Gene
KWMTBOMO02403 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA013531
Annotation
PREDICTED:_LOW_QUALITY_PROTEIN:_muscle_M-line_assembly_protein_unc-89-like_[Bombyx_mori]
Full name
Obscurin
+ More
Muscle M-line assembly protein unc-89
Kalirin
Triple functional domain protein
Muscle M-line assembly protein unc-89
Kalirin
Triple functional domain protein
Alternative Name
Muscle M-line assembly protein Unc-89
Obscurin
Uncoordinated protein 89
Huntingtin-associated protein-interacting protein
PAM COOH-terminal interactor protein 10
Protein Duo
Serine/threonine-protein kinase with Dbl- and pleckstrin homology domain
Obscurin-RhoGEF
Obscurin-myosin light chain kinase
Obscurin
Uncoordinated protein 89
Huntingtin-associated protein-interacting protein
PAM COOH-terminal interactor protein 10
Protein Duo
Serine/threonine-protein kinase with Dbl- and pleckstrin homology domain
Obscurin-RhoGEF
Obscurin-myosin light chain kinase
Location in the cell
Nuclear Reliability : 2.45
Sequence
CDS
ATGCAGCAGGTCGTTTCCCGGTACATGAAGCCCATCGACAAGGCCACCGCACCGAAACCGGTCTTCGATAATCGTGAACTGTTATTCTCCAACTTCAGGCAGATCTGCGAGTTTCATAATACCGTTCTTCTTGAAGGCATTAAGTACTATGCTGGTGAGCCTCGAATGCTAGGAAGAGCGCTTCTTCGCATGGAGCGGGAGTTCGACAAGCACGTCGCTTACTGCCGCGACGAGCCAAGAGCCCAGTATCTTCTAGCTAACGATCCAGTCGTGAAGAAATACTTTCAGAATTGGGTTTTAGTAAATGTTAACTTACAGGATCTAGCAGACAGTCTCGGCGACGATAAGGGTATAACTGAACATCTAAAGCTTCCGATACAAAGGATCAACGACTACCAGCTTCTTCTGAAGGAACTAGTGAAGTATTCGAGACGTCTCGGCGAAGACTGTAACGACCTCCAGAAGGCTCTAGAACTATTTCTTGGCGTTCCGAATCGCGCCACTGACAACAAATTCTTAGCCTCCATCGAAGGATTTAGAGGCAACATCTATAAACTAGGAAGACTTCTCACCCACGACTGGTTTACCGTCACCGACCAGGAAGGCAGGACCAAGGATCGGTATCTTTTCCTCTTCAAAGCGAGGATCTTGGTCTGCAAAGTCAAGAGGATATCTCAGGACAGATCTGTCTTCGTTCTAAAGGATATCATCAAGCTCCCCGAAGTCGAAGTGAAGGAAGTGACCGGAGAACCATTGAAGTTCGAACTTCGCCAGAAAAATCCACCGCTTGATTTGATCGTCGGTGCTCACAAGGAGCACGTGAAGAATACTTGGTTGGCTGAAATCAACAAACACGCTTCGGACATCGTTGCCCTTGCGGAACACGCAGCAGATGACCTTCAAGTTCTTCAGGCCGTAGAAACCAAAGAAACTGCGGAAGAGAAGAAGAAGAAGCGCGAACATACAGAAGAGGTTATCGTTAAAGCAGAGCAAGAGGTGAAAGAGAAACGATCCCGCACCGAAGACATTGAAGTCACCCAGGTTTCGGTTAAAGAAGAAACTTCCCAGCAAGTAAAAGTCAAAAGAAAAGCATCTGTTGAGAGCACAGTTGCTACTAAAATCTCCAAATCAGAAGTCGTAGAAGTATTCTCTCTTAACGAGAACCAGGAATCTGTCGTTAGCGCAATCGACACTGAAGTGAGAAGTGACGTCACAACTGATTTAGAAACTAAATCATCAGTGACTGTAAGCGCTCTGAACGCCGAGACTGAACCTGTTACATCACAATTGGAAAGTCAACAAACTTTGAAAACTGAGCATACAGAAGCAAAAGTAGAAGAACAAATTGTTCAAGCGTCTCAAACGACTGAAGAATATGTTGAAAAATCAATAAAAACTACTAAGCAATCATCTGTAGTTGAAACGACAGAATCATTTCAAGAGATAAGATCTCTCGAACAAGACTCTACAAAAATCTCAACAGAAGATAGAATTACAGTTCGAGAAGAAGAAGAACCAATCCACGCCATTCAAGAGTGTACAAACACACAAGAGAGATCAGACGAGTCATTTGAAACTGTTAAACAAATCCCTGAAATATCAAAAGAAACAGCGGAGAACGAAATATTAGAAACAACAAAAGAATCATCTGAAACTGTTATTCAAGTTTCAGAATCTCTTAGTGAAACTGTTTCTGAAACTGTGATAGCTGTTTCCGAAACTGAAGAAACGTTGCAAACGTTTGAACAGAAAGATTCTACAACTCCCCCAGCAGACCAGATAGCGACCGCTGTTTTAAAGCCTACTACAGCTGAGGCAATAGAAGAAAGTGTGCAAAGACAACAGACTTTGCAAGAAGTTAAATTAGAAGAACCCATTAGTGAGACTGCTTCAGCCCTAAATCAAGAAACAAAAATCATAGAAATATCTGAACAAAAATCTGAACAGACTGTCAATTTCGAGAGCGTAGCTAAAGAATCCAAAGAATTTGAACTAAACGCTACTGAAGAAGTTAAAAAATTAGTTGGAAAGGCACACGAGGAAAGCGCTTCTGCAGGCGGTCAAACTGTAACCACAGAGGAGATTGGTGACGACGAGATGTCGAGGTATAGCCGCAGTTCGCGGATATCTGGAGAGTACTCCAGCAGCGCTAGAAAATCATCTACTGGTGGACGATATGAGTCCTCTACTTATGACAGCACTGGTCTATCATCATATTCACGACGCGAGAGCGGATCACGTCTCGAAAGTGCGAGATATGAAACTGGCGGATCTACTGAAGGCGGAGTCTCCTCGCGCTACGAATCTAAGTACTCGAGCTCATCAAAGATAGAAGGAGGTTCCAAATATGGCATTGAGTCTAGCTATGAAAGCAAAGTAGACGGATCCAAATACGGAATTGATTATGATTCCAGCAGCAAACGCAATAGTATTGCTTCTAAATATGGGGTCGAAGCTGAAACGAACAGCAAAATTGATGGCATTGCATCAAAATATGCCATCGAGTCAGAAACTACAAGCAAAATTGACAGCATTGCTAATAAATACGGAATTGATACCGAAAAAGCAAGCAAGATTGATGGAACCGCATCTAAATATGGAGTAGAATCAGAAACCACAAGCAAAATTGATAGTATTGCTTCTAAATATAGGAAAGAATCCGAGGGCTCCATCAAAGTTGATATGGTTTCGTCTAAGTATGGCGTGGAATCTGAAACGTCTAGTAAAATTGACAGTATTGCATCAAAGTATGGCATTGAATCAAAATACGAAGCTGAAGGACGTTCATCTAAATATAGCTCTCAAATCAGTTATGACGGCAATAAGGTTGACGGTGTATCTACAAAGTTAGAAAGTAGTTTCGAGAGTTCTAGCAATGGAGGCTCAGTCTACGAGAGCAAATATTCTAAGCGAGCCATTTCCAACGGCGTACATTCTGAAGAGTCTGAATTACAGAGGTCTATTTCCAAGTCTGAAGCTCAGGATGGAAGACCAGTGTTCTCAAAAACTCTCGAAGGCCAAAACATCGAGCTGACGCCGGAAGAAAGAAAGCAGAGGAATGCTCTAAACGCTCCGTACTTCTTAGTAGCCTTGAAGGACACTGAGATCATGGAAAATACCTACTTGCGTTTCATGATCAGAGTCAAGGGCAATCCCAACCCAGAAGTTAAGTTCTACCGCGACGACAAAGAGATCGTGGCGAAGTCGGATACGGACCGTATCTCCATCATCACGACCCGCGCCGACCGTGGCTGCTACGAACTGGTGATCCCAGACGTGACTCCAGCCGATGCGGGCAAATACTCCTGCAGGGCTATGAATATTTACGGCGACGTCGTTTCCGAAGCTAAAGTTACCGTTGTTGATGACAAAAACATATTTGGTGAACTGCTTCCTGGTGGTGATGGTCTGCTGGCTAAAGGCGAGAAGCCAGCTTTCACGTGGAAGAAAGATGGACAGCCCTACGATCCTGAAGAACGATTCAAGGTTCTTCTTGGTGACGACGAAGACTCCCTGGCGCTGGTGTTCCAGCACGTGAAGCCGGAGGATGCTGGGTTGTACACGTGTGTGGCTAAGACCAGTACAGGAAATATATCTTGCTCAGCCGAGCTTACTGTTCAAGGTGCCGTGAACGAACTTCACCGGGAGCCAGAGAAGCCGACCCTGGTGATCGAGCATCGGGACGCTATCGTCTCGATGGGCGCCTCGGCCATGCTGGAGCTACAATGCAAGGGCTTCCCGAAGCCGAGTGTCGTGTTCAAGCATGACGGGAAGGTGGTGGAACCAGACACCAGACATAAGTTCTTGTACGAGGATGAAGAGAGCATGTCTCTTGTGATAAAGAACGTGACGTCAGCAGATGCCGGAGAGTACCAGGTGACGGCCAGCAATGAGCTCGGTGAAGACACTTCCACCATGAACCTAGTGGTGAAGGCGCCGCCGAAATTTAAGAAGAAGATCGAAAATCAAACCTGCATGGTCGGCACGACTCACACCGTCATAATAGAAGTGGAAGGAACACCTTCACCAGACCTGACATTCTACAAGGACGGAACTGAAATCAAGAGCTCTGAACGCATACAAATCGTTAAAGAGAGTGAGGAAATATACAAGATCACAATTAAAGATGCCAAGTTGACCGACACTGGATCGTATTCTGTAGTAGCTAAGAACGAAGTGAACCAATGCTCTGAGTTCTGGCAATGGCACGTGACGTCACCGCCCCGACTCGTGAAGAAGCTGGGCGGCTCCAAGGTCGTCGACGAGAAGGAGACAGTCACTTTCAGCATCGAAACCGAAGCTGAACCGGCACCGACTGTCAAATGGTTCAAGAATAAGACGGAATTGACGGAGTCGTCAACGGTGAAAATCTCATCATCCGGGTCGGCTCACTCCCTCGTGATCACGTCTGCCGCAAGGGCTGATGCTGGAGAGTATTCTTGTGAGGTCCGTAACGTGCACGGCGAGGCGAGTGACGTCAGCACATTGAACGTCCGCTGCGGTCCGGTGTTCACGGAGCGCCTGCGTGACGTCACGGCCAGCGAGGGTGACGTCAATGTCGAGTTCACGGTCGCCGTTGATGCATTCCCGCAACCCACCATTCGATGGTACTTGGGAGACGTGGAGGTCACAGAAAAGAAGTCTGTGTTCACTCGCGTGGATAGCGGCAACACGCACAAGTTGATCCTCAAGGAAGTGTCGGCTGAATATTCCGGACAGTACACATGTAAAGTTTCCAACGAACTGGGGGATGACTCCTGCCAGGCAACTTTCACTGTTAACAGAAAACCCCGGTTCACTAAGAGCCTGGTGGATATGACCGTCGACGCAGGTCAGACCCTAAAACTTGATGTGGAAGTTGAGGGCAGCCCGGAACCCAAGGTTCGCTGGTTTAAAGATGGAAAAGAAGTCACTACTGATGCCAGAATTAAAATAGAAAGAGACACTAAGAGGCTCGAAAATTATCATCTCACGGTGACATTAGTGAAGGAAGAAGACGGTGGCGAATACGAAGTTAAAGCTGAGAATGAGATGGGAAGCGTGTCATCGAAGAGTACAGTCACAGTCCACACGAGGGAAGTCCACTCGAGGATCACTAAGGAAGAAGTGGAAAGTGAAATTGATGCGAAGGCAAAACAACCTTTAGAGGAAGAAGTTGAAAGTTCAATAACGGGGGAAGTTCACTCGAAGATCACTAAGGAACAAATGCAAAGTGAAATCGATGCGAAGGCAAAACAGCCTCTTGAGGAAAAAGTTGAAAGTTCAATAGCGGTGGAAGCTCACTCGAAGATCACTAAGAAAGAAGTGCAAAGTGAAATCGATGCGAAGGCAAAACAGCCTCTAGAGGAAAAAGTTGAAAGTTCAATAGCGGTGGAAGCTCACTCGAAGATCACTAAGAAAGAAGTGCAAAATGAAATCGATGCGAAGGCAAAACAGCCTCTAGAGGAAGAAGTTCAAAGTTCAATAGCGGGGGAAGTTCACTCGAAAATCACTAAGAAAGAAGTGCAAAGTGAAATTGATGCGGAGGCAAAACAGCCTTTAGAAGAAGAAGTTGAAAAAACACAAAAACTTAGTGCAAAAAAAGAAAAATCAGCATCGGAAACAATCGAAGAAAGATCTATTTGGGAGGATGATGATGCCGAAAAAGCTAAAAAACCAATCATTGAAGAATCTGAAGTTCCCAAGCCAAGTAAGGGTCGTAAGTCGCTTTCAGAGCCGGATACAGTGGAAGAGAAATCATTTTGGGATGATGTAGGTGATGACGAAAAACCAAAGAAAGTAACATTCGAAGACACCGATAAACCTGTGAAGAAGAAAGGTAGAAAATCTATCTCAGAAGTCATAGAAGAAAAGTCTATTTGGGATGACGATCGTAAAGAGGAAAATACAAAAAATATTGTTATTGATGAAGTTGAAACTCCACGCCGTGATAAAGCAAATGAATCTGTCACAGAGCCAGAAATATCCGAAGAGAAATCTTTTTGGGATGATAGTGACAGCAAATCATCAAAGAAACCTAAAGTGGCAGAAGTAAACAGTGAAAAAGTCGACAAAGGCTCAAAATCCAGCACTCCGCTTGAAGTAGCTGAGGAAAAAAGCATTTGGGATGAAAACCACAATGAAAAGATCAAGAAACCTATCGTTGAAGAGGTGATCGTTGAAAAGAAAATCGGTGATACAAGCGTCACAAAACCTGAATCAATAGAAGAAGTACCTCTGGATGAAGAACTCAAATCATCCAAACGTAAATCTTTGAAAAAAGAGTCTGTTTCAGAAGAACCATTAAGTGCTGAAGTCGAAGGACGAGTTTTTGAAACAGTAACTACTTTCAAGAAAGGTGACGATGGATCTATCATAATGTCTAAAGTAAGCAGCAGCAGGTCTCATGGTGCTATCGTCACAGGTCCCGCTGAAACGCACACTTTACATAAAATGACATCGAGCACTGTTTATTATGAGGACGATGACGAGTTCGAAAGTAGAAAGATTATAAAACCAAATCAGCCACATACAACTTCATTGGAAGTTGAAGAAATAGCCAGCCATAGTTATATGCTGTCGGAAATGGGTCATTTTACCATACCAGATTACATCAGGCGTGGAACTTACGGCATAATTGAAGAGCCTCAAACTGATTCTGATGCGGAAAGTACGAGAGGCATTAAGAATTATAACAACAGAACTGTGTCAATTATGTCCATGTCCGAGGATGAAATGAGCTGGCACAATGAATCTTTATCACGCGAAATTTCCATTGAAGACCTTTCGAAATCTATCTTTGATATTGACGATACTAGAAAAGTTTTCAGTAAAGACTCATATGTACGTCAGTCATCTTTCAAAGAGGACTATTTCACTAATAAAGGTGATGAAGAATCCTTAATTCTCAAAGAAAAATCAGAAAAAGTATTCGAAAACGATATCACAGAGAAACTCATTCACATCTCAAAAGATTTCGACGAAAATGAATTTAAAAATATTAAAAGTAAAGTAGATGATGTTAGAAATAGACTTATTGAAGAGTTAGTCATTGGGCCTGACAGAAAATTAGATAGCTTAACAAAAGACGTAACCGAAATGACCGTAGAAAGAAAACGAAAGGGAGAGGCAAAATTGTTTAGCGTTCAGGAAGAAGCGAATGACCAACAAGTGGACGATCTGTTGAAACGAAGCCAGAGACAGAGAAGCATCCTCGATGATATTCTAAATAAGGAAGACGAAAAAGCATCACCTACCTTAAAAGACAGTTCCTTCAAGGACAAAGAGGTATACGAGTCCCTTCCACTAGTTTACACGGTTGAAGCATCCGGGACTCCTAAGCCGGCAATTCGCTGGCTTCACGACGGTAAGGAAGTAAAGCCTTGCGGCAGAGTTCACATCACCAACGAAGGAGATCTTTATAAATTGGAGATCGATAGAGTTAATTTGGATGACGCTGGACAATGGCAGTGCGAGATTAGCAATGACCTCGGCAAGAATGTACTGAAGGCCGATTTGACGGTAAAACCCGAAAGTGAGCTCCGCAAGCCAAAGTTTACGCAACCTCTAGAAGCCCAGCGCATTCTTCAACGGGAGCCCGTCAGTCTCCAAGCTGTTTGTACAGCGGACCCTCAACCACATGTGTCGTGGCTTCTTAACGGAGTAGAATTGACTCCCGACGCTACAATCGTGACGTCAGCCGATACAAAGGATATTGAACATGGTTTGAAAGAGTGCACTTTCACCCTGCAAATTCCCACTGGTCGCCATGCTGATACCGGTAACTATACCATCCAAGCTAAGAACAAATACGGTGTTGGTGAAAGTTCTGCTCGTCTCGACATTCTGCTGAGACCAGAGATCGAAGGTCTCAAGGATGTTTCTGCCGTACCTTATGAGGAGACCACCTTCGTTGCCAACGTCCGAGCTAACCCCATTGCTGAGATTCAGTGGAGTAAAGACGGATACGTTATCAAACCATCGTCTCACATCGAGATAAGCGAAGACAAAGATGCTGAGAAGTATCAGCTCACTGTTAAGAAGGTCGGAATGGACGACGCTGGTGTATACACGCTGACAGCCAAGAACGAGATCGGTGAAACCGCCCAACAAGCTAAGCTCATCATACGCACCGGCGAGCCAATCTTCACTAAGCCTTTGAAGAAGCAAACGGTGAAAGACTACGATGATTGCACGCTGAAGGTGCGCTGCGACGGCGAACCGAAACCGGAGGTGAAGTGGTACGTGAACGGCAAGGAGATAACCAACGATGACCGTCACACCGTCACCACGGAAGTCGGTGGTCAGGTTGACAGCGAGCTGGACATCAAGCACTTCAATAGTGACGATACTGGAAAGTACAAAGTTCGCGCGTTGAACTTGGCCGGTGAGGCGTCTTGCGAAGCTCAGATAACGTTAGCGCAGCTAGCCCCAGGGTTCACACACCGTCTGGACAGGCAGAAGGACGTTGACGAAGGGGAACCTCTCGAGCTGAAGGCTAAGATCGACGGCAGCCCTACTCCAACTGCCACTTGGTACAAAGACGGTGTTCCGATTCCCGCAGACGACGATCACGTGAAGCAGTCAGCTCTGGCCGAGGGCTGGGTCAAACTGAACATCGCTGAAGTGACCCCCTCCGACTGCGGAGCGTATAAACTGGTCATATCCAACCCTAACGGTGACAACTCGGCTTTGTGTGCAGTCGCTGTTAATCCTACACCAAGGAAGCCATCGTTCAGTCAAGAGCTAGAAGACGTAAAGGCAGTAGTGGGTCAGCCATTGAAACTAGAAGCCAGGGTGATGGCCTTCCCAGCGCCAGAAGTCAAGTGGTTCAAGGACGGCTTGCCGGTCCGTCCATCACAGGCGATCAACTTCATCAATCAGCCGGGCGGAGTCGTCGGTCTCAGCATCGACAACTGCAAGCCGGAAGATGCTGGAGTCTACTCACTCACCGTCACCAACAAACTCGGAGAGGTCGGTTCAAAGGCGAATGTCGACGTAACTCAAAAGGAGCGGAAACCAGCCTTCATAGCAGAACTACAACCTACCAAGGTCATTGAAGGATTCCCGGTCAGACTGGAAGTCAAGGTGCTTGGACATCCGCCACCTACTATCAAATGGACACTTGACGGTAAAGAGTTGGTTCCGGACGGCGTCCGTATTCGTGTGGTGTCACAGCCAGACGGGACACACGCGCTGCTCATCGCGGCCGCTACGCCATCCGACGCTGGACGATACGGAGTCGTCGCCAACAATGACAAGGGCGAGACCAAGTCTGAAGCAGACCTGACCGTGTCCAGTCGCCAGGACGACTCGAACCCACAAGAGCGGCCGCAGTTCATCCACGGCCTCAGGGATGTGACGGCAGCGGAGGGACAGCCTCTCTCGGTGACCGCGCCCTTCGTCGGCAACCCTGTCCCCGAGGTCACGTGGACTAAGGACGGACAACCCTTGAAGCCAGACGAGAAGATCCTGCTCACGTGCGACGGGAAACGGGTGGGTCTAGAAATAAACCCTGTGGAGCTGCCGGACGCGGGGGTGTACTCCGTGAAGCTGGTCAACCCTCTGGGTGAGGACAGCTCTGAAGGCAAGATCACCGTTAAGAAGGTTTACCAAGCACCCACCTTCTCCCAGCGGTTCACTGACCTGCAGCAGTTACCGACATTCGACGCCAAATTCCCTGCTCGCGTGTTCGGCATCCCCTTCCCCGACATCTCCTGGTACAAGGACGGAGTTCTTCTGAAGCACTCCGACAAATATAACATCAAACGCGACGGCGACGCTGCCTGTCTGTACGTCAGAGATATCGGACCGGACGACGCTGGAGTGTACAAGTGCGTCGCCAAGAACAGGGAGGGCGAAGCCGAGTGCCAGGCTAGTCTCGAAGTCGTTGATAAGATCGCCAGGCAGCAGAAGGTGGAGCCTCCGTCGTTCCTGAAGAAGATCGGAGACATCGAGGTGCTTCGCGGCATGAGCGCCAAGTTCACCGCCTGCGCCACCGGCTCCCCAGAACCCGACGTGCAATGGTATCGCAATGACGAGAAGCTGTTCCCTTCGGACCGGATCCGCATGGACAAGGAGAGCACGGGGCTGCTGCGGCTGAACCTGAGCCGCGTGGAGCCCTGCGACGTGGGCACCTACCGCTGCACCCTCACCAACCCTCACGGGGAAGCCTCCTGCACAGCACAGCTCACCTATGACAGTATGGAGCCGCACGCAAGCAAACGTCCAATCTCGGACCAGTACTCTGACTTCGATAAGATGAAGAAGACCGGCATCCCCATGCCCCTGGCTGACCGGCCCATCATCTCGCGCATGACCGATAGGCACCTCACCTTGTCCTGGAAGCCGTCCATCCCTCATGGACCTCGCTTCCCGGTCACATATCAGGTGGAGATGTGTGAGGTCCCTGACGGCGACTGGTTCACCGCCCGCACGGGGCTGCGCTCGTGTGTGTGCGACATCCGCAACCTCGAGCCCTTCCGCGACTACAAGTTCCGCATCCGCGTCGAAAACAAATACGGGGTCAGCGATCCCTCGCCCTTCGCCATCACGCACCGCGCCAAGCTGGAGCCCGACCCTCCGAAGTTCGTCCCCTACCTAGAGCCCGGCATCGACTTCCGCCCGGAGACCTCGCCTTACTTCCCTAGGGACTTCGATATCGAGCGTCCGCCCCATGACGGGTACGCTCAGGCTCCTCGCTTCCTGCGTCAGGAGCATGACTCGCAGTACGGGGTCAAGGGACACAATGTCAACCTGTTCTGGTTCGTCTACGGCTACCCGAAGCCCAAGATGACGTACTTCTTCAATGATGAACCGATCGAAATAGGCGGCAGATACGACTGGAGTTACACGAGGAACGGCCAAGCCACGCTGTTCATCAATAAGATGCTGGAACGTGATGCTGGCTGGTACGAAGCCGTCGCCACCAACGAGCACGGTCAGGCTCGACAGCGAGTCCGGCTGGAACTAGCAGAGTATCCCACCTTCATACGCAGACCTGAGGAGACAGTGGTGCTGCAGAGGAGGACCGTCCGACTGGAGGCCAGAGTCACGGGAGTGCCGTATCCTGATATTAAATGGTACAAGGATTGGCAGCCATTGGCACCGAGCTCCAGAATCAAGATACAGTTCATCGAGCCGGACACGACGGTGCTGGTGATCAAAGACGCGATCCTGAAGGACGAGGGTCTGTACTCCGTGTCCGCGAGGAACGTGGCCGGCTCTGTCAGCTCCTCGGCCATGCTGCACGTAGAGGAAGACGAATATGAATACGCTGACAGGATCCGCGAGCACCCGCCCCGCGTGAAGGCCAGCACGAAGCCGTTCGGAGACCAGTACGACCTGGGCGACGAGCTGGGCCGCGGAGTCCAGGGCGCCGTGTACCACGCGGCCGAGAGACTCACCGGACGCAACTACGCTGCGAAAATAATGCACGGTCATTCCGAACTGAAGCCATTCATGAAGAACGAGATAGACATCATGAACCTGCTCAACGACCGGCATCTGATCCGGCTGTACGGAGCGCACGAGCATGACCACACCGTGGCGCTGGTCACGGAGCTGGCGGCGGGAGGGGAGCTACTCAGGGACGGACTCCTGCGGGTTCCTTCCTATCCTGAGCGACGGGTTGCCTCTATCATCAGGCAACTGCTACTGGGACTAAGGCATATGCACGATAACAGCGTAGCGCACCTTGGACTAACGATCGGCGAACTCTTACTCTCGCACGCCGGCAGCGACGATATAAAGATATGCGACTTCGGACTATCACGCCGCATAAGACACAACGAACTGGGCGCCCTCCACTACGGGATGCCGGAGTATGTAGCTCCCGAAGTGGCCAACGGCGATGGCGTCTCCTTCCCAGCCGACATGTGGAGTGTCGGTATCATAACCTACATCCTGCTCAGCGGACACTCTCCATTCCGAGGTCAAAACGACCGCGAGACTCTGACGAGAATTAAGGAAGGCACTTGGAGCTGGCACGATGAGGAATGGTGGTCTCGCCTCAGTACGGAGTCCAGGGACTTCATTTCGAAGTTGTTGGTGTTTAACTGGCACGAGCGTATGGACGTGAGGACGGCTCTGTCGCATCCATGGCTGACGCTGGCGGATCGAATCTACCAGGAGGAGTACCAGATCTCGACTGATCGATTGAGGAACTACTACAATTTGTACAGAGACTGGACAAGTAACGCACAATGCCGCACGTGGTTCCGGCGTCGGCCGCTAGAGGGCGCCTTCCATCATCCCTCTAAGATGGTGTATCCACCCGGGGAAACGTACACACCAGAAGGAACTCCAGACCGCGACATCAGCACCCGCGACCGTAAGCCAGCAGAGTTCGATCTCAACTTCAAGCAGTGGGACCATCCCGACTGGGAGGTTTCCGCCACCTCTGAGAGCCATTACCAGAACGGCCCGGACACGTATCTGCTGCAGCTGCGGGACACCCAGTTCCCGGTGCGGCTCCGGGAGTACATGAAGGTGGCCTGTCACCGCTCGCCGGCATACAGCATCAACGCCTTCGACAACTACGACCCCAGGACCCCGATTATACGAGAACGTCGTCGCTTCACCGACATCATGGACGAGGAGATAGACGACGAGCGCCGAGATCGGATCAACGGGTACGGGAGCGAGTCCGGCACCGTGCGGAGGCTGCGACACGAGCTGGGCACGCGGCTCGACTCCTACGCCGAGGCTCAGGCCTTCATGGAGGCCAAGAAGGACGGCTGTCTGCCCTTCTTCCGCGAGAAGCCGCAGCTACTACCGGTCAGGGAAGGTGAACCCGCCAAGCTGTCCTGCTTCGCGGTCGGCGACCCCAAGCCCGTCATCCAGTGGTTCAAAAACGACATGGTCATCGCTGAAGGACAACGCATCAAGATCGTGGAAGACGAAGAGGGACGCTCTACTCTCGAGTTCAATCCTTCCATGCATCACGACATCGGATTCTACAAGGTGGTCGCCAGGAATAAAGTGGGGCAGACTGTCGCCCGCACCAGGGTTGTAGAAGCTACCACTCCTGACGCTCCTGACGTTCCCACCGCTGCGGAGGTTTCAGACACAGAAGTGTTGTTACGCTGGAAACAACCCAAGTACGACGGCAACTCGCCTGTCCTCTGCTATAGCCTGCAGTACAAGGCCGGCGACAGCGTCGAGTGGAAGGAGGTTGCCAACAACATCGACCACGAGTTCTTCGTCGTCCGAGATCTTAATCCGGACACCAGCTACCAGTTCCGCCTCTCCTCCAGAAACCGAATAGGCTGGAGCGAGAAGGGTGCTCCCACCAACCTTGTCAAGACGCGTGAGGCTGGTGCGAGCAAGATCGAAGTCACAAAAGCTATGAGGCATCTTCAACAGCTCACCGAATCCGGCCAGGAGATTGTTCTCGATGAAGAAAAGCCGCAGTTAGACTACTCGACCGAGAAGCAGCCCGTGGAATGGTACAGCGCCAATACGTTCACAGAGCGGTACAGCTTCATCTCGGAGCTGTGGCGCGGGAAGTTCTCCATTGTCGTCAAGGGAGTTGACAAGACAAACGACACTGTCGTGGTCGCCAAGATCCTCGAGAACAGACCAGAGACCGAGGTCCTGGTCCAGCGAGAGTACGAGTGTCTGCGAAGGCTGCGGCACGAGAGGATCGCAAACCTGCTCTCAGCGTACAGAGCTCCCGGCTCCCCGGTTTCCGTTCTGATCTTGGAGCGACTACAAGGGGCAGACGTGCTGACGTTCCTGGCAAGTCGCCATCAGTACTCGGAGCAGCTGGTGGCCACGGTGATCACGCAGGCGTTGGACGGACTACAGTACCTGCACTGGCGCGGGTACTGCCACCTGGACCTACAGCCAGACAACTTCGTCATGGCCTCCGTCCGCTCGGTGCAGGTCAAGCTCGTGGACTTTGGATCTGCTCATAAAGTCACCAAGCTCGGCACCAGTGTGCCGCAGGTCGGACATCTAGAATACAAAGCCCCGGAAATAATAAACGACGAGCCAGCGTATCCTCAGACGGACATCTGGTCTATCGGAGTCCTGGCCTACATCTTGCTGAGCGGAGTATCTCCCTTCAGAGGAAACGACGATAACGAGACCAAACAGAACATCTCCTTCGTCAGATACAGATTCGAGCATCTGTACAGCGAGATCACGCAGGAGGCTACCAGATTCCTGATGTTCGTCTTCAAGAAGGTTCCCCTGAAGCGTCCGACGGCCGAGGAGTGTCACGAGCACCGTTGGTTAGCGCAGTCTGACTTCATCAGCAAGAAGAGAGAACGAGCTATCTTCTCAAGCAGTAAACTTAAGGAATTCTCAGATGAATACCACGAACGTAAGGCCCATGAAGCATCGCAAGCCGACACGTTAACCGAAGCCTTCGGTCAGTTCGCACCGAGACTGCTCACCAGGTCCAACAGCATCCAAGAAGAACTGCTCACGAACCTCTCTAGCCAATAA
Protein
MQQVVSRYMKPIDKATAPKPVFDNRELLFSNFRQICEFHNTVLLEGIKYYAGEPRMLGRALLRMEREFDKHVAYCRDEPRAQYLLANDPVVKKYFQNWVLVNVNLQDLADSLGDDKGITEHLKLPIQRINDYQLLLKELVKYSRRLGEDCNDLQKALELFLGVPNRATDNKFLASIEGFRGNIYKLGRLLTHDWFTVTDQEGRTKDRYLFLFKARILVCKVKRISQDRSVFVLKDIIKLPEVEVKEVTGEPLKFELRQKNPPLDLIVGAHKEHVKNTWLAEINKHASDIVALAEHAADDLQVLQAVETKETAEEKKKKREHTEEVIVKAEQEVKEKRSRTEDIEVTQVSVKEETSQQVKVKRKASVESTVATKISKSEVVEVFSLNENQESVVSAIDTEVRSDVTTDLETKSSVTVSALNAETEPVTSQLESQQTLKTEHTEAKVEEQIVQASQTTEEYVEKSIKTTKQSSVVETTESFQEIRSLEQDSTKISTEDRITVREEEEPIHAIQECTNTQERSDESFETVKQIPEISKETAENEILETTKESSETVIQVSESLSETVSETVIAVSETEETLQTFEQKDSTTPPADQIATAVLKPTTAEAIEESVQRQQTLQEVKLEEPISETASALNQETKIIEISEQKSEQTVNFESVAKESKEFELNATEEVKKLVGKAHEESASAGGQTVTTEEIGDDEMSRYSRSSRISGEYSSSARKSSTGGRYESSTYDSTGLSSYSRRESGSRLESARYETGGSTEGGVSSRYESKYSSSSKIEGGSKYGIESSYESKVDGSKYGIDYDSSSKRNSIASKYGVEAETNSKIDGIASKYAIESETTSKIDSIANKYGIDTEKASKIDGTASKYGVESETTSKIDSIASKYRKESEGSIKVDMVSSKYGVESETSSKIDSIASKYGIESKYEAEGRSSKYSSQISYDGNKVDGVSTKLESSFESSSNGGSVYESKYSKRAISNGVHSEESELQRSISKSEAQDGRPVFSKTLEGQNIELTPEERKQRNALNAPYFLVALKDTEIMENTYLRFMIRVKGNPNPEVKFYRDDKEIVAKSDTDRISIITTRADRGCYELVIPDVTPADAGKYSCRAMNIYGDVVSEAKVTVVDDKNIFGELLPGGDGLLAKGEKPAFTWKKDGQPYDPEERFKVLLGDDEDSLALVFQHVKPEDAGLYTCVAKTSTGNISCSAELTVQGAVNELHREPEKPTLVIEHRDAIVSMGASAMLELQCKGFPKPSVVFKHDGKVVEPDTRHKFLYEDEESMSLVIKNVTSADAGEYQVTASNELGEDTSTMNLVVKAPPKFKKKIENQTCMVGTTHTVIIEVEGTPSPDLTFYKDGTEIKSSERIQIVKESEEIYKITIKDAKLTDTGSYSVVAKNEVNQCSEFWQWHVTSPPRLVKKLGGSKVVDEKETVTFSIETEAEPAPTVKWFKNKTELTESSTVKISSSGSAHSLVITSAARADAGEYSCEVRNVHGEASDVSTLNVRCGPVFTERLRDVTASEGDVNVEFTVAVDAFPQPTIRWYLGDVEVTEKKSVFTRVDSGNTHKLILKEVSAEYSGQYTCKVSNELGDDSCQATFTVNRKPRFTKSLVDMTVDAGQTLKLDVEVEGSPEPKVRWFKDGKEVTTDARIKIERDTKRLENYHLTVTLVKEEDGGEYEVKAENEMGSVSSKSTVTVHTREVHSRITKEEVESEIDAKAKQPLEEEVESSITGEVHSKITKEQMQSEIDAKAKQPLEEKVESSIAVEAHSKITKKEVQSEIDAKAKQPLEEKVESSIAVEAHSKITKKEVQNEIDAKAKQPLEEEVQSSIAGEVHSKITKKEVQSEIDAEAKQPLEEEVEKTQKLSAKKEKSASETIEERSIWEDDDAEKAKKPIIEESEVPKPSKGRKSLSEPDTVEEKSFWDDVGDDEKPKKVTFEDTDKPVKKKGRKSISEVIEEKSIWDDDRKEENTKNIVIDEVETPRRDKANESVTEPEISEEKSFWDDSDSKSSKKPKVAEVNSEKVDKGSKSSTPLEVAEEKSIWDENHNEKIKKPIVEEVIVEKKIGDTSVTKPESIEEVPLDEELKSSKRKSLKKESVSEEPLSAEVEGRVFETVTTFKKGDDGSIIMSKVSSSRSHGAIVTGPAETHTLHKMTSSTVYYEDDDEFESRKIIKPNQPHTTSLEVEEIASHSYMLSEMGHFTIPDYIRRGTYGIIEEPQTDSDAESTRGIKNYNNRTVSIMSMSEDEMSWHNESLSREISIEDLSKSIFDIDDTRKVFSKDSYVRQSSFKEDYFTNKGDEESLILKEKSEKVFENDITEKLIHISKDFDENEFKNIKSKVDDVRNRLIEELVIGPDRKLDSLTKDVTEMTVERKRKGEAKLFSVQEEANDQQVDDLLKRSQRQRSILDDILNKEDEKASPTLKDSSFKDKEVYESLPLVYTVEASGTPKPAIRWLHDGKEVKPCGRVHITNEGDLYKLEIDRVNLDDAGQWQCEISNDLGKNVLKADLTVKPESELRKPKFTQPLEAQRILQREPVSLQAVCTADPQPHVSWLLNGVELTPDATIVTSADTKDIEHGLKECTFTLQIPTGRHADTGNYTIQAKNKYGVGESSARLDILLRPEIEGLKDVSAVPYEETTFVANVRANPIAEIQWSKDGYVIKPSSHIEISEDKDAEKYQLTVKKVGMDDAGVYTLTAKNEIGETAQQAKLIIRTGEPIFTKPLKKQTVKDYDDCTLKVRCDGEPKPEVKWYVNGKEITNDDRHTVTTEVGGQVDSELDIKHFNSDDTGKYKVRALNLAGEASCEAQITLAQLAPGFTHRLDRQKDVDEGEPLELKAKIDGSPTPTATWYKDGVPIPADDDHVKQSALAEGWVKLNIAEVTPSDCGAYKLVISNPNGDNSALCAVAVNPTPRKPSFSQELEDVKAVVGQPLKLEARVMAFPAPEVKWFKDGLPVRPSQAINFINQPGGVVGLSIDNCKPEDAGVYSLTVTNKLGEVGSKANVDVTQKERKPAFIAELQPTKVIEGFPVRLEVKVLGHPPPTIKWTLDGKELVPDGVRIRVVSQPDGTHALLIAAATPSDAGRYGVVANNDKGETKSEADLTVSSRQDDSNPQERPQFIHGLRDVTAAEGQPLSVTAPFVGNPVPEVTWTKDGQPLKPDEKILLTCDGKRVGLEINPVELPDAGVYSVKLVNPLGEDSSEGKITVKKVYQAPTFSQRFTDLQQLPTFDAKFPARVFGIPFPDISWYKDGVLLKHSDKYNIKRDGDAACLYVRDIGPDDAGVYKCVAKNREGEAECQASLEVVDKIARQQKVEPPSFLKKIGDIEVLRGMSAKFTACATGSPEPDVQWYRNDEKLFPSDRIRMDKESTGLLRLNLSRVEPCDVGTYRCTLTNPHGEASCTAQLTYDSMEPHASKRPISDQYSDFDKMKKTGIPMPLADRPIISRMTDRHLTLSWKPSIPHGPRFPVTYQVEMCEVPDGDWFTARTGLRSCVCDIRNLEPFRDYKFRIRVENKYGVSDPSPFAITHRAKLEPDPPKFVPYLEPGIDFRPETSPYFPRDFDIERPPHDGYAQAPRFLRQEHDSQYGVKGHNVNLFWFVYGYPKPKMTYFFNDEPIEIGGRYDWSYTRNGQATLFINKMLERDAGWYEAVATNEHGQARQRVRLELAEYPTFIRRPEETVVLQRRTVRLEARVTGVPYPDIKWYKDWQPLAPSSRIKIQFIEPDTTVLVIKDAILKDEGLYSVSARNVAGSVSSSAMLHVEEDEYEYADRIREHPPRVKASTKPFGDQYDLGDELGRGVQGAVYHAAERLTGRNYAAKIMHGHSELKPFMKNEIDIMNLLNDRHLIRLYGAHEHDHTVALVTELAAGGELLRDGLLRVPSYPERRVASIIRQLLLGLRHMHDNSVAHLGLTIGELLLSHAGSDDIKICDFGLSRRIRHNELGALHYGMPEYVAPEVANGDGVSFPADMWSVGIITYILLSGHSPFRGQNDRETLTRIKEGTWSWHDEEWWSRLSTESRDFISKLLVFNWHERMDVRTALSHPWLTLADRIYQEEYQISTDRLRNYYNLYRDWTSNAQCRTWFRRRPLEGAFHHPSKMVYPPGETYTPEGTPDRDISTRDRKPAEFDLNFKQWDHPDWEVSATSESHYQNGPDTYLLQLRDTQFPVRLREYMKVACHRSPAYSINAFDNYDPRTPIIRERRRFTDIMDEEIDDERRDRINGYGSESGTVRRLRHELGTRLDSYAEAQAFMEAKKDGCLPFFREKPQLLPVREGEPAKLSCFAVGDPKPVIQWFKNDMVIAEGQRIKIVEDEEGRSTLEFNPSMHHDIGFYKVVARNKVGQTVARTRVVEATTPDAPDVPTAAEVSDTEVLLRWKQPKYDGNSPVLCYSLQYKAGDSVEWKEVANNIDHEFFVVRDLNPDTSYQFRLSSRNRIGWSEKGAPTNLVKTREAGASKIEVTKAMRHLQQLTESGQEIVLDEEKPQLDYSTEKQPVEWYSANTFTERYSFISELWRGKFSIVVKGVDKTNDTVVVAKILENRPETEVLVQREYECLRRLRHERIANLLSAYRAPGSPVSVLILERLQGADVLTFLASRHQYSEQLVATVITQALDGLQYLHWRGYCHLDLQPDNFVMASVRSVQVKLVDFGSAHKVTKLGTSVPQVGHLEYKAPEIINDEPAYPQTDIWSIGVLAYILLSGVSPFRGNDDNETKQNISFVRYRFEHLYSEITQEATRFLMFVFKKVPLKRPTAEECHEHRWLAQSDFISKKRERAIFSSSKLKEFSDEYHERKAHEASQADTLTEAFGQFAPRLLTRSNSIQEELLTNLSSQ
Summary
Description
Structural component of the muscle M line which is involved in assembly and organization of sarcomere (PubMed:22467859, PubMed:26251439). Required for the development and organization of indirect flight muscle sarcomeres by regulating the formation of M line and H zone and the correct assembly of thick and thin filaments in the sarcomere (PubMed:22467859, PubMed:26251439). Likely to have serine/threonine-protein kinase activity as one of the two protein kinase domains appears to be functional (Probable).
