Gene
KWMTBOMO01451
Annotation
Transposon_Tf2-8_polyprotein_[Thelohanellus_kitauei]
Location in the cell
Nuclear Reliability : 4.206
Sequence
CDS
ATGGATAAATACAATCCAGATACATTCAGAATTGACGATTACATTGATTTTTTCGAAAACAAATGCAAAATTCTTGATATCGATAACAGCGACTTACAGAAAGATTTGCTTCTGAATTTACTAACACCAGAGATATTCCACGAATTAAAAGTAGCTTTAACGCCTGATTTCGATATAGCTACATACAGCGAAATTTGTAACAAATTATTAGACCTCTATCGCATAAAAACGACGAGGTATAGAGCCTTAACAGAATTTTGGAATTGCACTAGAGAACAAAATGAAACGATGGAACACTATGCAAACAGATTAAAAGGTCTTAGTCGGGATTGTGGCTACACTAATGACTTCCTGGAACGACAATTACGTGACCGCTTTGACACTGGATTGAATCATCCAGATTTAGAAACCGACTTGAAACAAAAATGGCCTGATTTAGTTCAAATGGTAGACGGAATACCACGAGAAGTAACCTTCCAACAAATTTTTACAATCTCTCAATCAAGAGAACAGGCAGAACAAGACACACCACGAACAAGTATTAAAAAAAAAAATAGGAGCAAAACCAAAACCGTACCATTACATCAAAATACAACACGAAAATTAAATCCAATGCATTGTTTACGCTGTGGAAAGAAAGAACGGCACAGCCTATCACAGTGCTCAGCCAAGGACCATATGTGTAAAGAATGTAACACGAAAGCACACTTTGAGAGTTGTTGCATTAAGTCTGGACGGGCATACATCAGCTATTCAGAAGGGAGCCGAAAATCAATTAAAAAAATAACAAGACCTCATAAGTCCTCAACATCATCATCATCATCTATCAGTAATAACAAGGAAGAAAGCGATGATGAAGTTATCTGCAGCGTCTTGGGTACACGTAAGAGAGAATGCAAACAAATAGATGTACGCATCAATGACATACCTTGCACTATGGATTGGGACCCCGGCTCTGCGTATTCAATAATAAACACGACATTATGGAAAAAATTAGGATCACCATCTTTACAACCCGCCCCGAAACTTAAGGCCTACGGTAACACAAACTTAAAAACAAAGGGAATTACAAAAGTAACAGTCGAAGTCGACGGACTGCAAAAACTTCTACCTGTGGTCGTAATGAAAAATGCCAAACCAATGTTATTTGGTTTACATTGGAGTGAAGTTTTTGAAATGGAATTTCCAAAACCAGTATACTCCATCAAAACATCAACACCGATGACTCTTAAACAAATATTGGATAAACATGTACAACTCTTTGATGGAAAACTAGGAAAAGTTAACAATTATTACGTAAACATACATGTCAAACCAGAAGCTGAACCGATCCACCTTCCTGCACGGCCTATAAAATTCAGCATGAAAAAGAATATAGAAAGGGAGTTAGATCGTCTGATCTCAGAAGGGATAGTGGAAAAAGTAGATCCTAATATTACACCTATTGAATGGGCTACACCCACAGTTAACATTCTGAAATCTACAGGGGAAATTAGGATATGTGGAGACTACAGAACTACACTTAATCCAGTACTTATTAAACATCTACACCCAGTTCCGATTTTCGATCAACTACGCCAAAATCTCGCAAACGGTAAATTATTTTCAAAAATAGACCTTAAAGACGCATACTTACAATTTGAAATAGCACCAGATTCGAAAAAGTACTTGACGTTGTCAACCCATAAAGGGTATTTCCAATACAATAGAATGCCTTTTGGAATATCGACTGCTCCTTCAATTTTTCAACATTTTCTGGATCAACTGCTAGGCGATATCACCAATGTAGCTGTATATTTTGACGACATAGCTATAGCAGGGAAAGATCTTTCAGAACATTTACAAACTTTATCTATTGCATTCGATCGCTTACAAAACGCTGGCCTAAAAGTTAATTTAAAGAAATGTAATTTCTTACAGAATCAGATTGAATACCTAGGTCACATAATAGATAAACATGGCATCCACCCAACCAAATCTAAAATTGATGCCATAACTAAGGCCCCAGCACCTAGTAATGCAAAAGAACTACGATCATTTTTAGGACTAGTTAACTTTTACGAACGGTTTGTACCACATCTTCACGGAATTTGTTCGGATCTTCATGATCTAACTAGTAAAAAAAATAGATGGCGTTGGACTGATCATGAAAACAGAATATTTGAAGATACAAAGAAATGCATAGCTTCTTCACAACCATTAATTGCATTTGACGAGAAACGTCCCCTTTATTTAGCATGTGACGCTTCCGAAAAGGGATTGGGTGCAGTATTATTCCACAAGGACTCGAACATAGAACAGCCAATTGCTTTTGCTTCAAGGAAACTACGACCAGCGGAAATGAAATATTCCATTATTGATCGTGAAGCTTTAGCAATAGTATTTGGTATAAAAAAATTTGATCAGTACTTGAGAGGAACGAAATTTAATCTAGTTACGGACCATAAGCCTCTTATACATATTATGGGTGCACGCCGCAACCTTCCTAAACTAGCCAATAACCGATTGGTAAGATGGGCCCTAGTAGTGGGAAGTTATCAATATGACATTTACTACAGGAAAGGTGAAAATAACACATTAGCTGATTGCCTTTCTAGATTACCAAACCCTGAAACTGAACCCTCCGAGACAGAAGGGCTTGTACATAAAATAGATCTACGTCTTTTGAGCACTCGATTGACTGACCTTAACCTATCAGAACAGTTACTTATGAAAACAACTGCAAAGGATCATATACTCACAAAAGTTTGTCAAAATTTAAAAACCGGCTGGAGAGAATCAGAATACAATCCAGAAATTAAACCATTCTACAGAAACCGGACTGAATTATCTGTTGAGAATAAGATACTTATGAGGCAAGGACGCATCGTTATACCTACAGCACTCCGAAAAGCCATTCTTACATACCTTCATCGAGGACACCCTGGCATTTCTGCTATGAAAGCACTTTCACGTTACTATGTTTGGTGGCCTAACCTTGACGAAGACATAGAATTATTTGTCAAGAAATGTACCAGATGCCAACAGAACCGCCCTTGTAATCCTGAACTTCCTGTATTTTCCTGGTCCATACCAGAAGAAGTATGGGAGAGAATCCATATCGACTTTGCTGGACCGTTCGAAGGATCGTATTGGTTGGTATTGTGCGACGCTCTCTCCAAATGGGTGGAAATACGACCGATGAAACACATCAACACCAGATCACTTTGTCTTACATTAGATAACATATTTTGTACATTTGGCTTACCAAAAATGATTATATCCGATAATGGACCTCAATTTACATCTTATGAATTTAAAGAATATTGCACAAAACAGTCTATTTTACATGTCACATCATCTCCATATCATCCTCGGACAAATGGGCTGGCAGAACGTTTAGTCAGAACATTCAAAAATAGAATGGCATCGGTAGACAACACAAATCTCGAGCGCCGACTATTAGAATTTCTGTTTACATACAGAAACACTCCGCACTCGTCCACTGGTAAATCTCCAGCTGAGATGATGTTTGGAAGACAATTGAATTGCATACTTTCCAACATTTGGCCAGACAAAAGAAGGTTAATGCAGTATTTACAAGTAAAAGAAAATATTCGTACCACATCACCGAGTTACCGACCAAGTGACCAAGTATATATTAAAACACGCAATGATAAAATATGGAAACCAGCGGTAATTACATCCCGAAAACATAAATATTCATATATTGTTTCAACACCAGGAGGACTAGAAAAACGAAGACACGCTGATCACATCAGGCCACGCGAGTCTTCCACCTCAGAAACCCCGAGGAATGAAAGGGCGCATTCTTCTATGCTGCCGACGACTGCTTCTCCAGACATTGGAATGGAAACATCAATTAGCGAAAGGCTAACTAACAATAAGAATTCGGCAGCAGTACCATTACCTTCACCGCAGTCGCCTACAAATGTACAAATTTCTCCAAATTCACCTTCACAGCATTCGAAGTTATACTCCTCACCTGCTCCGGTCTCCACTCCTGTGCCATTTGCTCCGCGTCGAAGTAATCGACCTAAACAGGCACCCCGCCGTCTGATCAACGAGATGTAG
Protein
MDKYNPDTFRIDDYIDFFENKCKILDIDNSDLQKDLLLNLLTPEIFHELKVALTPDFDIATYSEICNKLLDLYRIKTTRYRALTEFWNCTREQNETMEHYANRLKGLSRDCGYTNDFLERQLRDRFDTGLNHPDLETDLKQKWPDLVQMVDGIPREVTFQQIFTISQSREQAEQDTPRTSIKKKNRSKTKTVPLHQNTTRKLNPMHCLRCGKKERHSLSQCSAKDHMCKECNTKAHFESCCIKSGRAYISYSEGSRKSIKKITRPHKSSTSSSSSISNNKEESDDEVICSVLGTRKRECKQIDVRINDIPCTMDWDPGSAYSIINTTLWKKLGSPSLQPAPKLKAYGNTNLKTKGITKVTVEVDGLQKLLPVVVMKNAKPMLFGLHWSEVFEMEFPKPVYSIKTSTPMTLKQILDKHVQLFDGKLGKVNNYYVNIHVKPEAEPIHLPARPIKFSMKKNIERELDRLISEGIVEKVDPNITPIEWATPTVNILKSTGEIRICGDYRTTLNPVLIKHLHPVPIFDQLRQNLANGKLFSKIDLKDAYLQFEIAPDSKKYLTLSTHKGYFQYNRMPFGISTAPSIFQHFLDQLLGDITNVAVYFDDIAIAGKDLSEHLQTLSIAFDRLQNAGLKVNLKKCNFLQNQIEYLGHIIDKHGIHPTKSKIDAITKAPAPSNAKELRSFLGLVNFYERFVPHLHGICSDLHDLTSKKNRWRWTDHENRIFEDTKKCIASSQPLIAFDEKRPLYLACDASEKGLGAVLFHKDSNIEQPIAFASRKLRPAEMKYSIIDREALAIVFGIKKFDQYLRGTKFNLVTDHKPLIHIMGARRNLPKLANNRLVRWALVVGSYQYDIYYRKGENNTLADCLSRLPNPETEPSETEGLVHKIDLRLLSTRLTDLNLSEQLLMKTTAKDHILTKVCQNLKTGWRESEYNPEIKPFYRNRTELSVENKILMRQGRIVIPTALRKAILTYLHRGHPGISAMKALSRYYVWWPNLDEDIELFVKKCTRCQQNRPCNPELPVFSWSIPEEVWERIHIDFAGPFEGSYWLVLCDALSKWVEIRPMKHINTRSLCLTLDNIFCTFGLPKMIISDNGPQFTSYEFKEYCTKQSILHVTSSPYHPRTNGLAERLVRTFKNRMASVDNTNLERRLLEFLFTYRNTPHSSTGKSPAEMMFGRQLNCILSNIWPDKRRLMQYLQVKENIRTTSPSYRPSDQVYIKTRNDKIWKPAVITSRKHKYSYIVSTPGGLEKRRHADHIRPRESSTSETPRNERAHSSMLPTTASPDIGMETSISERLTNNKNSAAVPLPSPQSPTNVQISPNSPSQHSKLYSSPAPVSTPVPFAPRRSNRPKQAPRRLINEM
Summary
Uniprot
A0A224XI32
A0A0A9W3I3
A0A0A9W826
A0A0C2JFK2
A0A3P8Q506
A0A0C2MM68
+ More
