Gene
KWMTBOMO01847
Annotation
ORF_B_(bases_1850-5560)_first_start_codon_at_2306_[Autographa_californica_nucleopolyhedrovirus]
Location in the cell
Cytoplasmic Reliability : 1.424
Sequence
CDS
ATGGCCGTAGACCCGGACCAAATCTACAAGGCCCTTCGCCCAGTGCCAGAGTTCGACGGCAATCCGAACATACTGACTAGGTTTATCAGAATTTGTGACCAAATCGTCACACAGTATATAAGAACAGATCCTGGCAACGAATTAAATAACCTCAGCCTAATAAACGGTATATTAAATAAAATAACTGGTCCTGCCGCCAGGACCATAAATTCAAATGGCATACCAGAGAACTGGTTAGGTATCCGTACTGCCCTCATTAATAATTTTTCAGACCAAAGAGATGAGACCGCTTTATACAATGACCTCTCCTTACTAACACAGGGAAACAGTAGCCCCCAGGAGTTTTACGACAAATGCCAGACCCTATTCAGCACTCTCATGACATACGTAACTTTACACGAAAGCATTGCCACAACCATCGAGGCAAAACGCGACTTGTATAAAAAGCTAACAATGCAAGCATTTGTTCGAGGCCTCAAGGAACCCTTGGGATCTCGCATACGCTGCATGAGACCGACCTCCATTGAAAAGGCTCTGGAATTTGTACAGGAAGAACTTAACATAATGTATCTACAACAGCGAAACGGGTTCACCTCTGAACGGCGCAACCTTATTCAGCCTACACCGACACCACCTGTAAAGATACCACCTATGTTTCCGGTAGCCATGCCGAAACCGCTTTCATTCGGACCGAACCCAGGACCGAGCTGGGAGCGACAGCCACCACCAGGACCTAATAACCACTGGAAACCTGCTTTCAAATTTAACGCCCCTCAGCGCATGCCTAACATGCCATCACGCACGCAGCAAATGTTCGCATCGCACCCACCAAACTACAACCCCCGTAGCAACGTATTTAGGCTACCTCAGCGGAACCAGGGACCGAAACCTATGAGTGGTATTAGTCACTACGTGGCAAAACAACTTCCACTCACAGGTCATGATTGGAGCGCAAACCAATCTTTTATAAGCCCTAAGGCGGTGGAAAAATACTATTCAAATATACCTCTTAAATATGACCCCTTCGAAGTAACGAACGTCCACGCTACAAGTAGGAACGACTTTTCCATCACTATACCAGCTTTTTCAGAACTTAACGACGCGGGACCTATTAAACTATTTGTCTACGATTTCCACAAATTTTTTGACGGACTTATTGGTTTAGACTTGCTGACTAAATGGAAATCTAGAATCGACCTTAAAGACAACCTACTGATTACAGACAATTCTACCAACCCTATTGAAATGTTCAATTCTCGCAACGTCAACCTGTACGAAGACATCGTACCGGCTAACTCTAGTAAACTAGTTAGAATTCCAATAAATTCATCTGACGGCGAAGTCTATATCCCGCAGCAATATCTGAACAACTGTGTGGTGAACGAATGCATCACGACAGTCGTTAAAAACCGTGTGGTCGGAGACATCAAAAAACGACCCGTTGTCAGTAAGCCATTTGAAACGCACACTCGCATATCCATACAAGTTTCCCAATCAAATTTAAGAGAAGACGTCATAAACGCCATTAAAGAATTCGTTAATCCTAAAGTAAAAACTGGCCTCCTTATTAATCCAACATTAAGCATGTACGACATTATACCTATAATTCAAGACACGTTCAGAAATTCGGCAATGAACCTCTTACTCACAAAGGTCGAATTAGAAAATGTGAAAGAGTACCTTCGGCAACAAGAAATAATAAGCCACTATCACGATGGAAAAACTAACCACCGCGGAATAAACGAGTGTTATTTAGCTCTTTCGCGAAAATATTACTGGCCGAAAATGAAAGATCAAATTACAAAATTCATAAACGAATGTACCATATGCGGACAAGCTAAATACGATCGCGCACCCATTAAACAGCAGTTTAGCATAGTACCACCCCCGAAGAAACCCTTCGAAATAGTTCATATGGACTTGTTCACCGCCCAATCCGAAAAATACCTGACATTTATTGACGTATTCTCTAAGTACGGACAGGCTTACCTGTTGAGAGACGGCACAGCAATTAGCGTATTACAGGGTCTATTGCAGTTCTGCACGCATCATGGTCTACCTTTAACCATAGTAACTGATAATGGTACAGAATTCACAAACCAATTGTTTTCCGAATTCATACGACTTCACAAAATAAATCATCATAAAACCCTAGCACATACACCTAATGACAATGGCAATGTAGAGAGATTCCATTCAACCTTGCTAGAACACCTTCGCATACTTCGCTTACAACATAAAAATGAACCTGTAATAAACTTAATGCCTTATGCAATATTAGCTTACAACAGTTCAGTTCACAGTTTCACCAAATGTCGCCCTTTTGACATCATAACGGGACATTTTGACCCTAGAGACCCTCTCGACATCGACATAACAGCCCATTTACTGCAGCAGTACATGGAATCACATAAAGCTCAAATGACTACAGTTTATGAACTCATAAATGAAACCTCACTTGCTAACCGTACATCTCTCATTGAAAATAGAAATAAGAACCGCGAACCAGAAGCGACGTACCAGCCTAACCAACAAGTTTTCATTAAAAACCCGATAGCAGCCCGACAAAAAACAGCCCCGAGGTACACTCAAGATAGAGTGCTAGCAGACTTACCAATTCATATCTACACATCGAAAAAACGAGGCCCTATTGCTAAATCCCGACTTAAACGTGCACATAAAGACTTCCGATTCCTCAAACCCAATCGTGTAAAAAGAGGTCTCATTGATGGCTTAGGTTCAATTGTTAAAAGCATTACAGGAAAGAAAATAGTTATTGTCTTTAAATTTCCTGTAATTTCTCCGGATGAATTCGAACTATATAAATTAACCATTGCCCCTAATAAGCATCAATTAACTTTCATCCCTCCTTATCCTTTCATCGCAACAAATAAGAAAGCGTTCATGTACATAGAGGCTGAATGCCCGAAGTACAACAGGTACTACCTCTGCGAGGAAAATATAAATCACCAGCCAAGAGATGATCCTGATTGCATCCACGATCTTATCTACAATCAAGCCATGAACACCTCATGCCAGCCAACCTCTGTTTCTTTCACTAAAGAAGCCATGGAACAACTAGACGATAAGCATTACGTCCTTATTTTCCCCGAGACCACGAAGATCGAACTTCATTGTCAACGCCTGGAGTACAGTACGCTTCAAGGAAGTTATCTCGTTACCATTCCGCAAAATTGTAAGCTGCGAACCGGACGACTAACACTGGCAAACAATAATGATCAGATCAACGGACAGCCTCTGAAAATAACTGAAATCCCGAAGGATGCAAAAATCACAGGACCCATTAGACCTCATATCAAGCTCACCTCCTTGAACCTGGAGAAAATACACCAAATCCAAGATGATATAATCCAACAACATCCTGTGGACCTAGAACAAAGTGACGTCACGAACCAAGCACTCTTTCATACGACAATACCTTTTTACGGAGCACTCTGCGGCGCGATTGTCCTAGCTGTTGTAATCGCTGTTCATCGGCACAAGTCTTGCAACATAACCCTGGAAAAGAAGCCACGCGAAGAAACCTCAAAATTTCACCCGTACGAGAGTCCAGAAGAACCCCAGAAGAAGGACCGAATTCCGGCAACATTTGCCCTCAAGATTATCAAATAG
