Gene
KWMTBOMO01975 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA014039
Annotation
PREDICTED:_collagen_alpha-1(IV)_chain_[Papilio_xuthus]
Full name
Collagen alpha-1(IV) chain
Alternative Name
Collagen type IV alpha 1
Location in the cell
Nuclear Reliability : 4.45
Sequence
CDS
ATGGTGGTCTACGTACTGTGGTTAGTAGCTGCTCTGGCACCTAAAATAATCGGAGTAAGCTCGCAAGATGATAGATATGCGGATTGGAATAACATATATTCCAGGGATTTGCCGCCGACTAACTGGCCTCGTGAAGTGGCGCCAGATACGGAGCGACCATACGCTGTAAATCAATATGGGTTGTATAATAGAAACGATATACCACCCCAATCAAGACCGGAACCAGAATTAGGGCAAAACTTCGCTGTGTATGATCCGGACACACGTCAAAGGACATCCACAGCTATTAATCGTAATTGTACAGCTCCAGGATGCTGTGTTCCTAAATGTTTCGCTGAGAAGGGTAACAGAGGATTTCCCGGCTCACCTGGACCACAAGGCCCACGTGGTCTTCCTGGCCATGAAGGTGCTGAAGGTGCGCAAGGACCTAAGGGGCAAAAAGGTCAAATAGGTCCACAGGGTCCACGTGGTCCTAAAGGTGACAAAGGCAAAACTGGAGCAAAAGGATTTGCTGGTAGAATGGGTATTCAAGGATCCCCTGGTGACCAAGGTAGACCGGGTATACCAGGAAGGGATGGTTGTAATGGAACTGATGGTGAACCTGGAATAGCTGGACCAAAAGGTTCTCAAGGACCGCGTGGTTACGCTGGATCCAAAGGAGATAAGGGAGATAAAGGTGAACCAGCTCACATTGGACGATATCCGAAAGGACAAAAAGGAGAACCTGGTGCAGATGGCATGCAAGGACAACCAGGTCTGGTTGGACCTCAAGGACCAGTTGGTTTGAAAGGACCAAAAGGCAGAGTTGGTCCTGCTGGCTTAACAGGACCTAAAGGAGATAAAGGTGCTAGAGGTGCAAAGGGCCACTCGATTCAAGGTGACAAAGGAGACAGAGGCGACAAAGGTGACCGAGGTCAAAGTTGTTCGCCAACTTCTTCCGTTGATTTCAATAATAAGGGAATTCACAAAAATATACAAGGAGATATGGGTGAAAAGGGTGACAAAGGAGAACCAGGTCGTATGGGACAAAAGGGTGATATTGGACCAATGGGGGAGCCTGGACTGTCAGGCCAGATGGGGATCAAAGGAGAAAAAGGCTTACGAGGAAATCCGGGTGAAAGGGGACGTGAAGGAATGTATGGCGCACCGGGGCCAATGGGTAATAAAGGAGAAAGAGGAAACGATGGATTATCTGGTTTAGCAGGAATACCTGGCCGAAAGGGTGAACCAGGTAGAGATGGAATTCCTGGACCTAGAGGCTTAAAAGGTGTTCCTGGTCCACCAGGGGGTCTTTCAGGTTCTCGGGGACCTCCTGGTCCCCCTGGTCCCAGAGGTTATGAGGGCCCACAAGGACCTAAAGGCACTGATGGAAGGCCGGGAGACAGAGGTCAAACAGGACCAATGGGCTCCCCAGGAAGTCAAGGTGAACCCGGAACACCAGGAATTGAGGGTCCTGCGGGACATAAAGGTGAAAAGGGAGAAGCTGGTTTTGATGGTCAAAAAGGAGAGTCTGGGCCTCGTGGATACGATGGAAATGTCGGACCCGTAGGACCTAGAGGAGAAAAAGGAGAAGATGGTCTATCCATAATTGGTCCAAAAGGAAATAGTGGCTTACCTGGTTTTTCCGGAGATAAGGGTCAAAAAGGAGAAAGAGGTTATACCGGTCTTAGAGGCGTACCAGGAAATTCCACCTTTGGTACACCTGGTATTCCAGGAGAAATAGGTCTTCCCGGAGAAAAGGGAGATAAAGGAATGCCTGGTTACGACGGTTTGCCTGGAAATACTGGACCCAAGGGTAACATAGGAGGTCGCTGCAATGAGTGCTCCCCCGGATCTTCCGGTCCAAAGGGAGACCGTGGCAACGATGGAGCAGTTGGTCCACGAGGCGAGAGGGGGCCAATAGGTCCAATTGGTTTTACTGGCGAACGAGGTGCTGATGGCATGCATGGCTTGCCTGGTGCACCTGGAGCACCTGGCGAACGGGGAGAAGATGGACCAACTGGTCCACCTGGAGATAGAGGAGCTGATGCCAACGTTCCGGTAAATTTAATTAAAGGTCCGAAGGGTGATAAAGGAAGTACAGGGCCCCGAGGTCCTCAGGGTCCTAAGGGTGAAATTGGTAGTGATGGTCCTAAAGGAGACCGAGGACAAGTTGGTATGCCAGGCCCAAAAGGAGACCGAGGCTATGAAGGACAGCCTGGTGTTGATGGTATACCTGGTGCAGATGGAATTCCTGGTATACCTGGAATAAAAGGAATATCTATAAAAGGAGACAAGGGCTTACCAGGTGATAGAGGGTTCAAAGGTGACAAAGGTAGTCCGGGTGATAGAGGTATAAAAGGCCAAGCAGGCCAATGTCCTGCTGATGTAAAAGAACTTACAAGAGGCGACAGAGGCGACAGAGGTGATACTGGCCCTCCAGGGCCTGCAGGTGAACCAGGAGAAAAGGGAGATAAAGGTTACATTGGATTGCAAGGTCAAAAAGGGGATATTGGTCCACCTGGTAGGCAGGGTCCTGTGGGAGCACGTGGGTTCCCAGGAATTCGAGGTGAAAAAGGAGAACTCGGTTCAAAAGGTTTTCCAGGAACTCCTGGTGAGAATGGGCCGCGAGGCTACCCCGGAAAACCAGGTTTTAAAGGAGATAAAGGAGAAGTCGGACCTTCCATCGTTGGTCCACCAGGCTTACCTGGTATACCAGGTCAAAAAGGTGACTCTGGTCTTCGAGGATTGCCAGGTATACCCGGTGATGATGGTCCGCCAGGTCCTCAAGGCTTACATGGAGAAAAGGGAGATCAAGGATTGGTGGGTAGACCTGGATTACCTGGTCAACCAGGTCAAAAAGGTGATGCAGGACCCGTGGGGCCCGCTGGGGTCCCAGGTATTCCTGGATTACCCGGTAAGGTTGGAGCAAAAGGACAACAAGGTTTCCCTGGAGAACCTGGTAGGCCAGGTGTTATTGGTTTGCCTGGTCAGAAAGGTGATATGGGAATCCAAGGGCCAGATGGCCAAAAAGGTTTTCCGGGTTCTCGAGGACGTCCTGGACCTCCAGGTCATCCGGGCGCACTAGGCTCACAGGGAGAAAAGGGTGATAAAGGAGAATTAGGGTATCCAGGTTCACCCGGTTCTCCAGGCCAGTCTGGACGTCCAGGTCCTGTCGGTCCTCAAGGACCTAAAGGAGATCAAGGATTTGAAGGCCCTCCAGGACTACCGGGATTACCTGGTCTATTGGGTCAAACTGGTGACAGAGGTTATACGGGCCCTAAAGGTGACAAAGGGGATGCTGGCTTAGCAGCTGAAAAGGGATCAAAAGGAGAACCTGGTCCACCTGGTCTACTTGGTATAGATGGTCTACCTGGTAGAGATGGAGAGAAAGGCGACACTGGTGAACCAGGAATACCTGGTCAAGGAATACCTGGGTATCCTGGCCAAAAAGGAGAAATGGGGATGCGTGGGTTTGATGGACTCTCGGGACCCATTGGAGAAAAAGGAAATCGTGGTCCTCAAGGAGTACCTGGTCTAAAGGGTAACTTGGGCATCTCAGGCGAGCCAGGTCGACCTGGAGTACCTGGTATCGATGGAGCACCTGGCCAGCCTGGTGATGTAGGCTTACCTGGTATTACTGGAGAAAAAGGAGATAAAGGTGAATTAGGTTTCCCCGGACGAGATGGATTAGGCGGGTTGAAAGGCGATCGTGGTCAACCTGGGGCAGAAGGTCCAATAGGACCAATAGGGTATCGAGGTCCTAAAGGAGACACGGGACTGCCAGGCGTATCCATAGATATTAAAGGTGACAAAGGAGAAGTGGGTCCAAGCGGTATTCCTGGTGAACCAGGTCAAAAGGGAGATCGAGGTCTCCCAGGATTACAAGGATTACAAGGTGAAAAAGGTGATCGTGGCTCACTAGGAGAAAAAGGAGACCAAGGTTTTACTGGGCGAATGGGAGAAAAAGGTGACACTGGTCCTATCGGTCCTACCGGCCTACCAGGCTTAACTATAAAAGGAGAAAAAGGCTTACCAGGAACTCATGGAAAACATGGGAGGCCAGGATTACCTGGTGCTCCAGGACAAAAAGGCGATCAAGGTCTACCAGGACTTCCGGGACAATTGGGTCGGCCTGGTATACCTGGGCTCCCAGGTGAAAAAGGACAAAAGGGTGATCAGGGTAATGAAGGTTTGGCAGGGCCACCAGGTCTTGTAGGTCCAACTGGACTACCTGGAACTCCTGGTATTACTGGGGAAAAAGGAGATCGAGGAGAGAAGGGGGCCACTGGGTTTGGTGCACCAGGGCAAAAAGGTGATCAAGGTCCCTCAGGTATACCAGGATTACCTGGTGAGAAAGGTGATAAAGGAGATCGTGGATTAGATGGATTACCTGGTCGAACCGGACCGATTGGTCCGCCAGGTCAGAAAGGTGATCGTGGCTATCCAGGAAGACCAGGCTTACAAGGTGAACAAGGGATGAAAGGTAATAAAGGCCAAGCGGCAGAACTCGTGTACGGCGCAAAAGGAGAACCAGGACCGCGTGGTTTGCCAGGAAATGATGGTCTACCAGGCGTAAACGGCGTTCCTGGTCGTCCAGGTAATAATGGACCCCCTGGTGAAAAGGGGGATAGAGGTTTTACTGGTGCTAGAGGTTTCCCGGGACCAAGAGGTCTCCCAGGTATACAGGGAATGGAAGGTGAAAGAGGAGAAATTGGTATGACAGGTCAAAGTGGACTTCCAGGAGCGCCTGGAGCACCATGCGTTAGTCAAGACTTCTTAACCGGAATTTTATTGGTACGACACAGTCAAAGAGAAGTCGTCCCACAATGTGAACCCAGTCACGTCAAATTATGGGATGGATATTCTTTATTGTACATAGATGGCAACGAAAAAGCCCATAATCAAGATTTAGGATATGCTGGTTCTTGTGTGAGAAAGTTCAGTACAATGCCATTCCTATTTTGTGACTTAAATGATGTCTGTAATTACGCAAGTCGTAACGACCGTAGTTATTGGTTATCCACTGGTCAACCAATACCAATGATGCCTGTTGAGGGACAAAATATTGCCAAATATATTTCAAGATGTGTGGTCTGTGAAGTACCGGCTAATGTGATTGCAGTACACAGTCAAACATTAGATATTCCGAGTTGCCCAGTTGGTTGGAATGAATTATGGATTGGTTACAGTTTTGTTATGCACACTGGTGCAGGAGGTCAAGGTGGAGGACAGGCTTTAGCAAGTCCTGGATCGTGCTTAGAAGATTTCCGTTCGATTCCATTTATAGAGTGTAATGGAGAAGGTGGAACTTGTCATCATTTTGCAAATAAACTTAGTTTCTGGCTAACTACTGTCGAAGATAGTCAACAGTTTAATGTACCGGAGCGCCAAACTCTAAAATCTGGTCAACTTCTTGAACGAGTCTCTCGATGTGCGGTTTGCATTAAGAATACGACATAG
Protein
MVVYVLWLVAALAPKIIGVSSQDDRYADWNNIYSRDLPPTNWPREVAPDTERPYAVNQYGLYNRNDIPPQSRPEPELGQNFAVYDPDTRQRTSTAINRNCTAPGCCVPKCFAEKGNRGFPGSPGPQGPRGLPGHEGAEGAQGPKGQKGQIGPQGPRGPKGDKGKTGAKGFAGRMGIQGSPGDQGRPGIPGRDGCNGTDGEPGIAGPKGSQGPRGYAGSKGDKGDKGEPAHIGRYPKGQKGEPGADGMQGQPGLVGPQGPVGLKGPKGRVGPAGLTGPKGDKGARGAKGHSIQGDKGDRGDKGDRGQSCSPTSSVDFNNKGIHKNIQGDMGEKGDKGEPGRMGQKGDIGPMGEPGLSGQMGIKGEKGLRGNPGERGREGMYGAPGPMGNKGERGNDGLSGLAGIPGRKGEPGRDGIPGPRGLKGVPGPPGGLSGSRGPPGPPGPRGYEGPQGPKGTDGRPGDRGQTGPMGSPGSQGEPGTPGIEGPAGHKGEKGEAGFDGQKGESGPRGYDGNVGPVGPRGEKGEDGLSIIGPKGNSGLPGFSGDKGQKGERGYTGLRGVPGNSTFGTPGIPGEIGLPGEKGDKGMPGYDGLPGNTGPKGNIGGRCNECSPGSSGPKGDRGNDGAVGPRGERGPIGPIGFTGERGADGMHGLPGAPGAPGERGEDGPTGPPGDRGADANVPVNLIKGPKGDKGSTGPRGPQGPKGEIGSDGPKGDRGQVGMPGPKGDRGYEGQPGVDGIPGADGIPGIPGIKGISIKGDKGLPGDRGFKGDKGSPGDRGIKGQAGQCPADVKELTRGDRGDRGDTGPPGPAGEPGEKGDKGYIGLQGQKGDIGPPGRQGPVGARGFPGIRGEKGELGSKGFPGTPGENGPRGYPGKPGFKGDKGEVGPSIVGPPGLPGIPGQKGDSGLRGLPGIPGDDGPPGPQGLHGEKGDQGLVGRPGLPGQPGQKGDAGPVGPAGVPGIPGLPGKVGAKGQQGFPGEPGRPGVIGLPGQKGDMGIQGPDGQKGFPGSRGRPGPPGHPGALGSQGEKGDKGELGYPGSPGSPGQSGRPGPVGPQGPKGDQGFEGPPGLPGLPGLLGQTGDRGYTGPKGDKGDAGLAAEKGSKGEPGPPGLLGIDGLPGRDGEKGDTGEPGIPGQGIPGYPGQKGEMGMRGFDGLSGPIGEKGNRGPQGVPGLKGNLGISGEPGRPGVPGIDGAPGQPGDVGLPGITGEKGDKGELGFPGRDGLGGLKGDRGQPGAEGPIGPIGYRGPKGDTGLPGVSIDIKGDKGEVGPSGIPGEPGQKGDRGLPGLQGLQGEKGDRGSLGEKGDQGFTGRMGEKGDTGPIGPTGLPGLTIKGEKGLPGTHGKHGRPGLPGAPGQKGDQGLPGLPGQLGRPGIPGLPGEKGQKGDQGNEGLAGPPGLVGPTGLPGTPGITGEKGDRGEKGATGFGAPGQKGDQGPSGIPGLPGEKGDKGDRGLDGLPGRTGPIGPPGQKGDRGYPGRPGLQGEQGMKGNKGQAAELVYGAKGEPGPRGLPGNDGLPGVNGVPGRPGNNGPPGEKGDRGFTGARGFPGPRGLPGIQGMEGERGEIGMTGQSGLPGAPGAPCVSQDFLTGILLVRHSQREVVPQCEPSHVKLWDGYSLLYIDGNEKAHNQDLGYAGSCVRKFSTMPFLFCDLNDVCNYASRNDRSYWLSTGQPIPMMPVEGQNIAKYISRCVVCEVPANVIAVHSQTLDIPSCPVGWNELWIGYSFVMHTGAGGQGGGQALASPGSCLEDFRSIPFIECNGEGGTCHHFANKLSFWLTTVEDSQQFNVPERQTLKSGQLLERVSRCAVCIKNTT
Summary
Subunit
Trimers of two alpha 1(IV) and one alpha 2(IV) chain. Type IV collagen forms a mesh-like network linked through intermolecular interactions between 7S domains and between NC1 domains.
Similarity
Belongs to the type IV collagen family.
Keywords
Basement membrane
Collagen
Complete proteome
Disulfide bond
Extracellular matrix
Glycoprotein
Hydroxylation
Reference proteome
Repeat
Secreted
Signal
Feature
propeptide N-terminal propeptide (7S domain)
chain Collagen alpha-1(IV) chain
chain Collagen alpha-1(IV) chain
Uniprot
H9JWX5
A0A194PLE6
A0A212ELS9
S4P9P8
A0A2H1WSQ8
A0A2A4K242
+ More
A0A2W1BLE7 A0A0L7KX52 A0A194RCY7 A0A0C9QL73 A0A1Q3FZ35 A0A1Q3FZ04 A0A1L8DIU9 A0A1L8DIT2 J9JR68 A0A2H8TTW9 A0A182F4P5 A0A182R6H3 A0A182NF64 A0A1B0D6J9 W8AM68 W4VRM6 A0A182K3K3 A0A1W4UI59 A0A2M4AFV6 A0A1Y9IW51 A0A067RJL7 W5J6W8 A0A182MSF9 A0A084WQP7 A0A2J7QCM5 A0A336M6J8 A0A0M4E8D6 B4LTV2 B4P3U6 P08120 B7FNQ3 B4JAS0 Q29L08 B4KGC9 B4I1B5 B3N4E4 A0A3B0K218 A0A232F1D9 A0A0J9TFV4 A0A1J1I6L8 A0A336KLW1 T1IZ13 A0A0K2UHU0 A0A146LFU6 W8B196 A0A182KUD3 A0A238BUG7 Q17163 A0A0C2HBK1
A0A2W1BLE7 A0A0L7KX52 A0A194RCY7 A0A0C9QL73 A0A1Q3FZ35 A0A1Q3FZ04 A0A1L8DIU9 A0A1L8DIT2 J9JR68 A0A2H8TTW9 A0A182F4P5 A0A182R6H3 A0A182NF64 A0A1B0D6J9 W8AM68 W4VRM6 A0A182K3K3 A0A1W4UI59 A0A2M4AFV6 A0A1Y9IW51 A0A067RJL7 W5J6W8 A0A182MSF9 A0A084WQP7 A0A2J7QCM5 A0A336M6J8 A0A0M4E8D6 B4LTV2 B4P3U6 P08120 B7FNQ3 B4JAS0 Q29L08 B4KGC9 B4I1B5 B3N4E4 A0A3B0K218 A0A232F1D9 A0A0J9TFV4 A0A1J1I6L8 A0A336KLW1 T1IZ13 A0A0K2UHU0 A0A146LFU6 W8B196 A0A182KUD3 A0A238BUG7 Q17163 A0A0C2HBK1