A0A0C2JXZ5 A0A3P8NV61 A2TGR5 A0A1X7TIE8 A0A1X7VU64 A2TGR4 A0A3B3B4L9 A0A0V0RTT5 A0A0V1M0R9 A0A3P8NEQ7 A0A1A7YSF0 A0A3P8VSE7 A0A1A7WUZ7 A0A131XQT5 A0A3P8NHI5 A0A3P8QD94 A0A0C2MKX6 A0A3B3H2N7 A0A0C2NF36 A0A0C2M800 A0A1S3HLN2 A0A147BIP4 A0A2I4C6V0 A0A0V1GSV8 A0A090XCC9 A0A0V1MIE6 A0A147BQ83 A0A267F699 A0A267EVG4 A0A3P8RGT3 A0A0V0UEK4 A0A0V0T3M4 A0A0V1BVI1 A0A0V0Z754 A0A3P8NEP7 A0A0V0TT39 A0A1A8QZH2 A0A0V0ZP51 A0A0V0RYP2 A0A0V1HJS5 A0A0V1M3Q7 A0A085N6I1 A0A0V1LU74 A0A085LTS7 A0A085M8Q0 A0A147BK15 A0A147BIB8 A0A1Y1M058 A0A131Y536 A0A0V0VH28 A0A2R2MK13 A0A267EXJ4 A0A2R5LIR9 A0A1S3J391 A0A0V0USW3 A0A1S3SSU6 A0A267GR92 A0A147ADQ5 A0A1S3KHX3 A0A267FRX0 A0A1Y1MAK2 A0A147BJE4 A0A1S3L075 A0A085LJR8 A0A0V1APA6 A0A0V1GXW8 A0A1Y1LR51 A0A147BJE5 A0A0V1KNI7 A0A0V1ANZ5 A0A085LS29 A0A085LQ67 A0A085MQM1 A0A0V1ANZ8 A0A147BJS0 A0A085LME0 A0A085LXT4 A0A085NGD5 A0A1Y1NHT7 A0A085N023 A0A267F772
A0A0C2JXZ5 A0A3P8NV61 A2TGR5 A0A1X7TIE8 A0A1X7VU64 A2TGR4 A0A3B3B4L9 A0A0V0RTT5 A0A0V1M0R9 A0A3P8NEQ7 A0A1A7YSF0 A0A3P8VSE7 A0A1A7WUZ7 A0A131XQT5 A0A3P8NHI5 A0A3P8QD94 A0A0C2MKX6 A0A3B3H2N7 A0A0C2NF36 A0A0C2M800 A0A1S3HLN2 A0A147BIP4 A0A2I4C6V0 A0A0V1GSV8 A0A090XCC9 A0A0V1MIE6 A0A147BQ83 A0A267F699 A0A267EVG4 A0A3P8RGT3 A0A0V0UEK4 A0A0V0T3M4 A0A0V1BVI1 A0A0V0Z754 A0A3P8NEP7 A0A0V0TT39 A0A1A8QZH2 A0A0V0ZP51 A0A0V0RYP2 A0A0V1HJS5 A0A0V1M3Q7 A0A085N6I1 A0A0V1LU74 A0A085LTS7 A0A085M8Q0 A0A147BK15 A0A147BIB8 A0A1Y1M058 A0A131Y536 A0A0V0VH28 A0A2R2MK13 A0A267EXJ4 A0A2R5LIR9 A0A1S3J391 A0A0V0USW3 A0A1S3SSU6 A0A267GR92 A0A147ADQ5 A0A1S3KHX3 A0A267FRX0 A0A1Y1MAK2 A0A147BJE4 A0A1S3L075 A0A085LJR8 A0A0V1APA6 A0A0V1GXW8 A0A1Y1LR51 A0A147BJE5 A0A0V1KNI7 A0A0V1ANZ5 A0A085LS29 A0A085LQ67 A0A085MQM1 A0A0V1ANZ8 A0A147BJS0 A0A085LME0 A0A085LXT4 A0A085NGD5 A0A1Y1NHT7 A0A085N023 A0A267F772
Pubmed
EMBL
GFTR01008725
JAW07701.1
GBHO01042596
JAG01008.1
GBHO01042589
JAG01015.1
+ More
