIEMSAHIKSEMHDSDRSDSSASSEIKKIRGTKKRMDIQESVGFIGGNGQSAHQERVKNSIAAAVLAALVTAEQFEEINNNNSKEKYQMILKSIDTILGKALDEDFVSAMYAILQKEEDKEMLCDEILDNTSESKVELIKLAVNNALNKHSINEDEIIEKFGEFLGAENEVLGPAFKNISKCDTKLLQHILGRISESIYFVNTDHEATETLQKAIVSAVQDSSSQEIKILLNEKCEQENVKELIAQSVGLAKLLGMRDIATKLMAIVNSEEDLSKIASDDTSLSILKRLIVMRKLAEKSPSLLSALRKLETNPELARTDPNLRDLVRESAALMIIPEEPPLMSSQDVPLSLLQPENSLAMEDFLFQRKKKVSGALLIMKKGLQAVVPREASRAVLTGQVAYTVLDENGIQHFEPLHVFSALNLSQPSAHRFSMYSCPIVDNQDEDLETFNGYCNISNSQIITRMSGWGRKYSGVLLDRENTRSRMSSLENTPSYKRYPSRSLSRSRSSCSRSPPKVDDVVVASSDYTAATEDEVSLKTGDIVEVLDTKTALGAKRPKLADLDVEASLLDTSAAKHKIAIRPKKNHPKNKSGKRVNENEDRWLVRVIEDVSGGEITTRQGLVPASVLHEKQTSEDDQTALAARRQ
Summary
Uniprot
H9JVG7
A0A2W1BHW5
A0A2A4JLU6
A0A2H1V4J7
A0A0L7LM40
A0A194QA86
+ More
A0A0N1IAC7 A0A310SJ66 A0A0L7R1X1 A0A0M9AAW0 A0A154P3S2 A0A195FAX9 A0A195CMJ2 A0A151XCS3 A0A151JBU0 A0A026WVM0 A0A088A5W9 E2AYP1 F4WYU8 A0A151I005 A0A158NC60 A0A2A3EJL6 E9IM16 K7IR83 B0X5D1 Q16NT2 A0A1S4FUF5 A0A182GHX4 A0A182WK91 A0A182PN87 A0A182TNX8 A0A146LSU7 A0A182RN58 A0A182NM88 A0A182MCA5 A0A182XIK1 A0A182QEW8 A0A182KC22 Q5TRN0 A0A182LJN1 A0A182HM43 A0A182Y0V5 A0A182UZW6 A0A182FFC1 A0A0J7KZS9 A0A2R7VPA9 A0A0A9YCB2 A0A0P6CER6
A0A0N1IAC7 A0A310SJ66 A0A0L7R1X1 A0A0M9AAW0 A0A154P3S2 A0A195FAX9 A0A195CMJ2 A0A151XCS3 A0A151JBU0 A0A026WVM0 A0A088A5W9 E2AYP1 F4WYU8 A0A151I005 A0A158NC60 A0A2A3EJL6 E9IM16 K7IR83 B0X5D1 Q16NT2 A0A1S4FUF5 A0A182GHX4 A0A182WK91 A0A182PN87 A0A182TNX8 A0A146LSU7 A0A182RN58 A0A182NM88 A0A182MCA5 A0A182XIK1 A0A182QEW8 A0A182KC22 Q5TRN0 A0A182LJN1 A0A182HM43 A0A182Y0V5 A0A182UZW6 A0A182FFC1 A0A0J7KZS9 A0A2R7VPA9 A0A0A9YCB2 A0A0P6CER6
Pubmed
EMBL
BABH01036134
KZ150114
PZC73294.1
NWSH01001115
PCG72544.1
ODYU01000644
+ More
SOQ35761.1 JTDY01000599 KOB76512.1 KQ459465 KPJ00326.1 KQ460393 KPJ15360.1 KQ759828 OAD62661.1 KQ414667 KOC64850.1 KQ435697 KOX80785.1 KQ434809 KZC06585.1 KQ981727 KYN37189.1 KQ977565 KYN01946.1 KQ982298 KYQ58157.1 KQ979120 KYN22572.1 KK107109 EZA59129.1 GL443983 EFN61404.1 GL888463 EGI60602.1 KQ976642 KYM78655.1 ADTU01011664 ADTU01011665 KZ288229 PBC31664.1 GL764129 EFZ18474.1 DS232375 EDS40816.1 CH477809 EAT36024.1 JXUM01064687 KQ562310 KXJ76187.1 GDHC01007771 JAQ10858.1 AXCM01006094 AXCN02000940 AAAB01008960 EAL39835.2 APCN01004338 LBMM01001736 KMQ95828.1 KK854014 PTY09367.1 GBHO01014861 JAG28743.1 GDIP01016411 JAM87304.1
SOQ35761.1 JTDY01000599 KOB76512.1 KQ459465 KPJ00326.1 KQ460393 KPJ15360.1 KQ759828 OAD62661.1 KQ414667 KOC64850.1 KQ435697 KOX80785.1 KQ434809 KZC06585.1 KQ981727 KYN37189.1 KQ977565 KYN01946.1 KQ982298 KYQ58157.1 KQ979120 KYN22572.1 KK107109 EZA59129.1 GL443983 EFN61404.1 GL888463 EGI60602.1 KQ976642 KYM78655.1 ADTU01011664 ADTU01011665 KZ288229 PBC31664.1 GL764129 EFZ18474.1 DS232375 EDS40816.1 CH477809 EAT36024.1 JXUM01064687 KQ562310 KXJ76187.1 GDHC01007771 JAQ10858.1 AXCM01006094 AXCN02000940 AAAB01008960 EAL39835.2 APCN01004338 LBMM01001736 KMQ95828.1 KK854014 PTY09367.1 GBHO01014861 JAG28743.1 GDIP01016411 JAM87304.1
