Gene
KWMTBOMO01563
Pre Gene Modal
BGIBMGA009085
Annotation
PREDICTED:_disks_large_homolog_5_isoform_X1_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 3.468
Sequence
CDS
ATGGCATCTGGTACATCATCCTTGGAGAGTAATGGAAGTAATGAGTCAATATCACACAGTTATGTAAGCACGGAACGACACAATAACACACAGCTACCTACAATACCAATACCAATTGACTATGAGGTTATATCAAACAACCAATGCTATGACAAACAGAACTACACGGTGAAACCTCATGGTGCTCACGTTATGAGCGGCCCATATGAGTCACTGCAGTATGATGTGATAAACAAACAGACAAACGAAAGTTTGAAACAGCAATGCGAGAAGGCATTGCATGATTTGAATCAGCTAAGGAGACAGCATACGGAGACTTCCAGACGCTGTGAGCATGTAATGAAGGAATTGGAATATTTCCGAGGGCAGCACAGAGCAGCTATGAATCAACTGGAGGTCTCAGCTCAAGAGGCTAGTAGCTTACGTGGAAAATACGGAGATCTGCTCAATGATAACCAACGTTTGGAGCGTGAGGTACAACACTTACAGCAGAGCAGCACACCGGAAGGCAGCTCTGATGCATTGGTACACACACTCAGGAAATATGAAGCCTTAAAGGAAGAGTTGGATTGCTTTCAAAAAAGATATGATGATTTAATAGAGAATCATAATGCAACATTGGAGAAGCTTCGGATCCTGCAAGAAGAGAACAGCCGTCTGAAGACTCAGTGCCATGAGTTGACGCAGGAGAGGAATGCTGTGATCCGGGAGCGCAACACGCTGAAGCAGCAGGTGGCGCACGTGGTGCGGCAGTGGGAGACCGGCGAGCGCGCCGACATCAAGCGCCTCACCGACGAGCGCAACGCCGCCATGGCAGAGTACACGCTCATCATGAGCGAGAGGGATACAGTTCACAAAGAGATGGAGAAGTTATCTGATGACCTGCAAGGAGCTATGAAGAGGGTGTCCGCTTTAGAAGCTGCATTACAAGCATCCAGAGAACATCACAGGGCCACAGCGTTGCAGGCCGAGAGTCTCCGGCGCGAGGTGGAGTGCGCGCTGTCGGAGCGGGACCGCGCCCTCAAGGAGTGCTCCGCCACCAGACAAGATAACTCGGCGTACCACCACTTGGGGCTCGCAAGTGGAGTGGGCAATGACGGGTTTCTCAACGGGCAGCACTCCAACGATCCCTCCCTGGACAAATTGCAAGGCATGGTGGTGGACGCGGTGGACAAGGAGCGCGTGGAGAACCTGGAGCAGGCCAACCAGGAGCTGGAGCGCCTGCGCAAGCAGCTGGACGCCGCGCGCGCAGAGCTGGCGCACGCGCAGCGGGAGGCAGAGGTGTCGAAACGAAGGAGAGACTGGGCGTTTTCTGAACGAGACAAACTGCTGCAAGAGAGAGAGAGCGTCAAAGCGCTGTGCAACCGACTCCGCAAGGAGCGGGACCAGATGGTGGGCGAGGTGGCGGAGGCGCGGCGTCACGGCAACAAGAAGCACGAGCCGGCGCACGAGCCCGCCAGGCTGTTCGACGCCGCGGACCTACAGGATGTAGAATGGGACCTAATCGACGTGGAGCTGAGCGGACTGACTAAAGATGGGGAGCTCGGCTTCGAGTTGGCTGGCGGCAGGGACGAGCCGTACTTCCCCAACGACTGCAGCGTATACGTCACTGCTGTTAAGAAGGGCTCCAACGCTGATGGCAAGATCAGAGTGCTGGACCGCATCTCGTCGGCGTGCGGCACGGGCGCGTGGAGCAGCGCGCGCGCGTGTGCGGGCGCCCTGCTGCACGCGCTGGCGCACGCGCCCGCCCCGCTCGCCGTGCAGCGGGCGCGCGCCCTGCACCGCACGGCGCTGCTGCCCCACGCCGGCGGACTGGCGCTGCAGCACGGTATCTTCATCGGCAAGATAGCGAGCAACAGCGCCGCGGCCAAGGACGGCACGCTGTGCGTGGGCGACAGGGTTGTCAGCATAAACAACAGATCTCTGGAAGGCATGAAGAGTGTCTCCGAGGCGATGCTGCTGCTGAACGACTGTCAGTACGAGTCCGTCTCCATCACGGTGCTGCGGCCGCTGCACGCCCTCACCGACAACAGGAATAGGCTGTCCGCGTACGCCAGTTCGTTTCCGGACAACAAGCCGGTGAACATCTGCTCGCAGACCGACGACAGCTACGGCCAGTTCCACGCCGCAGCCGTCGACTCCAAGGTGTCGGGGGAGGGGGGCGCGGCGGAGCGGCGCTACGTGTACCACGTGGCGGCCGGCAGCCAGGGGAAGATCGCGCAGGAGCGAGGCACGTGGGACATGATCCGGGGCAAGATCGAAGCCGTCACCGGGAGGAGCAAGTCCAAGGATAAACAGAAGGTTCCGGAGTCTGACGCTATAGCGGAATTGGATTCAGTCATAGACAGCTATCACGGTAAAACTGTGAAAGAAACGAGTAGCGTGTTAAAACGCTCTCGACGGAAAAATAAGGAATCGCAGAACGATTCAAAAAATGGTGGCACGTGGCCTAAGGCTCGAGCTAATTTTATATTAGAAGAAAACTCGACCGGGACGATTGTGCAGCCGAGATCTAGAAAAGAAAGGCCGCCTTTATCGATACTCCTCAGTCCGCCAACGAAACTACCACCAGAACCGCAAAGATCGAATACAAATAGGAACTCGAACCCAATACCTTTGGGACACGCTCCGCTAACGCAAGCCACGACACCAGCGAGGCATTCAGTCTACAAATCGATTGAGTCCTCCCCGGCTATCGAGCACTTCCCCAAGCCCGCCCCTCTCGCCATTCACAATCCTTTCGCTTCCCCCAATAGCTTCGAGAAAATTCGTACTTTAGAAAAAGATAAGATGTCGATCAGCGACTATTCTGAACACGACATAACGCCGAATCGTTTGAGTTTAGTTCTGAACCCGTCCGACGACTCGCTGGACTACCACCCGGTGACGCGCACCAGGACCAAGAGTCCGCACTCCCTGGACTTCATGGTCAATAAGGGACCGAGCTCTCTAGACTTTGTAACGCGCAAATCGCCAAGTTCGTTAGAGCATTCTATCAAGAATCATCCGGGCAAGGATATTCTTGAGCAATATTATTCGACCAAGAAGTCGTCGTCACCGAAGACAGTGAACAAGTATCCATCGGACAGCGATAGTTTTGGGCCCGACTCGCTGAATAGCAATGCCAACTTTCCCATGACGGGGACGTTGCCTTCGCAGTCGAGACTACAGTCGCAGTATTACAGGGTACCCTTTTCAAATTCGAACCCGCACACGTCGAGTCGGTACTCGCAGCTGGCGAGCCCGACGAACATACCGCAGAGCCAATCGGGGGAGAGTATAGGAACGAGCTACGAAATGCATTCGTTCACGTCGCACACTCACAATATGTCCGACATTCAACCGGTGCCGAGAAACAGTCGCGTGGGGGACTACAACCATGGCTACGAGGGCGGCACGTTCCCTCGCAAAAAGGAGAACCAGAGGTTTCGGATACCGTCCAACCCGAGTGTCACTTCTAAAAACTCTGCCGGGAAACTGAGCACAGGTTCGATCGAGAGAAGTTCCGAAAGAAACTCTCCGATGCCGACATTTCACGTTGAAGTACTGAGCCCCGGGAGGGGGGCGAAGCAATTAGCGCATAAAGCTACAAGAAATTCGATGCCCGAATACTGTGGGCTGAGTTGGAATAAACCATTGCCGGGGGAACTCAGAAGGGTACATATCGACAAAAGTCAACAGCCACTAGGTATTCAAATATACTGCCCTCCAAGCAGCGGTGGTGTGTTCGTTTCCACTGTTAATGATAACTCCCTCGCAAGTCAAGTCGGTCTACAAGTAGGAGATCAGCTGCTCGAAGTATGCGGGATTAACATGCGTTCTGCCACCTACACCCTTGCAGCTAGAGTTCTGAGACAAATAGGTAATTCTATTACAATGCTCGTGCAATACAGCCCGGAGAAATACAAAGACGAAATGGAGGTACAGGGCAGTTCATCGTCGGGAGAGAGCTCGCACGACGAGGAAGTCTCGTTGTCGGGGTCGCCGACACCCAGGAACTCGCCCGGACCGCAGCAATCTCTGAGAATGGAGACCCCTTCGACTGAAGTATCGACGTTAAGACAGTCGCAAGCCAACAAAGAGCTGCCAAGGTTTCTCCTCATTGAGATGAGGAACTGTTCGGATTTAGGGATAAGTTTGGTGGGGGGCAACGCTGTGGGTATTTTCGTGCACAGCGTACAGATCGACTCTCCCGCGTACAACGCTGGGCTGAGGACCGGAGATCAGATCCTGGAGTACAACAACGTCGACCTCAGACACGCCACCGCCGAACAAGCCGCGCTGGAGCTGGCTAAGCCTGCTGATAAGGTGAGCGTCCTGGTCCGGCACGACCTCCAGCAGTACCACGAGATCAAGGACAAGCCGGGCGACGCGTTCTACATCCGCGCCGGCTTCGACAGGTGCGCGAAGATCACGTCCATCGGAATGGACGTCATAGACGAGTACTCGCTGTGGTTCCGGAAGGACGAGGTGCTGTTTGTGGACAACACGCTGTTCAACGGCTCCCCCGGCCTGTGGCGGGCCTGGCAGCTGGACTGTAAGAGCGCTAAGAGGCACTGGGGGACCATCCCTAGCAAATTCAAAGTGGAGGAGATCCTGCGGCGGTCGTCGGGCACGCTGGAGTCGGACACGCAGCGCCGGGCCTCCACCACGGCGCGGCGCTCCTTCTTCCGCCGCAAGAAGCACCGCGACAGCAAGGAGCTCGCTTCCTTCTCCAACACCGAGCTCGGCTGCTGGAGTGACTCCGGCACGCTGGCCGACGAGCTGCCCGTGCTCTCCTACCAGAGGGTCGAGAGGCTGCACTACGCCCGGCAGCGGCCCGTGGTGGTGCTGGGCCCGCTGTGGGAGTGCGTGGCGGCGCGGCTGGTGTCGGACTGGCCGCACGTGTTCGGCGCCGTGCGGGCCGCGTCGCTGGCGCTGGCCGGCGCCGCGCCCGCGCTCGCCAGCGGCACGCACGTGGAGCCCCGCCCCGCGCCCGACTGCGCGCACCTCGACTGCATCCCGCTGCGCGCCGTCAGGGACCTCGCCGACAAGGGCATCCACTGCATCCTAGATATAAGCGTAGCGACAATAGAGAAATTGCACAAACAGCAAATATACCCTATAGTCCTCTTCATAAAGTTCAAATCGTTCAAACAAATCAAAGAGGTGAAAGACACGAGGTATCCCTCCGAGAAAGTGTCCGCCAAAGCAGCGAAGGAAATGTACGAGCACGGCTTGAAAGTCGAGAACGAGTACAGGAGCTACATTTCAGCCGAAATACCAGCTGGCGTGAACATTGCGTACATGTGCACACAAATCAAAGAGGCTGTTGAGGAGGAGCAGAACAAGACTCTATGGGTTCCCTCGTATTACTCCGAGCCCGACGCCAAGAACTACTTCGAAATCGACTACGTGTTCCTCAAAGAGTTGCGGAAGATCGCTCGCAACAACTGCCCCAAGTGTCGCCGCAAGCGCTCCGGCAAGCATCGCCGTGACGTCACCGACAACAAGCGCAAGTCGGGAGGCATATCGTTCGTGAAGGAGAACTACGTGTTCTGTAACGGACGCTATCACAGCGAGAAGGAACATTGTCAGCTGTGTTGCAGGATCTGCAGTCGGTCCACGGACACGCTCGACTCCGCCGGCGACTCGTACTCGCTGGTGTCGCGGAGCTACAGTCAACCACCAGCCCCACGTAATCTAACACCGAAAAAGAGACGCGAAAGGAGAAACTCGATACAATCGAATAAATCGGTCTCGTTTCTAGAATCGAGTAACGACGAATCGATTAAAGACGAGACCAATTACACGGCTAAGAGCTTCACGAACGATTTGAAGAGGTTTCTGCTGAAGCCTTCCGCGCCCAGGCAGAGTCTCCGAGATAAGTTCATGTCGAGCTTCAAGCAAGAATTAGAAGCCACAAAGAAATCGCCGAAACTTAAAGCTATTAAAGGTTTGTGGAAATCTTACTGA
Protein
MASGTSSLESNGSNESISHSYVSTERHNNTQLPTIPIPIDYEVISNNQCYDKQNYTVKPHGAHVMSGPYESLQYDVINKQTNESLKQQCEKALHDLNQLRRQHTETSRRCEHVMKELEYFRGQHRAAMNQLEVSAQEASSLRGKYGDLLNDNQRLEREVQHLQQSSTPEGSSDALVHTLRKYEALKEELDCFQKRYDDLIENHNATLEKLRILQEENSRLKTQCHELTQERNAVIRERNTLKQQVAHVVRQWETGERADIKRLTDERNAAMAEYTLIMSERDTVHKEMEKLSDDLQGAMKRVSALEAALQASREHHRATALQAESLRREVECALSERDRALKECSATRQDNSAYHHLGLASGVGNDGFLNGQHSNDPSLDKLQGMVVDAVDKERVENLEQANQELERLRKQLDAARAELAHAQREAEVSKRRRDWAFSERDKLLQERESVKALCNRLRKERDQMVGEVAEARRHGNKKHEPAHEPARLFDAADLQDVEWDLIDVELSGLTKDGELGFELAGGRDEPYFPNDCSVYVTAVKKGSNADGKIRVLDRISSACGTGAWSSARACAGALLHALAHAPAPLAVQRARALHRTALLPHAGGLALQHGIFIGKIASNSAAAKDGTLCVGDRVVSINNRSLEGMKSVSEAMLLLNDCQYESVSITVLRPLHALTDNRNRLSAYASSFPDNKPVNICSQTDDSYGQFHAAAVDSKVSGEGGAAERRYVYHVAAGSQGKIAQERGTWDMIRGKIEAVTGRSKSKDKQKVPESDAIAELDSVIDSYHGKTVKETSSVLKRSRRKNKESQNDSKNGGTWPKARANFILEENSTGTIVQPRSRKERPPLSILLSPPTKLPPEPQRSNTNRNSNPIPLGHAPLTQATTPARHSVYKSIESSPAIEHFPKPAPLAIHNPFASPNSFEKIRTLEKDKMSISDYSEHDITPNRLSLVLNPSDDSLDYHPVTRTRTKSPHSLDFMVNKGPSSLDFVTRKSPSSLEHSIKNHPGKDILEQYYSTKKSSSPKTVNKYPSDSDSFGPDSLNSNANFPMTGTLPSQSRLQSQYYRVPFSNSNPHTSSRYSQLASPTNIPQSQSGESIGTSYEMHSFTSHTHNMSDIQPVPRNSRVGDYNHGYEGGTFPRKKENQRFRIPSNPSVTSKNSAGKLSTGSIERSSERNSPMPTFHVEVLSPGRGAKQLAHKATRNSMPEYCGLSWNKPLPGELRRVHIDKSQQPLGIQIYCPPSSGGVFVSTVNDNSLASQVGLQVGDQLLEVCGINMRSATYTLAARVLRQIGNSITMLVQYSPEKYKDEMEVQGSSSSGESSHDEEVSLSGSPTPRNSPGPQQSLRMETPSTEVSTLRQSQANKELPRFLLIEMRNCSDLGISLVGGNAVGIFVHSVQIDSPAYNAGLRTGDQILEYNNVDLRHATAEQAALELAKPADKVSVLVRHDLQQYHEIKDKPGDAFYIRAGFDRCAKITSIGMDVIDEYSLWFRKDEVLFVDNTLFNGSPGLWRAWQLDCKSAKRHWGTIPSKFKVEEILRRSSGTLESDTQRRASTTARRSFFRRKKHRDSKELASFSNTELGCWSDSGTLADELPVLSYQRVERLHYARQRPVVVLGPLWECVAARLVSDWPHVFGAVRAASLALAGAAPALASGTHVEPRPAPDCAHLDCIPLRAVRDLADKGIHCILDISVATIEKLHKQQIYPIVLFIKFKSFKQIKEVKDTRYPSEKVSAKAAKEMYEHGLKVENEYRSYISAEIPAGVNIAYMCTQIKEAVEEEQNKTLWVPSYYSEPDAKNYFEIDYVFLKELRKIARNNCPKCRRKRSGKHRRDVTDNKRKSGGISFVKENYVFCNGRYHSEKEHCQLCCRICSRSTDTLDSAGDSYSLVSRSYSQPPAPRNLTPKKRRERRNSIQSNKSVSFLESSNDESIKDETNYTAKSFTNDLKRFLLKPSAPRQSLRDKFMSSFKQELEATKKSPKLKAIKGLWKSY
Summary
Uniprot
A0A0N0PAU6
A0A212ER14
A0A2H1WSC9
A0A2W1BT08
A0A2A4J3E8
A0A2J7Q990
+ More
A0A2J7Q994 A0A1W4WNK6 A0A0M8ZTX3 A0A1Y1L5E5 A0A026WMM9 A0A0T6AXR6 E0VGQ1 A0A1Y1KY47 D6WWR5 U4TWU4 A0A067RLZ7 A0A1L8DMN5 A0A1B0CWU3 A0A2A3E8E1 A0A154NZW7 A0A3L8DIY5 A0A195EX46 F4WTA0 A0A158NMV2 A0A151JBE4 E2A6S3 A0A195C7L1 A0A0C9RML8 K7IXL2 A0A1S4K5L6 A0A1Q3FYW1 A0A0C9R0E5 A0A232FMD6 A0A0N8E542 A0A0P5H706 A0A0P6AJ35 A0A0N7ZYC2
A0A2J7Q994 A0A1W4WNK6 A0A0M8ZTX3 A0A1Y1L5E5 A0A026WMM9 A0A0T6AXR6 E0VGQ1 A0A1Y1KY47 D6WWR5 U4TWU4 A0A067RLZ7 A0A1L8DMN5 A0A1B0CWU3 A0A2A3E8E1 A0A154NZW7 A0A3L8DIY5 A0A195EX46 F4WTA0 A0A158NMV2 A0A151JBE4 E2A6S3 A0A195C7L1 A0A0C9RML8 K7IXL2 A0A1S4K5L6 A0A1Q3FYW1 A0A0C9R0E5 A0A232FMD6 A0A0N8E542 A0A0P5H706 A0A0P6AJ35 A0A0N7ZYC2
Pubmed
EMBL
KQ461158
KPJ08076.1
AGBW02013182
OWR43909.1
ODYU01010675
SOQ55948.1
+ More
KZ149928 PZC77481.1 NWSH01003342 PCG66511.1 NEVH01016943 PNF25156.1 PNF25157.1 KQ435878 KOX69906.1 GEZM01070716 JAV66317.1 KK107152 EZA57168.1 LJIG01022573 KRT79864.1 DS235150 EEB12557.1 GEZM01070715 JAV66319.1 KQ971361 EFA08749.2 KB631579 ERL84448.1 KK852428 KDR24048.1 GFDF01006366 JAV07718.1 AJWK01032869 AJWK01032870 KZ288347 PBC27542.1 KQ434782 KZC04634.1 QOIP01000007 RLU20113.1 KQ981940 KYN32721.1 GL888334 EGI62563.1 ADTU01020818 KQ979147 KYN22434.1 GL437197 EFN70867.1 KQ978231 KYM96138.1 GBYB01009600 JAG79367.1 AAZX01000028 AAZX01006973 GFDL01002308 JAV32737.1 GBYB01009604 JAG79371.1 NNAY01000026 OXU31832.1 GDIQ01060932 JAN33805.1 GDIQ01234281 JAK17444.1 GDIP01030194 JAM73521.1 GDIP01200561 JAJ22841.1