Pubmed
EMBL
BABH01041525
KQ459601
KPI93818.1
AGBW02013994
OWR42428.1
GAIX01005366
+ More
JAA87194.1 ODYU01010379 SOQ55454.1 NWSH01000276 PCG77833.1 KZ150090 PZC73686.1 JTDY01004730 KOB67822.1 KQ460398 KPJ15135.1 GBYB01001322 JAG71089.1 GFDL01002239 JAV32806.1 GFDL01002241 JAV32804.1 GFDF01007696 JAV06388.1 GFDF01007695 JAV06389.1 ABLF02028010 ABLF02028011 GFXV01004823 MBW16628.1 AJVK01003669 GAMC01019528 JAB87027.1 GANO01001294 JAB58577.1 GGFK01006350 MBW39671.1 KK852643 KDR19588.1 ADMH02001962 ETN60202.1 AXCM01007666 ATLV01025642 KE525396 KFB52541.1 NEVH01016289 PNF26332.1 UFQS01000618 UFQT01000618 SSX05466.1 SSX25825.1 CP012523 ALC38251.1 CH940649 EDW64003.2 CM000157 EDW88397.1 KRJ97759.1 J02727 M23704 M96575 AE014134 V00200 M28334 BT053743 ACK77661.1 CH916368 EDW03878.1 CH379061 EAL33016.2 CH933807 EDW11116.1 CH480820 EDW54322.1 CH954177 EDV57814.1 OUUW01000006 SPP81930.1 NNAY01001368 OXU24218.1 CM002910 KMY88215.1 KMY88216.1 KMY88217.1 CVRI01000038 CRK94057.1 SSX05469.1 SSX25828.1 JH431704 HACA01020289 CDW37650.1 GDHC01011943 GDHC01011608 JAQ06686.1 JAQ07021.1 GAMC01019529 JAB87026.1 KZ270010 OZC08330.1 U07224 AAC46611.1 KN726230 KIH69049.1
JAA87194.1 ODYU01010379 SOQ55454.1 NWSH01000276 PCG77833.1 KZ150090 PZC73686.1 JTDY01004730 KOB67822.1 KQ460398 KPJ15135.1 GBYB01001322 JAG71089.1 GFDL01002239 JAV32806.1 GFDL01002241 JAV32804.1 GFDF01007696 JAV06388.1 GFDF01007695 JAV06389.1 ABLF02028010 ABLF02028011 GFXV01004823 MBW16628.1 AJVK01003669 GAMC01019528 JAB87027.1 GANO01001294 JAB58577.1 GGFK01006350 MBW39671.1 KK852643 KDR19588.1 ADMH02001962 ETN60202.1 AXCM01007666 ATLV01025642 KE525396 KFB52541.1 NEVH01016289 PNF26332.1 UFQS01000618 UFQT01000618 SSX05466.1 SSX25825.1 CP012523 ALC38251.1 CH940649 EDW64003.2 CM000157 EDW88397.1 KRJ97759.1 J02727 M23704 M96575 AE014134 V00200 M28334 BT053743 ACK77661.1 CH916368 EDW03878.1 CH379061 EAL33016.2 CH933807 EDW11116.1 CH480820 EDW54322.1 CH954177 EDV57814.1 OUUW01000006 SPP81930.1 NNAY01001368 OXU24218.1 CM002910 KMY88215.1 KMY88216.1 KMY88217.1 CVRI01000038 CRK94057.1 SSX05469.1 SSX25828.1 JH431704 HACA01020289 CDW37650.1 GDHC01011943 GDHC01011608 JAQ06686.1 JAQ07021.1 GAMC01019529 JAB87026.1 KZ270010 OZC08330.1 U07224 AAC46611.1 KN726230 KIH69049.1
Proteomes
UP000005204
UP000053268
UP000007151
UP000218220
UP000037510
UP000053240
+ More
UP000007819 UP000069272 UP000075900 UP000075884 UP000092462 UP000075881 UP000192221 UP000075920 UP000027135 UP000000673 UP000075883 UP000030765 UP000235965 UP000092553 UP000008792 UP000002282 UP000000803 UP000001070 UP000001819 UP000009192 UP000001292 UP000008711 UP000268350 UP000215335 UP000183832 UP000075882
UP000007819 UP000069272 UP000075900 UP000075884 UP000092462 UP000075881 UP000192221 UP000075920 UP000027135 UP000000673 UP000075883 UP000030765 UP000235965 UP000092553 UP000008792 UP000002282 UP000000803 UP000001070 UP000001819 UP000009192 UP000001292 UP000008711 UP000268350 UP000215335 UP000183832 UP000075882
Interpro
IPR008160
Collagen
+ More
IPR016187 CTDL_fold
IPR001442 Collagen_IV_NC
IPR026508 TMEM164
IPR036954 Collagen_IV_NC_sf
IPR001594 Palmitoyltrfase_DHHC
IPR003134 Hs1_Cortactin
IPR004838 NHTrfase_class1_PyrdxlP-BS
IPR015422 PyrdxlP-dep_Trfase_dom1
IPR005958 TyrNic_aminoTrfase
IPR015424 PyrdxlP-dep_Trfase
IPR005957 Tyrosine_aminoTrfase
IPR004839 Aminotransferase_I/II
IPR015421 PyrdxlP-dep_Trfase_major
IPR016187 CTDL_fold
IPR001442 Collagen_IV_NC
IPR026508 TMEM164
IPR036954 Collagen_IV_NC_sf
IPR001594 Palmitoyltrfase_DHHC