Proteomes
UP000005204
UP000218220
UP000037510
UP000053268
UP000053240
UP000053825
+ More
UP000053105 UP000076502 UP000078541 UP000078542 UP000075809 UP000078492 UP000053097 UP000005203 UP000000311 UP000007755 UP000078540 UP000005205 UP000242457 UP000002358 UP000002320 UP000008820 UP000069940 UP000249989 UP000075920 UP000075885 UP000075902 UP000075900 UP000075884 UP000075883 UP000076407 UP000075886 UP000075881 UP000007062 UP000075882 UP000075840 UP000076408 UP000075903 UP000069272 UP000036403
UP000053105 UP000076502 UP000078541 UP000078542 UP000075809 UP000078492 UP000053097 UP000005203 UP000000311 UP000007755 UP000078540 UP000005205 UP000242457 UP000002358 UP000002320 UP000008820 UP000069940 UP000249989 UP000075920 UP000075885 UP000075902 UP000075900 UP000075884 UP000075883 UP000076407 UP000075886 UP000075881 UP000007062 UP000075882 UP000075840 UP000076408 UP000075903 UP000069272 UP000036403
PRIDE
Interpro
IPR036028
SH3-like_dom_sf
+ More
IPR001452 SH3_domain
IPR013783 Ig-like_fold
IPR011993 PH-like_dom_sf
IPR007110 Ig-like_dom
IPR003599 Ig_sub
IPR013098 Ig_I-set
IPR001849 PH_domain
IPR000219 DH-domain
IPR036179 Ig-like_dom_sf
IPR003598 Ig_sub2
IPR035899 DBL_dom_sf
IPR000719 Prot_kinase_dom
IPR011009 Kinase-like_dom_sf
IPR036116 FN3_sf
IPR003961 FN3_dom
IPR001452 SH3_domain
IPR013783 Ig-like_fold
IPR011993 PH-like_dom_sf
IPR007110 Ig-like_dom
IPR003599 Ig_sub
IPR013098 Ig_I-set
IPR001849 PH_domain
IPR000219 DH-domain
IPR036179 Ig-like_dom_sf
IPR003598 Ig_sub2
IPR035899 DBL_dom_sf
IPR000719 Prot_kinase_dom
IPR011009 Kinase-like_dom_sf
IPR036116 FN3_sf
IPR003961 FN3_dom
SUPFAM
Gene 3D
ProteinModelPortal
H9JVG7
A0A2W1BHW5
A0A2A4JLU6
A0A2H1V4J7
A0A0L7LM40
A0A194QA86
+ More
A0A0N1IAC7 A0A310SJ66 A0A0L7R1X1 A0A0M9AAW0 A0A154P3S2 A0A195FAX9 A0A195CMJ2 A0A151XCS3 A0A151JBU0 A0A026WVM0 A0A088A5W9 E2AYP1 F4WYU8 A0A151I005 A0A158NC60 A0A2A3EJL6 E9IM16 K7IR83 B0X5D1 Q16NT2 A0A1S4FUF5 A0A182GHX4 A0A182WK91 A0A182PN87 A0A182TNX8 A0A146LSU7 A0A182RN58 A0A182NM88 A0A182MCA5 A0A182XIK1 A0A182QEW8 A0A182KC22 Q5TRN0 A0A182LJN1 A0A182HM43 A0A182Y0V5 A0A182UZW6 A0A182FFC1 A0A0J7KZS9 A0A2R7VPA9 A0A0A9YCB2 A0A0P6CER6
A0A0N1IAC7 A0A310SJ66 A0A0L7R1X1 A0A0M9AAW0 A0A154P3S2 A0A195FAX9 A0A195CMJ2 A0A151XCS3 A0A151JBU0 A0A026WVM0 A0A088A5W9 E2AYP1 F4WYU8 A0A151I005 A0A158NC60 A0A2A3EJL6 E9IM16 K7IR83 B0X5D1 Q16NT2 A0A1S4FUF5 A0A182GHX4 A0A182WK91 A0A182PN87 A0A182TNX8 A0A146LSU7 A0A182RN58 A0A182NM88 A0A182MCA5 A0A182XIK1 A0A182QEW8 A0A182KC22 Q5TRN0 A0A182LJN1 A0A182HM43 A0A182Y0V5 A0A182UZW6 A0A182FFC1 A0A0J7KZS9 A0A2R7VPA9 A0A0A9YCB2 A0A0P6CER6
Ontologies
GO
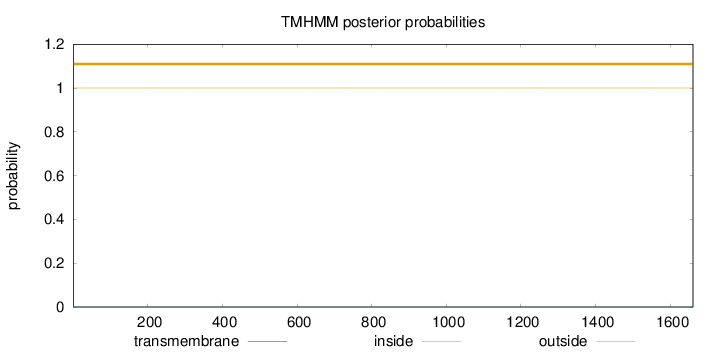
Topology
Length:
1661
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00182
Exp number, first 60 AAs:
0.00182
Total prob of N-in:
0.00011
outside
1 - 1661
Population Genetic Test Statistics
Pi
24.71388
Theta
18.893726
Tajima's D
0.990101
CLR
0.955856
CSRT
0.660666966651667
Interpretation
Uncertain