Protein
MAVDPDQIYKALRPVPEFDGNPNILTRFIRICDQIVTQYIRTDPGNELNNLSLINGILNKITGPAARTINSNGIPENWLGIRTALINNFSDQRDETALYNDLSLLTQGNSSPQEFYDKCQTLFSTLMTYVTLHESIATTIEAKRDLYKKLTMQAFVRGLKEPLGSRIRCMRPTSIEKALEFVQEELNIMYLQQRNGFTSERRNLIQPTPTPPVKIPPMFPVAMPKPLSFGPNPGPSWERQPPPGPNNHWKPAFKFNAPQRMPNMPSRTQQMFASHPPNYNPRSNVFRLPQRNQGPKPMSGISHYVAKQLPLTGHDWSANQSFISPKAVEKYYSNIPLKYDPFEVTNVHATSRNDFSITIPAFSELNDAGPIKLFVYDFHKFFDGLIGLDLLTKWKSRIDLKDNLLITDNSTNPIEMFNSRNVNLYEDIVPANSSKLVRIPINSSDGEVYIPQQYLNNCVVNECITTVVKNRVVGDIKKRPVVSKPFETHTRISIQVSQSNLREDVINAIKEFVNPKVKTGLLINPTLSMYDIIPIIQDTFRNSAMNLLLTKVELENVKEYLRQQEIISHYHDGKTNHRGINECYLALSRKYYWPKMKDQITKFINECTICGQAKYDRAPIKQQFSIVPPPKKPFEIVHMDLFTAQSEKYLTFIDVFSKYGQAYLLRDGTAISVLQGLLQFCTHHGLPLTIVTDNGTEFTNQLFSEFIRLHKINHHKTLAHTPNDNGNVERFHSTLLEHLRILRLQHKNEPVINLMPYAILAYNSSVHSFTKCRPFDIITGHFDPRDPLDIDITAHLLQQYMESHKAQMTTVYELINETSLANRTSLIENRNKNREPEATYQPNQQVFIKNPIAARQKTAPRYTQDRVLADLPIHIYTSKKRGPIAKSRLKRAHKDFRFLKPNRVKRGLIDGLGSIVKSITGKKIVIVFKFPVISPDEFELYKLTIAPNKHQLTFIPPYPFIATNKKAFMYIEAECPKYNRYYLCEENINHQPRDDPDCIHDLIYNQAMNTSCQPTSVSFTKEAMEQLDDKHYVLIFPETTKIELHCQRLEYSTLQGSYLVTIPQNCKLRTGRLTLANNNDQINGQPLKITEIPKDAKITGPIRPHIKLTSLNLEKIHQIQDDIIQQHPVDLEQSDVTNQALFHTTIPFYGALCGAIVLAVVIAVHRHKSCNITLEKKPREETSKFHPYESPEEPQKKDRIPATFALKIIK
Summary
Uniprot
ProteinModelPortal
PDB
3S3O
E-value=9.66848e-08,
Score=139
Ontologies
GO
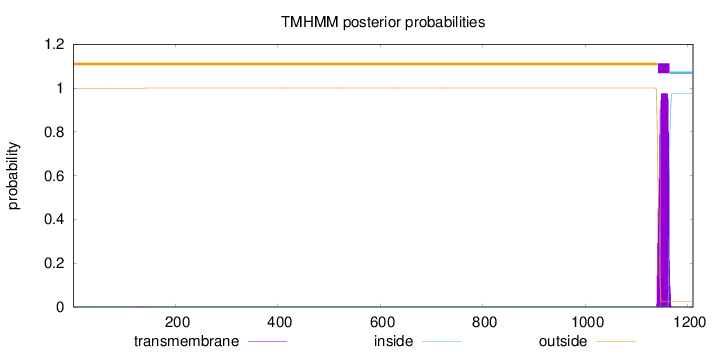
Topology
Length:
1210
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
21.04108
Exp number, first 60 AAs:
0.00073
Total prob of N-in:
0.00061
outside
1 - 1141
TMhelix
1142 - 1164
inside
1165 - 1210
Population Genetic Test Statistics
Pi
269.91412
Theta
176.847353
Tajima's D
3.30133
CLR
1.404712
CSRT
0.990100494975251
Interpretation
Uncertain