JWZT01002984 KII68048.1 JWZT01003820 KII65460.1 JWZT01000439 KII74358.1 EF199622 ABM90393.1 EF199621 ABM90392.1 JYDL01000080 KRX17894.1 JYDO01000377 KRZ65389.1 HADX01010638 SBP32870.1 HADW01008367 SBP09767.1 GEFM01006397 JAP69399.1 JWZT01003054 KII67871.1 JWZT01001161 KII72602.1 JWZT01005595 KII60489.1 GEGO01004800 JAR90604.1 JYDP01000327 KRZ01162.1 GBIH01000761 JAC93949.1 JYDO01000093 KRZ71620.1 GEGO01002490 JAR92914.1 NIVC01001377 PAA68677.1 NIVC01001652 PAA65446.1 JYDJ01000011 KRX49884.1 JYDJ01000764 KRX33566.1 JYDH01000010 KRY40903.1 JYDQ01000346 KRY08270.1 JYDJ01000151 KRX42156.1 HAEH01013823 SBR98409.1 JYDQ01000124 KRY14116.1 JYDL01000058 KRX19511.1 JYDP01000057 KRZ10689.1 JYDO01000236 KRZ66548.1 KL367545 KFD65077.1 JYDW01000004 KRZ62956.1 KL363295 KFD48373.1 KL363215 KFD53596.1 GEGO01004729 JAR90675.1 GEGO01004875 JAR90529.1 GEZM01043158 JAV79264.1 GEFM01002211 JAP73585.1 JYDN01000036 KRX62850.1 NIVC01001575 PAA66240.1 GGLE01005288 MBY09414.1 JYDN01000181 KRX54093.1 NIVC01000183 PAA88548.1 GCES01009650 JAR76673.1 NIVC01000860 PAA75827.1 GEZM01036245 JAV82862.1 GEGO01004533 JAR90871.1 KL363640 KFD45214.1 JYDH01000411 KRY26494.1 JYDP01000208 KRZ03007.1 GEZM01050895 JAV75318.1 GEGO01004812 JAR90592.1 JYDW01000348 KRZ48953.1 JYDH01000405 KRY26518.1 KL363314 KFD47775.1 KL363340 KFD47113.1 KL367859 KFD59517.1 JYDH01000399 KRY26536.1 GEGO01004367 JAR91037.1 KL363391 KFD46136.1 KL363264 KFD49780.1 KL367504 KFD68531.1 GEZM01002003 JAV97411.1 KL367587 KFD62819.1 NIVC01001308 PAA69606.1
JWZT01002984 KII68048.1 JWZT01003820 KII65460.1 JWZT01000439 KII74358.1 EF199622 ABM90393.1 EF199621 ABM90392.1 JYDL01000080 KRX17894.1 JYDO01000377 KRZ65389.1 HADX01010638 SBP32870.1 HADW01008367 SBP09767.1 GEFM01006397 JAP69399.1 JWZT01003054 KII67871.1 JWZT01001161 KII72602.1 JWZT01005595 KII60489.1 GEGO01004800 JAR90604.1 JYDP01000327 KRZ01162.1 GBIH01000761 JAC93949.1 JYDO01000093 KRZ71620.1 GEGO01002490 JAR92914.1 NIVC01001377 PAA68677.1 NIVC01001652 PAA65446.1 JYDJ01000011 KRX49884.1 JYDJ01000764 KRX33566.1 JYDH01000010 KRY40903.1 JYDQ01000346 KRY08270.1 JYDJ01000151 KRX42156.1 HAEH01013823 SBR98409.1 