Pre Gene Modal
BGIBMGA007401
Annotation
Nucleolar_pre-ribosomal-associated_protein_1_[Operophtera_brumata]
Location in the cell
Nuclear Reliability : 2.988
Sequence
CDS
ATGGGTAAACGTAAATATGAAAATGATAAAAATACATCCCAACAAAATGACGACTTAACTACCGCGGAAATCGAAGTAAATAAGGGCGAAAATGAACAAACTCACAACGAAGACAAAAACACACAGATTCCATCGAAACGGAATAGAGTTGGAGGATTCGACGTTAAACATTTCAGAAAAGAACTTACCGCGAAACTAGGACATAGTACGGCTCTAACTCAGTTCTTGCAAGTCTGCTTGAACCCCGATAATGAAGTTGACTACCTACTGGAATACCTTAAGGCTGGTGGTAATTCCCACGAAATTCTGCGGCAGATCACTCAGGATAACAAAAAGAACCTCTCATTGGCCACACCAGTCTTCCATCTATTTCACCTTATCATTCTCAAAGTACAATCATCATTGCCACACATGATCTCTATCACAGAAGAAGCCTGTCGATATTTTCTTAACACCTTCATGTCAACGGTTGAGATCATGATCAGTGAGAATTCTGGTCCTCGGCATCGAAAGATAGTACTGAAGCTATTAACATCAATGGTGACTTTAAATCCAGATTTAGGAATTGAAGTATTAAATCAAGCTCCACTGACACCTAAGCATTTACAGCACATAGTTGACAAGTCTAATTATAAAGAAAAAGACAATGTTAGAACTTCATTCCTACATTTGGTGACGTCATTCCTAGTCGATGGACATTTGTTATTAACTAAGGCATTGTTAGAAAAACAAGGCCTTTTAGGTATGGTTATACCTGGCTTAGTGCATGATGAACCAGAGGCAGTGCTAATGTTCCTAAATATTCTCAAAAAGAATGTAATATACAATAGCTTTATATCTAAAAGCTTGAAACTAAAGACTTTCAGCCATCAAGTCCTCCATAATATGTTCAAAGTCTTTAGTTGGAAAGGACCTCCAGAATTAAGTAATACAGTTAAAAATGAAGTACGGAGTGAAATTATTAGTCTGCTTTCAGATCTAATACTGACTTTGTTCACTTCACATCGTTTTGGCTTGTATTTCATTGATACATCACTAGGCACAGCCGAAGCCAACAAGAATCAGAATCTGTACAAAGCATTGCTCTCATTAAAAAGACCTTGGGAGAATGAAGATGAGGGCAATGTTATTTTAGATATTGTTACCAGGTGTCCAGATTTGCACAGAGCCATTGTTAATATTATTGAACAAAGTTTCGAACCCCAGCATTCGCCACTATGGGAAAGAACTTTGAATTTCACTATTAAATTGTTAAATAGACTGAACCCCGAAGAAATGGTCCCTAGAATGAATAACCTAAACAATAGTCAGGTTGCAAATTTTGTACGTTTTGTTACTCTGCCTGTACCACTACTGAAGTTTATACAAATAAATCTAGGAAAAGACCACACTGTGTCCATATACTGTGTGAAAGTTTTAGTAAAAATGTTACAAACTTTAAAACGCTATGTACAAATCTTGGAATTAAGGAGTCCATCTCAAGTCATTGATTTGAAAAACAAGTTAGAATATTTCTTTCCGAAGCATTTGCCTGTGCCTGGGGTGATCGTAAAAATCATTGATGATGTAATAAATGATCAAAACGATATTGAAAAAACGCAAGATTATAAGCTGCCCAAGATCAGTGATGTTGATGCCTTAATATTTCTTATAGATTTACTTCTATGTTATAATGACATACATCCAACATTTTTTGAAACCATTGAGGGCACTATAGATATGAACAAGATACTAGATTATTCCACCGAACTTCATGAAGATACTGCACTACTAAAGTTCAAAGTCGTATCGCTATGGCTAACTTTAGATAATTCTGCTATTTCATTGAAAAATCCAATGTTTAAAGACTTGTTCTTAATAATGCTTGGTGTATTTATGAGCGATAGCAATACTTGGATTGAAGCAAAAGATACACTGAAAATGTTTTTAAAGAATACTGCGATATTTGAAGCAGACGAAGATGAAATTCATATATTACTTTACACTCTTCGCCATGCAAGAGTCAACCCTCCATCTTTAATTGGGGATATCATAGAATATGTTCTCGAAAAACTAACTGATCTAACAGAGTATGTTAGGAATCAACTTGTCCATTTTGAGATCTGCGATGAAAACAGTGCAGGTAGCTTAGAAAAACTGTTTAATGATTTGATGCACAACCGGAATACAGAAGACAGTGTGTTCTTAGAAAGCAAAATTCCTTCGCCATTTATAGTTGGGTGTATCCAATACATACATCTGAAGAAAGATATTAAGAAAAATTTAAAGCAATTTCTATCGCTTTATATCGCAAATCTACTTCACAGTAATTATTCACCAGAAATGACTGAGGTTTTGATTGGCGATTCTAAATTGGATGTCAGGCATTACGTTGCCAGTTGGATTGGGCAACCAGTGCCATTACCGGATTCAATCTCACAGGATAATGTATTAAAGTGCATCTCAGAATCTGTATTTGACTGCAATAATGATGTTTCTCTAAAAGATATTTTCACATTTTTTGTAGAAACAGAATGTGACGAATATGATTTTAAAATAAACAATGTGAATTATAAATTAGACATGACTGTCAATGTTGATAGCTCTGAATTATTAATTTGGTCCAAATATTTGATTTATTGCACAGTACGATTGACCAATATAGGACAATTGACCTCTGAGCAGCAACAGAAAATATCAGATTACTTTCAATGCATAATAGCTATTGGAAGAAAACACCACATGATCGATATTTGTCGAACAATAATTTTGACTCTATTCAAAAGTCCACAAGTTTTAAAAATCTATAAGCTATTAGACCTGAATAAAGGCGAAGCAAGCTTACTGGCAACGAAATTTATGTTAAAAATTATAATGGAACACAGAGATATAATAAGTTATTTGAATGAAAAAAATAAGATACTCAAGTCATACCAGCAAAAAAACTACAATGAAATTGTGAAAGCCCTTGTGAAAATTAATAAAAGAAAGAATATTGTCACTGCTCATACAATGGACGTCTTGGAAGTTGTAGGGTTAAGTAAAGGAGACGATATCCGAGTACTTAACGAAATATTTAACATTGGTGTTGAATGTTTTGTGCGCGATGACAAAGAGCCAAGTTTAGCTCTCGAACTAATTAGATATATGATTGAAAAGTACTCCAAGATAGTAGACAGTGACATCGAACCAAACATTTTGAAGAAATGCATGAACTTATACATGGAGTTATTAACGAACAAGGAATTATCACCGAATTTGAGTAATCTTGAACTGGCATTGATAGAATATTTAAGCAACAAACCGAATCAAGTCACGAATTTACCCGATGAGATATTTAAAAAGATATTTGAAATAAATAACTTTAGGAAGACAACTTCTGCTCTCGCTGTTATAATGCTAAAATATAATATTAAATTCTGTAAGATATTCAAAGAAGAAATTGTTAAACCAGATGTTTTGGCTCAAAGAGAACTTACTTTGCCTTTAGGAACTGGACTTTTAGAACATAAGCTATTTTTAAATGAAAACAAAGATCTCTTGAAGACAATATACGAGGAATACAAATCTAACATAGTTAAGTTTTTGGAAAAGCCCCACAAGGCTGGACAAATATATGTGACGAATTGGATGTTCATAAGAAAACTGATTTTAGAGTGTATGCAAAAGGAAGAATGCGAAAATTTATTTAACAAAATCCACAAATTCGAAATATTAGAGATCAGTCACAATCATTTATTTCAGACGGTATTTTTAAAACTATGCATTTCTGAAGGAACAAAAAAGAAGTCTATATTGATTAATTATTTCCTTTCAATGTTAAATTTAACAATAATTTCTTTGAAGGAAGCGAAAGACGAAGCAGGACTAAACCAATTAGTAAATAATATAAATACGATTTGTGAAATAAGCAGACACATCGATGATTTTGAGGTTGAAAATAAAGAAGAATTCAAAAAGATTACAGAAACAACAACCTGGCAGAACTTCTGTAAGAATGTCTTGAAAGATTCCCTCAAAATTAGAACGGCCACTGAGAGTAACGCTATAGGCGCCAAATTAATACTATTATTGACGAACTTGGTCAAACTCTTTTATCCAATAGACCATGAAGACATAACAACACTATTCGACATGGTCACATCACATTCCGAGTTCTTGAATGTGATGCTCAGTCATTACAGCACGGCGATAAAATCAAGATTGATATATTTCTTGTACGTTTTGATAACAAAAAAGAAATCGGTGATGAAAATACAACAGATACCGGTGTATTTGAGTGCATACCACGCGACAAGGTCTCCGTGTGATAGGCTGATTCTTAGTATACTGAATTATTTCGAGAGCAACGGTCTACCTGTGAATGAATACAAACCTTACGTTTGGGGGGAATCGGCTGCCAACTATTACGCCGTGAGGAAAAACAGATCTGCTTCCCTGTGGGCGCATCCGACACCAAATCAAGTATTGAATTTGTTCGAGAAAGAAATTATTGAGAGGACAATTAAAAAATTTCCTGTCACACAAAAAATGGATTATCATTACGAGTTGCCCTCGAATCTGGATGTAGACGATGCGAATAGTTCTGTCAGAAATATTATTGACGATTTCTTCAAGAAGACAGTTCTGGAATCTGTCCAGATTAAAGATACAGAAGGAGCAGTAAATTCTTTGTTGATCAAAGGTAAATTTGAGAAGCTGGTCGAAACGATGAAGAGAAGAGACGTAGTTGCAACCTCCCATCAGGACGACGATGAGTCTATATACGACCCTCTGTTCGTATTTCCTCTCCTGAGTCACCTCTTGGCTCCGGGTTCGGTGGCGTCTTGTTTCAAGATGTTAAGGACCGGTTTGTTGTCAGTCCCCGTAGTGGCACTGAGCTCTCTCTGTCCGCTGACGAGGGCGGCTGCCTACCACGTGCTCCATCGGTTCTACCTGCTCTTGGAGACTGAGACGAGACACAGGAACGACAAACTGTTTCTCAACGATTTCATCAACACCCTCCGGAAGAGCCTCGCCACAGCCATCACCAGTTCCGACGAAGACTCTGATGAGCTAAACGGCGTGAAGAACCCGAGAGTGCCGGCGGTGGACGCCCTTTATCTGGCCAGAGGACTGATGGTCTCCACGGCGCCTCTCGACCCGCTCTACAAACCGATAAACAACTTCCTGATCGCGAAACAGCTTGTAGATTTTACTGTGGTACCGGACTTTTTAAGTCTCTTCCACGACAGCGACGTCGAGTCCGTAGAAAGGAGAGTCTGGATCTTAGACACCATCATGCACGGCGTCAAGACAATGACCGATGTCAATGTCATATTCAAAACGATGTGCCTGAAGATGATCATGGATTTCTACACGTCCGTGTTAAGTGAGAAAAAAGTGAAAGTGAAAATTATAAATGTTCTAAGTTCGATAGTGAGTGTCCCTAAATCGTTTGAGATATTAGTCGAAGGACACGGCCTAATATCCTGGCTGCATTCGGTTGTGAAGACCGTGAATAAGGAAGATGGTGTATTAGTGACGGCAATATTTGTTTTGATTAAAAACATGTTGTACAGTCTGAGTGTTAATGGCTTGGTGAAAAGTCAAGCGATGCGGAATAAAAATGTAAAAATATACGAAGTTGCGGGTATTAAGGGAAACAGGGAGCTAGAATTTGAAATACTGATCCTAGTGCAAGATTTACTGAAAAAAAACGATGCCCTTGAAAGGCAAGACGTAGCCGAATATTTGAGTTTGTACAGAATGTTCTCGAGGATAACTATAAAGTTCGTTAATAAGAAACATGTTATTAATCTTGTCAATAAAATGATGGAGATCTTGAAGGATAGTGAGAGTGTTAAATTGTTGTCTAAAGCGTTGTTGTCGAACGATGGTTCCGTGTTGAGAAGCAAAGTGTTCAATGATGCTGACGATAGTTTGATAAACGATTTGTATTACGTTGTACAATGTTTTGTTTGTTGA
Protein
MGKRKYENDKNTSQQNDDLTTAEIEVNKGENEQTHNEDKNTQIPSKRNRVGGFDVKHFRKELTAKLGHSTALTQFLQVCLNPDNEVDYLLEYLKAGGNSHEILRQITQDNKKNLSLATPVFHLFHLIILKVQSSLPHMISITEEACRYFLNTFMSTVEIMISENSGPRHRKIVLKLLTSMVTLNPDLGIEVLNQAPLTPKHLQHIVDKSNYKEKDNVRTSFLHLVTSFLVDGHLLLTKALLEKQGLLGMVIPGLVHDEPEAVLMFLNILKKNVIYNSFISKSLKLKTFSHQVLHNMFKVFSWKGPPELSNTVKNEVRSEIISLLSDLILTLFTSHRFGLYFIDTSLGTAEANKNQNLYKALLSLKRPWENEDEGNVILDIVTRCPDLHRAIVNIIEQSFEPQHSPLWERTLNFTIKLLNRLNPEEMVPRMNNLNNSQVANFVRFVTLPVPLLKFIQINLGKDHTVSIYCVKVLVKMLQTLKRYVQILELRSPSQVIDLKNKLEYFFPKHLPVPGVIVKIIDDVINDQNDIEKTQDYKLPKISDVDALIFLIDLLLCYNDIHPTFFETIEGTIDMNKILDYSTELHEDTALLKFKVVSLWLTLDNSAISLKNPMFKDLFLIMLGVFMSDSNTWIEAKDTLKMFLKNTAIFEADEDEIHILLYTLRHARVNPPSLIGDIIEYVLEKLTDLTEYVRNQLVHFEICDENSAGSLEKLFNDLMHNRNTEDSVFLESKIPSPFIVGCIQYIHLKKDIKKNLKQFLSLYIANLLHSNYSPEMTEVLIGDSKLDVRHYVASWIGQPVPLPDSISQDNVLKCISESVFDCNNDVSLKDIFTFFVETECDEYDFKINNVNYKLDMTVNVDSSELLIWSKYLIYCTVRLTNIGQLTSEQQQKISDYFQCIIAIGRKHHMIDICRTIILTLFKSPQVLKIYKLLDLNKGEASLLATKFMLKIIMEHRDIISYLNEKNKILKSYQQKNYNEIVKALVKINKRKNIVTAHTMDVLEVVGLSKGDDIRVLNEIFNIGVECFVRDDKEPSLALELIRYMIEKYSKIVDSDIEPNILKKCMNLYMELLTNKELSPNLSNLELALIEYLSNKPNQVTNLPDEIFKKIFEINNFRKTTSALAVIMLKYNIKFCKIFKEEIVKPDVLAQRELTLPLGTGLLEHKLFLNENKDLLKTIYEEYKSNIVKFLEKPHKAGQIYVTNWMFIRKLILECMQKEECENLFNKIHKFEILEISHNHLFQTVFLKLCISEGTKKKSILINYFLSMLNLTIISLKEAKDEAGLNQLVNNINTICEISRHIDDFEVENKEEFKKITETTTWQNFCKNVLKDSLKIRTATESNAIGAKLILLLTNLVKLFYPIDHEDITTLFDMVTSHSEFLNVMLSHYSTAIKSRLIYFLYVLITKKKSVMKIQQIPVYLSAYHATRSPCDRLILSILNYFESNGLPVNEYKPYVWGESAANYYAVRKNRSASLWAHPTPNQVLNLFEKEIIERTIKKFPVTQKMDYHYELPSNLDVDDANSSVRNIIDDFFKKTVLESVQIKDTEGAVNSLLIKGKFEKLVETMKRRDVVATSHQDDDESIYDPLFVFPLLSHLLAPGSVASCFKMLRTGLLSVPVVALSSLCPLTRAAAYHVLHRFYLLLETETRHRNDKLFLNDFINTLRKSLATAITSSDEDSDELNGVKNPRVPAVDALYLARGLMVSTAPLDPLYKPINNFLIAKQLVDFTVVPDFLSLFHDSDVESVERRVWILDTIMHGVKTMTDVNVIFKTMCLKMIMDFYTSVLSEKKVKVKIINVLSSIVSVPKSFEILVEGHGLISWLHSVVKTVNKEDGVLVTAIFVLIKNMLYSLSVNGLVKSQAMRNKNVKIYEVAGIKGNRELEFEILILVQDLLKKNDALERQDVAEYLSLYRMFSRITIKFVNKKHVINLVNKMMEILKDSESVKLLSKALLSNDGSVLRSKVFNDADDSLINDLYYVVQCFVC
Summary
Uniprot
Pubmed
EMBL
KZ150083
PZC73820.1
NWSH01007571
PCG62903.1
ODYU01008983
SOQ53040.1
+ More
JTDY01001350 KOB74104.1 KQ459232 KPJ02479.1 KQ460685 KPJ12830.1 KZ288285 PBC29457.1 KK853099 KDR11374.1 JRES01000195 KNC33413.1 DS231930 EDS27248.1 CCAG010021607 APGK01039879 KB740975 ENN76448.1 ATLV01023967 KE525347 KFB50221.1 KQ971338 KYB28164.1 AJWK01030593
JTDY01001350 KOB74104.1 KQ459232 KPJ02479.1 KQ460685 KPJ12830.1 KZ288285 PBC29457.1 KK853099 KDR11374.1 JRES01000195 KNC33413.1 DS231930 EDS27248.1 CCAG010021607 APGK01039879 KB740975 ENN76448.1 ATLV01023967 KE525347 KFB50221.1 KQ971338 KYB28164.1 AJWK01030593
Proteomes
SUPFAM
SSF48371
SSF48371
ProteinModelPortal
Ontologies
GO
PANTHER
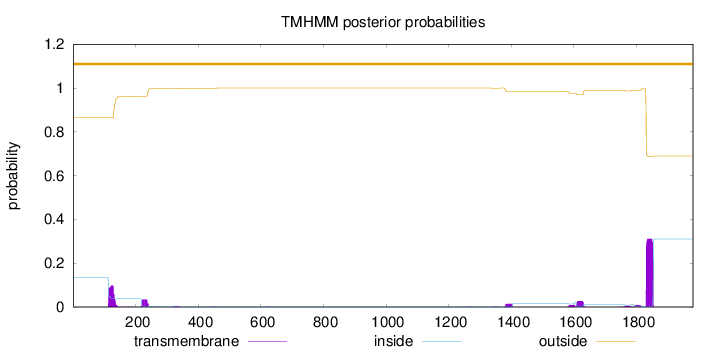
Topology
Length:
1981
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
11.18181
Exp number, first 60 AAs:
0
Total prob of N-in:
0.13615
outside
1 - 1981
Population Genetic Test Statistics
Pi
248.025143
Theta
224.583621
Tajima's D
0.67563
CLR
0.062681
CSRT
0.565571721413929
Interpretation
Uncertain