Structural component of the muscle M line which is involved in assembly and organization of sarcomere myofilaments (PubMed:15313609, PubMed:16453163, PubMed:18801371, PubMed:22621901, PubMed:23283987, PubMed:27009202). The large isoform a, isoform b, isoform d and isoform f play an essential role in maintaining the organization of sarcomeres but not myofilament alignment during body wall muscle development whereas the small isoform c and isoform d appear to have a minor role (PubMed:15313609, PubMed:16453163, PubMed:22768340). Isoform b and isoform f are required for the organization of unc-15/paramyosin into sarcomere thick filaments in body wall muscles (PubMed:27009202). By binding mel-26, a substrate adapter of the cul-3 E3 ubiquitin-protein ligase complex, regulates the organization of myosin thick filaments, likely by preventing the degradation of microtubule severing protein mei-1 (PubMed:22621901). Acts as guanine nucleotide exchange factor (GEF) for Rho GTPase rho-1 but not ced-10, mig-2 and cdc-42 (PubMed:18801371). The large isoforms regulate Ca(2+) signaling during muscle contraction by ensuring the correct localization of sarco-endoplamic reticulum Ca(2+) ATPase sca-1 and ryanodine receptor unc-68 (PubMed:22768340). By controlling the contraction and/or organization of pharyngeal muscles, plays a role in the formation of pharyngeal gland cell extension (PubMed:21868609). In contrast to obscurins in other species, unlikely to have serine/threonine kinase activity as both protein kinase domains are predicted to be catalytically inactive (Probable).
Promotes the exchange of GDP by GTP. Activates specific Rho GTPase family members, thereby inducing various signaling mechanisms that regulate neuronal shape, growth, and plasticity, through their effects on the actin cytoskeleton. Induces lamellipodia independent of its GEF activity. Isoforms 1 and 7 are necessary for neuronal development and axonal outgrowth. Isoform 6 is required for dendritic spine formation.
Promotes the exchange of GDP by GTP. Activates specific Rho GTPase family members, thereby inducing various signaling mechanisms that regulate neuronal shape, growth, and plasticity, through their effects on the actin cytoskeleton. Induces lamellipodia independent of its GEF activity (By similarity).
Promotes the exchange of GDP by GTP. Activates specific Rho GTPase family members, thereby inducing various signaling mechanisms that regulate neuronal shape, growth, and plasticity, through their effects on the actin cytoskeleton. Induces lamellipodia independent of its GEF activity.
Structural component of striated muscles which plays a role in myofibrillogenesis. Probably involved in the assembly of myosin into sarcomeric A bands in striated muscle (By similarity). Has serine/threonine protein kinase activity and phosphorylates N-cadherin CDH2 and sodium/potassium-transporting ATPase subunit ATP1B1 (PubMed:23392350). Binds (via the PH domain) strongly to phosphatidylinositol 3,4-bisphosphate (PtdIns(3,4)P2) and phosphatidylinositol 4,5-bisphosphate (PtdIns(4,5)P2), and to a lesser extent to phosphatidylinositol 3-phosphate (PtdIns(3)P), phosphatidylinositol 4-phosphate (PtdIns(4)P), phosphatidylinositol 5-phosphate (PtdIns(5)P) and phosphatidylinositol 3,4,5-trisphosphate (PtdIns(3,4,5)P3) (By similarity).
Isoform 2 and isoform 3: bind phosphatidylinositol bisphosphates (PIP2s) via their PH domains and negatively regulate the PI3K/AKT/mTOR signaling pathway, thus contributing to the regulation of cardiomyocyte size and adhesion.
Structural component of striated muscles which plays a role in myofibrillogenesis. Probably involved in the assembly of myosin into sarcomeric A bands in striated muscle (PubMed:11448995, PubMed:16205939). Has serine/threonine protein kinase activity and phosphorylates N-cadherin CDH2 and sodium/potassium-transporting ATPase subunit ATP1B1 (By similarity). Binds (via the PH domain) strongly to phosphatidylinositol 3,4-bisphosphate (PtdIns(3,4)P2) and phosphatidylinositol 4,5-bisphosphate (PtdIns(4,5)P2), and to a lesser extent to phosphatidylinositol 3-phosphate (PtdIns(3)P), phosphatidylinositol 4-phosphate (PtdIns(4)P), phosphatidylinositol 5-phosphate (PtdIns(5)P) and phosphatidylinositol 3,4,5-trisphosphate (PtdIns(3,4,5)P3) (PubMed:28826662).
Promotes the exchange of GDP by GTP. Together with leukocyte antigen-related (LAR) protein, it could play a role in coordinating cell-matrix and cytoskeletal rearrangements necessary for cell migration and cell growth (By similarity).
Structural component of the muscle M line which is involved in assembly and organization of sarcomere myofilaments (PubMed:15313609, PubMed:16453163, PubMed:18801371, PubMed:22621901, PubMed:23283987, PubMed:27009202). The large isoform a, isoform b, isoform d and isoform f play an essential role in maintaining the organization of sarcomeres but not myofilament alignment during body wall muscle development whereas the small isoform c and isoform d appear to have a minor role (PubMed:15313609, PubMed:16453163, PubMed:22768340). Isoform b and isoform f are required for the organization of unc-15/paramyosin into sarcomere thick filaments in body wall muscles (PubMed:27009202). By binding mel-26, a substrate adapter of the cul-3 E3 ubiquitin-protein ligase complex, regulates the organization of myosin thick filaments, likely by preventing the degradation of microtubule severing protein mei-1 (PubMed:22621901). Acts as guanine nucleotide exchange factor (GEF) for Rho GTPase rho-1 but not ced-10, mig-2 and cdc-42 (PubMed:18801371). The large isoforms regulate Ca(2+) signaling during muscle contraction by ensuring the correct localization of sarco-endoplamic reticulum Ca(2+) ATPase sca-1 and ryanodine receptor unc-68 (PubMed:22768340). By controlling the contraction and/or organization of pharyngeal muscles, plays a role in the formation of pharyngeal gland cell extension (PubMed:21868609). In contrast to obscurins in other species, unlikely to have serine/threonine kinase activity as both protein kinase domains are predicted to be catalytically inactive (Probable).
Promotes the exchange of GDP by GTP. Activates specific Rho GTPase family members, thereby inducing various signaling mechanisms that regulate neuronal shape, growth, and plasticity, through their effects on the actin cytoskeleton. Induces lamellipodia independent of its GEF activity. Isoforms 1 and 7 are necessary for neuronal development and axonal outgrowth. Isoform 6 is required for dendritic spine formation.
Promotes the exchange of GDP by GTP. Activates specific Rho GTPase family members, thereby inducing various signaling mechanisms that regulate neuronal shape, growth, and plasticity, through their effects on the actin cytoskeleton. Induces lamellipodia independent of its GEF activity (By similarity).
Promotes the exchange of GDP by GTP. Activates specific Rho GTPase family members, thereby inducing various signaling mechanisms that regulate neuronal shape, growth, and plasticity, through their effects on the actin cytoskeleton. Induces lamellipodia independent of its GEF activity.
Structural component of striated muscles which plays a role in myofibrillogenesis. Probably involved in the assembly of myosin into sarcomeric A bands in striated muscle (By similarity). Has serine/threonine protein kinase activity and phosphorylates N-cadherin CDH2 and sodium/potassium-transporting ATPase subunit ATP1B1 (PubMed:23392350). Binds (via the PH domain) strongly to phosphatidylinositol 3,4-bisphosphate (PtdIns(3,4)P2) and phosphatidylinositol 4,5-bisphosphate (PtdIns(4,5)P2), and to a lesser extent to phosphatidylinositol 3-phosphate (PtdIns(3)P), phosphatidylinositol 4-phosphate (PtdIns(4)P), phosphatidylinositol 5-phosphate (PtdIns(5)P) and phosphatidylinositol 3,4,5-trisphosphate (PtdIns(3,4,5)P3) (By similarity).
Isoform 2 and isoform 3: bind phosphatidylinositol bisphosphates (PIP2s) via their PH domains and negatively regulate the PI3K/AKT/mTOR signaling pathway, thus contributing to the regulation of cardiomyocyte size and adhesion.
Structural component of striated muscles which plays a role in myofibrillogenesis. Probably involved in the assembly of myosin into sarcomeric A bands in striated muscle (PubMed:11448995, PubMed:16205939). Has serine/threonine protein kinase activity and phosphorylates N-cadherin CDH2 and sodium/potassium-transporting ATPase subunit ATP1B1 (By similarity). Binds (via the PH domain) strongly to phosphatidylinositol 3,4-bisphosphate (PtdIns(3,4)P2) and phosphatidylinositol 4,5-bisphosphate (PtdIns(4,5)P2), and to a lesser extent to phosphatidylinositol 3-phosphate (PtdIns(3)P), phosphatidylinositol 4-phosphate (PtdIns(4)P), phosphatidylinositol 5-phosphate (PtdIns(5)P) and phosphatidylinositol 3,4,5-trisphosphate (PtdIns(3,4,5)P3) (PubMed:28826662).
Promotes the exchange of GDP by GTP. Together with leukocyte antigen-related (LAR) protein, it could play a role in coordinating cell-matrix and cytoskeletal rearrangements necessary for cell migration and cell growth (By similarity).
Catalytic Activity
ATP + L-seryl-[protein] = ADP + H(+) + O-phospho-L-seryl-[protein]
ATP + L-threonyl-[protein] = ADP + H(+) + O-phospho-L-threonyl-[protein]
ATP + L-threonyl-[protein] = ADP + H(+) + O-phospho-L-threonyl-[protein]
Cofactor
Mg(2+)
Subunit
Interacts with myosin (PubMed:22467859). May interact (via protein kinase domain 1) with ball (PubMed:26251439). May interact (via protein kinase domain 1 or 2) with mask (PubMed:26251439). May interact (via protein kinase domain 2) with Tm1/tropomyosin-1 (PubMed:26251439).
May interact (via fibronectin type-III domain 1, Ig-like C2-type domain 48/49 and protein kinase domain 1 or C-terminus of the interkinase region) with lim-9 (via LIM zinc-binding domain) (PubMed:19244614). May interact (via fibronectin type-III domain 1, Ig-like C2-type domain 48/49 and kinase protein domain 1 or Ig-like C2-type domain 50, fibronectin type-III domain 2 and kinase protein domain 2) with scpl-1 isoforms a and b (via FCP1 homology domain); the interaction may act as a molecular bridge to bring two unc-89 molecules together or to stabilize a loop between the 2 kinase domains (PubMed:18337465, PubMed:19244614). May interact (via SH3 domain) with unc-15 (PubMed:27009202). May interact (via Ig-like C2-type domain 1-3) with cpna-1 (via VWFA domain) (PubMed:23283987). May interact (via Ig-like C2-type domain 2/3 and, Ig-like C2-type domain 50 and fibronectin type-III domain 2) with mel-26 (via MATH domain) (PubMed:22621901). May interact (via DH and PH domains) with rho-1, ced-10, mig-2 and cdc-42 (PubMed:18801371).
Interacts with the C-terminal of peptidylglycine alpha-amidating monooxygenase (PAM) and with the huntingtin-associated protein 1 (HAP1). Interacts with FASLG (By similarity).
Interacts with the C-terminal of peptidylglycine alpha-amidating monooxygenase (PAM) and with the huntingtin-associated protein 1 (HAP1) (By similarity). Interacts with FASLG.
Interacts (via protein kinase domain 1) with CDH2 and (via protein kinase domain 1) with ATP1B1 (PubMed:23392350). Isoform 2 is found in a complex with DSG2, DESM, GJA1, CDH2 and VCL (PubMed:28826662). Isoform 3 is found in a complex with DSG2, DESM, GJA1, CDH2, ANK3 and VCL (PubMed:28826662).
Interacts (via protein kinase domain 2) with CDH2 and (via protein kinase domain 1) with ATP1B1 (By similarity). Isoform 3 interacts with TTN/titin and calmodulin (PubMed:11448995, PubMed:11717165). Isoform 3 interacts with ANK1 isoform Mu17/ank1.5 (PubMed:12527750).
May interact (via fibronectin type-III domain 1, Ig-like C2-type domain 48/49 and protein kinase domain 1 or C-terminus of the interkinase region) with lim-9 (via LIM zinc-binding domain) (PubMed:19244614). May interact (via fibronectin type-III domain 1, Ig-like C2-type domain 48/49 and kinase protein domain 1 or Ig-like C2-type domain 50, fibronectin type-III domain 2 and kinase protein domain 2) with scpl-1 isoforms a and b (via FCP1 homology domain); the interaction may act as a molecular bridge to bring two unc-89 molecules together or to stabilize a loop between the 2 kinase domains (PubMed:18337465, PubMed:19244614). May interact (via SH3 domain) with unc-15 (PubMed:27009202). May interact (via Ig-like C2-type domain 1-3) with cpna-1 (via VWFA domain) (PubMed:23283987). May interact (via Ig-like C2-type domain 2/3 and, Ig-like C2-type domain 50 and fibronectin type-III domain 2) with mel-26 (via MATH domain) (PubMed:22621901). May interact (via DH and PH domains) with rho-1, ced-10, mig-2 and cdc-42 (PubMed:18801371).
Interacts with the C-terminal of peptidylglycine alpha-amidating monooxygenase (PAM) and with the huntingtin-associated protein 1 (HAP1). Interacts with FASLG (By similarity).
Interacts with the C-terminal of peptidylglycine alpha-amidating monooxygenase (PAM) and with the huntingtin-associated protein 1 (HAP1) (By similarity). Interacts with FASLG.
Interacts (via protein kinase domain 1) with CDH2 and (via protein kinase domain 1) with ATP1B1 (PubMed:23392350). Isoform 2 is found in a complex with DSG2, DESM, GJA1, CDH2 and VCL (PubMed:28826662). Isoform 3 is found in a complex with DSG2, DESM, GJA1, CDH2, ANK3 and VCL (PubMed:28826662).
Interacts (via protein kinase domain 2) with CDH2 and (via protein kinase domain 1) with ATP1B1 (By similarity). Isoform 3 interacts with TTN/titin and calmodulin (PubMed:11448995, PubMed:11717165). Isoform 3 interacts with ANK1 isoform Mu17/ank1.5 (PubMed:12527750).
Miscellaneous
Called DUO because the encoded protein is closely related to but shorter than TRIO.
Similarity
Belongs to the protein kinase superfamily. CAMK Ser/Thr protein kinase family.
Keywords
Alternative splicing
ATP-binding
Complete proteome
Cytoplasm
Developmental protein
Disulfide bond
Immunoglobulin domain
Kinase
Magnesium
Metal-binding
Muscle protein
Nucleotide-binding
Reference proteome
Repeat
SH3 domain
Transferase
3D-structure
Alternative initiation
Cytoskeleton
Guanine-nucleotide releasing factor
Phosphoprotein
Direct protein sequencing
Polymorphism
Calmodulin-binding
Cell membrane
Differentiation
Glycoprotein
Lipid-binding
Membrane
Nucleus
Secreted
Chromosomal rearrangement
Feature
chain Obscurin
splice variant In isoform H.
sequence variant In a colorectal cancer sample; somatic mutation.
splice variant In isoform H.
sequence variant In a colorectal cancer sample; somatic mutation.
EC Number
2.7.11.1
Pubmed
10731132
12537572
15185077
18515368
22467859
26251439
+ More
8603916 9851916 15313609 16453163 17326220 18801371 18337465 19244614 21868609 22621901 22768340 23283987 27009202 11080629 8910496 9139723 10692441 10777487 15950621 9285789 11606631 22673903 16644733 16141072 19468303 15489334 17242355 21183079 10023074 14702039 16641997 17974005 17357071 18088087 18669648 19807924 22738176 16959974 17344846 15289607 23392350 28826662 11448995 16710414 16625316 10997877 11717165 11814696 12527750 12618763 16205939 23186163 25173926 23594743
8603916 9851916 15313609 16453163 17326220 18801371 18337465 19244614 21868609 22621901 22768340 23283987 27009202 11080629 8910496 9139723 10692441 10777487 15950621 9285789 11606631 22673903 16644733 16141072 19468303 15489334 17242355 21183079 10023074 14702039 16641997 17974005 17357071 18088087 18669648 19807924 22738176 16959974 17344846 15289607 23392350 28826662 11448995 16710414 16625316 10997877 11717165 11814696 12527750 12618763 16205939 23186163 25173926 23594743
EMBL
AE013599
DQ431841
ABD83643.1
U33058
FO080458
AY724774
+ More
AY714779 U88156 U88157 AF230644 AF229255 AF232668 AF232669 AY621095 U94189 AK008844 AK081504 AK088732 AK139581 AK158544 AK159031 CT010573 AC154524 AC155257 AC165079 AC154588 BC157950 BC172101 BAB25925.1 BAC38239.1 BAC40535.1 BAE24075.1 BAE34552.1 CAM18305.1 U94190 AB011422 AK125979 AK131379 AC022336 AC069233 AC080008 AC112129 AC117401 CH471052 BC026865 BC058015 AL137629 GL456158 BC044882 BC060226 AY603754 AAT80900.1 AJ002535 AJ314896 AJ314898 AJ314900 AJ314901 AJ314903 AJ314904 AJ314905 AJ314906 AJ314907 AJ314908 AL353593 AL359510 AL670729 AM231061 AB046776 AB046859 BX957244 BX950864
AY714779 U88156 U88157 AF230644 AF229255 AF232668 AF232669 AY621095 U94189 AK008844 AK081504 AK088732 AK139581 AK158544 AK159031 CT010573 AC154524 AC155257 AC165079 AC154588 BC157950 BC172101 BAB25925.1 BAC38239.1 BAC40535.1 BAE24075.1 BAE34552.1 CAM18305.1 U94190 AB011422 AK125979 AK131379 AC022336 AC069233 AC080008 AC112129 AC117401 CH471052 BC026865 BC058015 AL137629 GL456158 BC044882 BC060226 AY603754 AAT80900.1 AJ002535 AJ314896 AJ314898 AJ314900 AJ314901 AJ314903 AJ314904 AJ314905 AJ314906 AJ314907 AJ314908 AL353593 AL359510 AL670729 AM231061 AB046776 AB046859 BX957244 BX950864
Proteomes
Pfam
Interpro
IPR013783
Ig-like_fold
+ More
IPR003599 Ig_sub
IPR013098 Ig_I-set
IPR036028 SH3-like_dom_sf
IPR000219 DH-domain
IPR011009 Kinase-like_dom_sf
IPR001452 SH3_domain
IPR000719 Prot_kinase_dom
IPR035899 DBL_dom_sf
IPR011993 PH-like_dom_sf
IPR003961 FN3_dom
IPR007110 Ig-like_dom
IPR036116 FN3_sf
IPR036179 Ig-like_dom_sf
IPR003598 Ig_sub2
IPR001849 PH_domain
IPR035526 Obscurin_SH3
IPR013106 Ig_V-set
IPR007850 RCSD
IPR001251 CRAL-TRIO_dom
IPR028569 Kalirin
IPR002017 Spectrin_repeat
IPR017441 Protein_kinase_ATP_BS
IPR008271 Ser/Thr_kinase_AS
IPR036865 CRAL-TRIO_dom_sf
IPR018159 Spectrin/alpha-actinin
IPR000048 IQ_motif_EF-hand-BS
IPR008266 Tyr_kinase_AS
IPR028570 TRIO
IPR003599 Ig_sub
IPR013098 Ig_I-set
IPR036028 SH3-like_dom_sf
IPR000219 DH-domain
IPR011009 Kinase-like_dom_sf
IPR001452 SH3_domain
IPR000719 Prot_kinase_dom
IPR035899 DBL_dom_sf
IPR011993 PH-like_dom_sf
IPR003961 FN3_dom
IPR007110 Ig-like_dom
IPR036116 FN3_sf
IPR036179 Ig-like_dom_sf
IPR003598 Ig_sub2
IPR001849 PH_domain
IPR035526 Obscurin_SH3
IPR013106 Ig_V-set
IPR007850 RCSD
IPR001251 CRAL-TRIO_dom
IPR028569 Kalirin
IPR002017 Spectrin_repeat
IPR017441 Protein_kinase_ATP_BS
IPR008271 Ser/Thr_kinase_AS
IPR036865 CRAL-TRIO_dom_sf
IPR018159 Spectrin/alpha-actinin
IPR000048 IQ_motif_EF-hand-BS
IPR008266 Tyr_kinase_AS
IPR028570 TRIO
SUPFAM
Gene 3D
Ontologies
GO
GO:0031430
GO:0035023
GO:0036309
GO:0005524
GO:0007527
GO:0016301
GO:0006468
GO:0019901
GO:0007275
GO:0046872
GO:0005089
GO:0005523
GO:0045214
GO:0045989
GO:0004672
GO:1905905
GO:0040017
GO:0019902
GO:0017048
GO:0014722
GO:1905552
GO:0031672
GO:0030241
GO:0034613
GO:0031034
GO:0010628
GO:0090736
GO:0060298
GO:0071688
GO:0050773
GO:0098696
GO:0005856
GO:1905274
GO:0098885
GO:0019899
GO:0004674
GO:0098978
GO:0016020
GO:0048471
GO:0098793
GO:0043025
GO:0035556
GO:0099645
GO:0014069
GO:0007409
GO:0005085
GO:0043005
GO:0098989
GO:0007399
GO:0043547
GO:0035176
GO:0061003
GO:0060125
GO:0007595
GO:0042711
GO:0005829
GO:0046959
GO:0007528
GO:0007613
GO:0008344
GO:0060137
GO:0005654
GO:0007186
GO:0070062
GO:0043065
GO:0015629
GO:0051056
GO:0007165
GO:0048013
GO:0016192
GO:1902936
GO:0005615
GO:0030154
GO:0010314
GO:0042383
GO:0031432
GO:0005886
GO:0014067
GO:0005516
GO:0046777
GO:0030018
GO:0032266
GO:0005863
GO:0030017
GO:0070273
GO:0016604
GO:0043325
GO:0014704
GO:0005546
GO:0045296
GO:0030506
GO:0005547
GO:0030016
GO:0008307
GO:0005737
GO:0005515
GO:0006289
GO:0004518
GO:0006281
GO:0048384
PANTHER
Topology
Subcellular location
In the embryo, localizes across the muscles in a striped pattern and is positioned laterally to the sites at which muscles are attached to the epidermis. In the larval body wall muscles, localizes to the M line and moves away from the attachment sites. During pupal development, progressively forms broad striations at the M line which become more defined after pupal eclosion. Colocalizes with myosin thick filaments at the M line. With evidence from 10 publications.
Cytoplasm
Cytoskeleton
Myofibril Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Sarcomere Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
M line Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Z line Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Cell membrane Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Sarcolemma Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Nucleus Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Secreted Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Cytoplasm
Cytoskeleton
Myofibril Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Sarcomere Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
M line Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Z line Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Cell membrane Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Sarcolemma Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Nucleus Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
Secreted Colocalizes with CDH2 and ATP1B1 to the sarcolemma and to intercalating disks in cardiac muscles. Colocalizes with ATP1B1 to M line and Z line in cardiac muscles. One or both small isoforms, one probably containing protein kinase domain 2 and partial protein kinase domain 1 and one containing only protein kinase domain 2, localize to the extracellular side of the sarcolemma. With evidence from 14 publications.
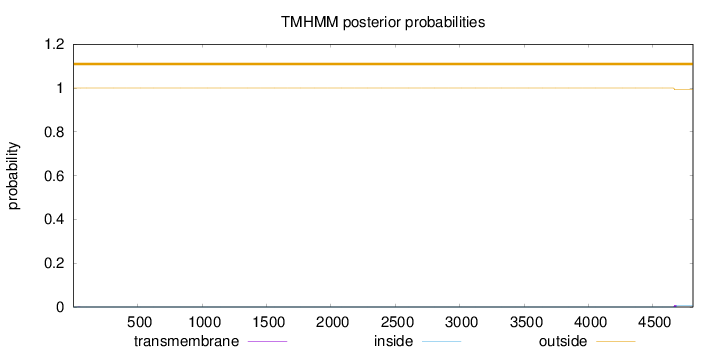
Length:
4810
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.16118
Exp number, first 60 AAs:
0.0034
Total prob of N-in:
0.00019
outside
1 - 4810
Population Genetic Test Statistics
Pi
217.418998
Theta
164.045591
Tajima's D
0.995437
CLR
0.478149
CSRT
0.658317084145793
Interpretation
Uncertain