IPR003134 Hs1_Cortactin
IPR004838 NHTrfase_class1_PyrdxlP-BS
IPR015422 PyrdxlP-dep_Trfase_dom1
IPR005958 TyrNic_aminoTrfase
IPR015424 PyrdxlP-dep_Trfase
IPR005957 Tyrosine_aminoTrfase
IPR004839 Aminotransferase_I/II
IPR015421 PyrdxlP-dep_Trfase_major
Gene 3D
ProteinModelPortal
H9JWX5
A0A194PLE6
A0A212ELS9
S4P9P8
A0A2H1WSQ8
A0A2A4K242
+ More
A0A2W1BLE7 A0A0L7KX52 A0A194RCY7 A0A0C9QL73 A0A1Q3FZ35 A0A1Q3FZ04 A0A1L8DIU9 A0A1L8DIT2 J9JR68 A0A2H8TTW9 A0A182F4P5 A0A182R6H3 A0A182NF64 A0A1B0D6J9 W8AM68 W4VRM6 A0A182K3K3 A0A1W4UI59 A0A2M4AFV6 A0A1Y9IW51 A0A067RJL7 W5J6W8 A0A182MSF9 A0A084WQP7 A0A2J7QCM5 A0A336M6J8 A0A0M4E8D6 B4LTV2 B4P3U6 P08120 B7FNQ3 B4JAS0 Q29L08 B4KGC9 B4I1B5 B3N4E4 A0A3B0K218 A0A232F1D9 A0A0J9TFV4 A0A1J1I6L8 A0A336KLW1 T1IZ13 A0A0K2UHU0 A0A146LFU6 W8B196 A0A182KUD3 A0A238BUG7 Q17163 A0A0C2HBK1
A0A2W1BLE7 A0A0L7KX52 A0A194RCY7 A0A0C9QL73 A0A1Q3FZ35 A0A1Q3FZ04 A0A1L8DIU9 A0A1L8DIT2 J9JR68 A0A2H8TTW9 A0A182F4P5 A0A182R6H3 A0A182NF64 A0A1B0D6J9 W8AM68 W4VRM6 A0A182K3K3 A0A1W4UI59 A0A2M4AFV6 A0A1Y9IW51 A0A067RJL7 W5J6W8 A0A182MSF9 A0A084WQP7 A0A2J7QCM5 A0A336M6J8 A0A0M4E8D6 B4LTV2 B4P3U6 P08120 B7FNQ3 B4JAS0 Q29L08 B4KGC9 B4I1B5 B3N4E4 A0A3B0K218 A0A232F1D9 A0A0J9TFV4 A0A1J1I6L8 A0A336KLW1 T1IZ13 A0A0K2UHU0 A0A146LFU6 W8B196 A0A182KUD3 A0A238BUG7 Q17163 A0A0C2HBK1
PDB
1T61
E-value=1.6246e-81,
Score=777
Ontologies
PATHWAY
GO
Topology
Subcellular location
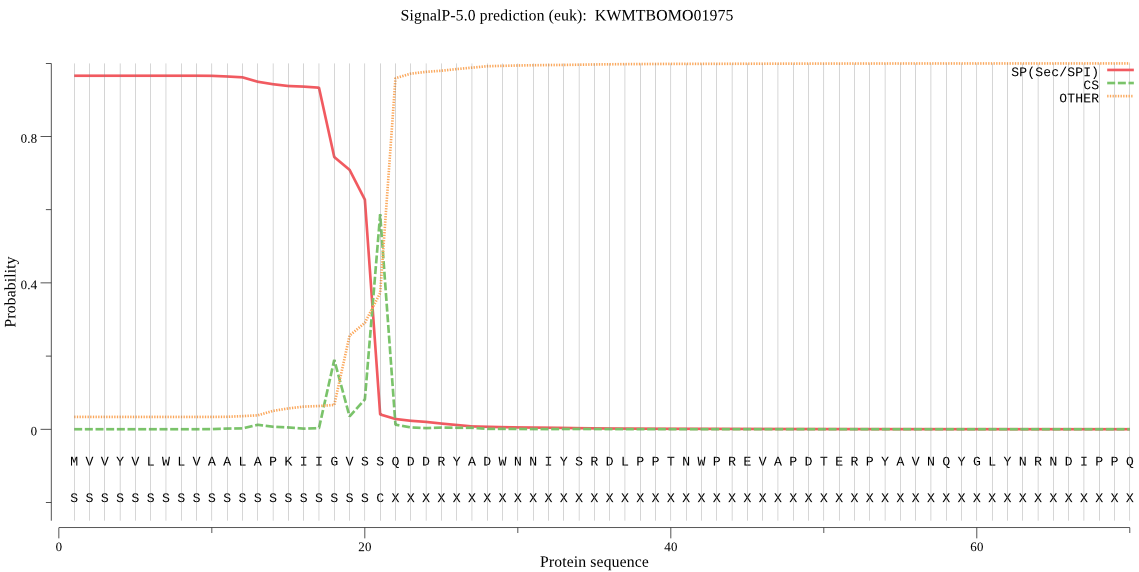
SignalP
Position: 1 - 21,
Likelihood: 0.966088
Length:
1813
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.552189999999998
Exp number, first 60 AAs:
0.55128
Total prob of N-in:
0.02914
outside
1 - 1813

Population Genetic Test Statistics
Pi
214.824443
Theta
179.234655
Tajima's D
0.837672
CLR
0.165168
CSRT
0.620768961551922
Interpretation
Uncertain