KZ149928 PZC77481.1 NWSH01003342 PCG66511.1 NEVH01016943 PNF25156.1 PNF25157.1 KQ435878 KOX69906.1 GEZM01070716 JAV66317.1 KK107152 EZA57168.1 LJIG01022573 KRT79864.1 DS235150 EEB12557.1 GEZM01070715 JAV66319.1 KQ971361 EFA08749.2 KB631579 ERL84448.1 KK852428 KDR24048.1 GFDF01006366 JAV07718.1 AJWK01032869 AJWK01032870 KZ288347 PBC27542.1 KQ434782 KZC04634.1 QOIP01000007 RLU20113.1 KQ981940 KYN32721.1 GL888334 EGI62563.1 ADTU01020818 KQ979147 KYN22434.1 GL437197 EFN70867.1 KQ978231 KYM96138.1 GBYB01009600 JAG79367.1 AAZX01000028 AAZX01006973 GFDL01002308 JAV32737.1 GBYB01009604 JAG79371.1 NNAY01000026 OXU31832.1 GDIQ01060932 JAN33805.1 GDIQ01234281 JAK17444.1 GDIP01030194 JAM73521.1 GDIP01200561 JAJ22841.1
Proteomes
Interpro
CDD
ProteinModelPortal
A0A0N0PAU6
A0A212ER14
A0A2H1WSC9
A0A2W1BT08
A0A2A4J3E8
A0A2J7Q990
+ More
A0A2J7Q994 A0A1W4WNK6 A0A0M8ZTX3 A0A1Y1L5E5 A0A026WMM9 A0A0T6AXR6 E0VGQ1 A0A1Y1KY47 D6WWR5 U4TWU4 A0A067RLZ7 A0A1L8DMN5 A0A1B0CWU3 A0A2A3E8E1 A0A154NZW7 A0A3L8DIY5 A0A195EX46 F4WTA0 A0A158NMV2 A0A151JBE4 E2A6S3 A0A195C7L1 A0A0C9RML8 K7IXL2 A0A1S4K5L6 A0A1Q3FYW1 A0A0C9R0E5 A0A232FMD6 A0A0N8E542 A0A0P5H706 A0A0P6AJ35 A0A0N7ZYC2
A0A2J7Q994 A0A1W4WNK6 A0A0M8ZTX3 A0A1Y1L5E5 A0A026WMM9 A0A0T6AXR6 E0VGQ1 A0A1Y1KY47 D6WWR5 U4TWU4 A0A067RLZ7 A0A1L8DMN5 A0A1B0CWU3 A0A2A3E8E1 A0A154NZW7 A0A3L8DIY5 A0A195EX46 F4WTA0 A0A158NMV2 A0A151JBE4 E2A6S3 A0A195C7L1 A0A0C9RML8 K7IXL2 A0A1S4K5L6 A0A1Q3FYW1 A0A0C9R0E5 A0A232FMD6 A0A0N8E542 A0A0P5H706 A0A0P6AJ35 A0A0N7ZYC2
PDB
3TSZ
E-value=7.4373e-30,
Score=332
Ontologies
GO
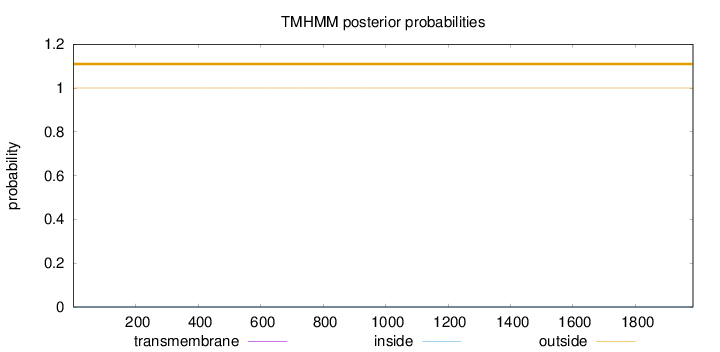
Topology
Length:
1984
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.00079
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00000
outside
1 - 1984
Population Genetic Test Statistics
Pi
252.950157
Theta
192.193682
Tajima's D
1.039774
CLR
0.008112
CSRT
0.672516374181291
Interpretation
Uncertain