JYDQ01000124 KRY14116.1 JYDL01000058 KRX19511.1 JYDP01000057 KRZ10689.1 JYDO01000236 KRZ66548.1 KL367545 KFD65077.1 JYDW01000004 KRZ62956.1 KL363295 KFD48373.1 KL363215 KFD53596.1 GEGO01004729 JAR90675.1 GEGO01004875 JAR90529.1 GEZM01043158 JAV79264.1 GEFM01002211 JAP73585.1 JYDN01000036 KRX62850.1 NIVC01001575 PAA66240.1 GGLE01005288 MBY09414.1 JYDN01000181 KRX54093.1 NIVC01000183 PAA88548.1 GCES01009650 JAR76673.1 NIVC01000860 PAA75827.1 GEZM01036245 JAV82862.1 GEGO01004533 JAR90871.1 KL363640 KFD45214.1 JYDH01000411 KRY26494.1 JYDP01000208 KRZ03007.1 GEZM01050895 JAV75318.1 GEGO01004812 JAR90592.1 JYDW01000348 KRZ48953.1 JYDH01000405 KRY26518.1 KL363314 KFD47775.1 KL363340 KFD47113.1 KL367859 KFD59517.1 JYDH01000399 KRY26536.1 GEGO01004367 JAR91037.1 KL363391 KFD46136.1 KL363264 KFD49780.1 KL367504 KFD68531.1 GEZM01002003 JAV97411.1 KL367587 KFD62819.1 NIVC01001308 PAA69606.1
Proteomes
Pfam
Interpro
IPR041577
RT_RNaseH_2
+ More
IPR001584 Integrase_cat-core
IPR012337 RNaseH-like_sf
IPR036875 Znf_CCHC_sf
IPR001878 Znf_CCHC
IPR021109 Peptidase_aspartic_dom_sf
IPR000477 RT_dom
IPR036397 RNaseH_sf
IPR041588 Integrase_H2C2
IPR001995 Peptidase_A2_cat
IPR001969 Aspartic_peptidase_AS
IPR041373 RT_RNaseH
IPR034128 K02A2.6-like
IPR018061 Retropepsins
IPR001584 Integrase_cat-core
IPR012337 RNaseH-like_sf
IPR036875 Znf_CCHC_sf
IPR001878 Znf_CCHC
IPR021109 Peptidase_aspartic_dom_sf
IPR000477 RT_dom
IPR036397 RNaseH_sf
IPR041588 Integrase_H2C2
IPR001995 Peptidase_A2_cat
IPR001969 Aspartic_peptidase_AS
IPR041373 RT_RNaseH
IPR034128 K02A2.6-like
IPR018061 Retropepsins
Gene 3D
ProteinModelPortal
A0A224XI32
A0A0A9W3I3
A0A0A9W826
A0A0C2JFK2
A0A3P8Q506
A0A0C2MM68
+ More
A0A0C2JXZ5 A0A3P8NV61 A2TGR5 A0A1X7TIE8 A0A1X7VU64 A2TGR4 A0A3B3B4L9 A0A0V0RTT5 A0A0V1M0R9 A0A3P8NEQ7 A0A1A7YSF0 A0A3P8VSE7 A0A1A7WUZ7 A0A131XQT5 A0A3P8NHI5 A0A3P8QD94 A0A0C2MKX6 A0A3B3H2N7 A0A0C2NF36 A0A0C2M800 A0A1S3HLN2 A0A147BIP4 A0A2I4C6V0 A0A0V1GSV8 A0A090XCC9 A0A0V1MIE6 A0A147BQ83 A0A267F699 A0A267EVG4 A0A3P8RGT3 A0A0V0UEK4 A0A0V0T3M4 A0A0V1BVI1 A0A0V0Z754 A0A3P8NEP7 A0A0V0TT39 A0A1A8QZH2 A0A0V0ZP51 A0A0V0RYP2 A0A0V1HJS5 A0A0V1M3Q7 A0A085N6I1 A0A0V1LU74 A0A085LTS7 A0A085M8Q0 A0A147BK15 A0A147BIB8 A0A1Y1M058 A0A131Y536 A0A0V0VH28 A0A2R2MK13 A0A267EXJ4 A0A2R5LIR9 A0A1S3J391 A0A0V0USW3 A0A1S3SSU6 A0A267GR92 A0A147ADQ5 A0A1S3KHX3 A0A267FRX0 A0A1Y1MAK2 A0A147BJE4 A0A1S3L075 A0A085LJR8 A0A0V1APA6 A0A0V1GXW8 A0A1Y1LR51 A0A147BJE5 A0A0V1KNI7 A0A0V1ANZ5 A0A085LS29 A0A085LQ67 A0A085MQM1 A0A0V1ANZ8 A0A147BJS0 A0A085LME0 A0A085LXT4 A0A085NGD5 A0A1Y1NHT7 A0A085N023 A0A267F772
A0A0C2JXZ5 A0A3P8NV61 A2TGR5 A0A1X7TIE8 A0A1X7VU64 A2TGR4 A0A3B3B4L9 A0A0V0RTT5 A0A0V1M0R9 A0A3P8NEQ7 A0A1A7YSF0 A0A3P8VSE7 A0A1A7WUZ7 A0A131XQT5 A0A3P8NHI5 A0A3P8QD94 A0A0C2MKX6 A0A3B3H2N7 A0A0C2NF36 A0A0C2M800 A0A1S3HLN2 A0A147BIP4 A0A2I4C6V0 A0A0V1GSV8 A0A090XCC9 A0A0V1MIE6 A0A147BQ83 A0A267F699 A0A267EVG4 A0A3P8RGT3 A0A0V0UEK4 A0A0V0T3M4 A0A0V1BVI1 A0A0V0Z754 A0A3P8NEP7 A0A0V0TT39 A0A1A8QZH2 A0A0V0ZP51 A0A0V0RYP2 A0A0V1HJS5 A0A0V1M3Q7 A0A085N6I1 A0A0V1LU74 A0A085LTS7 A0A085M8Q0 A0A147BK15 A0A147BIB8 A0A1Y1M058 A0A131Y536 A0A0V0VH28 A0A2R2MK13 A0A267EXJ4 A0A2R5LIR9 A0A1S3J391 A0A0V0USW3 A0A1S3SSU6 A0A267GR92 A0A147ADQ5 A0A1S3KHX3 A0A267FRX0 A0A1Y1MAK2 A0A147BJE4 A0A1S3L075 A0A085LJR8 A0A0V1APA6 A0A0V1GXW8 A0A1Y1LR51 A0A147BJE5 A0A0V1KNI7 A0A0V1ANZ5 A0A085LS29 A0A085LQ67 A0A085MQM1 A0A0V1ANZ8 A0A147BJS0 A0A085LME0 A0A085LXT4 A0A085NGD5 A0A1Y1NHT7 A0A085N023 A0A267F772
PDB
4OL8
E-value=3.94551e-53,
Score=531
Ontologies
GO
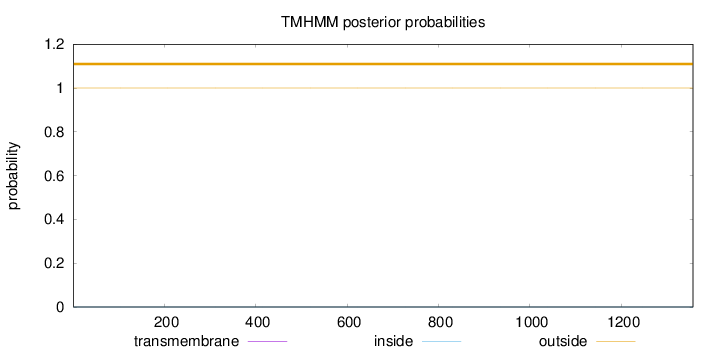
Topology
Length:
1357
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.000510000000000001
Exp number, first 60 AAs:
0.00017
Total prob of N-in:
0.00001
outside
1 - 1357
Population Genetic Test Statistics
Pi
337.479634
Theta
193.73639
Tajima's D
2.472793
CLR
187.223591
CSRT
0.939853007349633
Interpretation
Uncertain
