Gene
KWMTBOMO00989 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA001372
Annotation
PREDICTED:_talin-1_[Bombyx_mori]
Location in the cell
Nuclear Reliability : 2.345
Sequence
CDS
ATGGCCAGTGCCGTGAAGCGTGCAGACCAGGATCAGTTCCCGCGCTCCGTGGGCTCCGTGGCCAGTGCTGTCCATGGACTCGTCGAGGCAGCCGCGCAAGCCGCCTATCTTGTGGCCGTGTCTGAAGAGTCCAGCGTGGCCGGCCGCGCGGGGCTGGTGGACCAGGCCCAGTTCGGGCGCGCCGCCCTCGCCATCCAGCAGGCCTGCAACCTGCTGGCCGACCCCGCCTCCAACCAGCAACAGGTCCTGTCGGCGGCGACGGTGATAGCCAAGCACACCAGCGCCCTCTGCAACGCGTGCCGGGTGGCCTCAGGCAAGACCACAGAGCCGCAAGCCAAGAGGCACTTCGTTCAGGCCGCCAAGGACGTCGCCAACTCCACCGCGGCCCTCGTCAAGGAGATCAAGGCGCTGGACACGGACTACAGCGAGGCCAACCGGGCTCGGTGTGCCAGCGCCACTGGGCCGCTGCTGGAGGCGGTGCAGTCGCTGTGCCAGTTCGCGGACAGCCCGGAGTTCGCTTCGATCCCGGCCAGGATATCCGAGCAGGGACGCAGGAGCCAGGAGGACATATTGGAGTGCGGCAGGAACATCATATCGGAGTCGTGCTCGATGCTGGAGGCGGCGGGGCAGCTGGTGCTGTCGCCGGAGGACCGGCCGCAGTGGCACGCGCTGGCCGCCCACAGCAAGACGCTCTCCGACACCATCAAGGCGCTGGTCGCCAACATACGGGAGAAGGCCCCCGGGCAGCGCGAGTGCGCGGCGGCCCTGGACACCCTCAACAAGCAGCTGCGGGAGCTGGACCACGCCGCCATCCAGGCCGTCGCCCAGGAGTTGGAGCCCCGGAAGGCCAACACGCTGCAAGGTTACGCGGAGCAGATCGAGAACTGCTGCACGGAGATGCTGGAGCGTCTGGAGCCGCTGCGCGTCGCCGCCCGGGCCGAGGCCGAGAACCTGGGCCACTGCGTCAGGCAATACGTGTCGTACTCGGAGCCGCTGGTGTCGGGCGCGGTGGGCGCGGCGTCCGGCGTGTCGGAGACAACGGAGCAGGCGGCGCTGCTGCAGCACGCGCGCACCGTGCTGGAGACCGCCGTGCTGCTGCTGCAGGCCGCCAGGGACGCCGCCGGGAACCCCAGGGCGGCGGCGGCGCACGGCGCGGTGGACGCGCAGGTGGTGCAGGCGCGCGAGTCGCTGCAGGAGCTGGCGGAGCGGGTGAGGCGGCTCAGCGCGCAGCACGGCGCCGTGGGCCCGCTGCTCGACACGCTGGCCCGCGCGCTCACCAGGCTCACGGAGCGCAGAATGTCTCTGCTCAGCTCTTACGATGAATCAGATTCGTTTGTCGACTACCAGACAAGGATGGTCGGAGTCGCGAAGGAGATAGCGAGACTGGCCACTGACATGACGGCCAAGGCGGCGACGGAGCCCGGGCGGCTGGTGGAGCTCGGCAACGAGATGTGCGGCAAGTACGAGCAGCTCGCGCAGGACAGCGTCGGCGCCTCCGCCACCACGCCCAGCGGGGACGTCGCCAACAGGATCCGATCAGCGGTGGTGGAGCTGGGCGAGAGCATATCAGAGCTGATCAAGGCGGGGGGACACTGCCGCCTGTCCGCCATCGCGCAGAACCAGCGCGCCGTCGCCGACAGCGCCAAGCTCGTCAACGAAAGGGTGGTGTCGGTGCTGAGCGGGCTGCAGGCGGGCTCCCGCGGCACGCAGGCCTGCATCCACGCCGCCGCCACCATCAGCGCCATCATCGGAGACCTGGACACCACCATACTGTTCGCCAGCGCCGGAACTCTTCAATCTGACAAGGAGTCGGACACGTTCTCCGACCACCGCGAGAACATCCTGAAGACGGCCAAGGCGCTGGTGGAGGACACCAAGACCCTCGTGGGCGGAGCGGCCGGCACCCAGGAGCAGCTGGCCGACGCCGCGCAGAACGCCGTCACCACTATAGTGCAACTGTGCGAGGTGGTGAAGCTGGGTGCCATGTCGCTAGGCTCGGGCAGCCCGGAGCCGCAGGTGCTGGTGCTGCACGCCGCGCGGGACGTGGCCGCGGCGCTGCGGGACCTGGCCGCCGCCACCACCGCCGCCAGCGGCAAGCCCGGCCTCGGCGCCGACATGCAGCGCCTCAAGCACGCCGCCAAGCGGCCGCCAGCCCCGCGGCGGCGCTGCAGCGCGCCCGGCAATAGCAACACGTTCCCGGGACAAAAGCGCAGATCACTTAACGGGAGAAACGACTACAACTCTTGCGATTCCGAAACCGATTTGTTCCAATCCGACCAGGAGGAGGAGCTGGTCAAGCTCCTGGACTACTCCAGCCAGGACGACGACGTGTCCCCGACCATATTCCACGACGACTGTGAGGAGATCGTCGCCTACATAGAGAGCCGCATGCGCCGCCCCACCAGGACCCCAGAGGACGAGGGCCTCAACGAGCGGTACAACGCGGCCGCCAGGTACAGCATCGTCGACATGGACTGGCGCGTGCTCAAGTACGGAGAGAACATCCTGCTGGGGGAGGTCAAGAAGCTGCTCGACCTGTGTCTCCAGCTCAGCGATCGAAATGACAGCAGACGCAAGGATGAGAGTTTGCAGCGCCTGCGGGCCAGCACCCAGCTGGACACGGAGATGCACACGCTCTCGCGGGTCATTGAGCACCTCGACTCGGAAGCGGAGGCCAGTACAGCCCCGGCGGCGACGGTGCCAGCGAAAAAACCCAAACTGACCGACGAACCTAAACTAAAAAGTCCGGTTTTCAAAATCAAAAAAGTCAAACCTATAAACATATGCTCCATCAAGAACAGTCCCGAACGGGAGATGATACTGACTCCTCAAGAACCAAGAGGATCTACCGAGATCTTCATCACGCCTGAAGCCAAATCGGCTCCGACAGCTGATCCGATCAAAGCTAAAGTTGAGTTTTGGAAGCTGTTCAAAGACGACACGGAATGGTGGAAGGCTCTAGCCAAGAGAAACTTGGAGAAGATGGAAGAGTCCCGCCGCGAGCTGCAGAGGTTCAGCGGACACGAGCTCGTTCTCGAAGAGATAAAGATGGAAAGAGACAAATACGAGAAAGAGAAGACACGCCTGCAGACCTTCATCGATGAAGTGGACACCTCGATACAGAAAAAACGGGATCTAGAGTACGACCAAAAATACGAGGAGATGGTCTTAAAATTAATCGAATTTGCGAAAAAGGACTTTATCTACAAGGGCTTTGATCCTTTAATCGAGCGACTGAAAGCTTTGGCGAACGTCCATGTCGAGGGACGCAAACGGAAAGTCGTCAATATAGAAGACATCCTGAACGTATACACGCAAATTGACATCACAAAATACACATACGAGGAATTGTGTCTCTTAGAGAAGTATTATAAGGAAATCATAAGGAAATACACGCAAGAGTACCACGGTAAAGACAGTCTAGAAGCAGGCGACACCCGCATCTACCACAAGAACGTGGTCCTCAACGTGAACACAACGAACAACTTGACCAAAAGCGTCAAGACCAGCGGCGACACTCTGAAGCGGAGTCACAGAAACATGGAGATATTCGACCTGACCAGGACGTACCCTCAAGAGTATTACGCGAACAACTGGTGGTCTATTTATGAAGACATCCTCAAAAACAGGGAAAACCAATTCGGGACTATCGATAACTGGTGGAGTTTCTACGAAGCCATATTGAATAAGGAGAGCACGTCGCAAGAAGATCTGAACAGGCTCCGAGCTGTGGTCCAGTACAGGAATAGTCTGAGGAAGAGACCTCACAGCAGGGCGGAGGAGCAGTTGAGGATGCTGGACGAAATACATAACAATCGGTTTCGGGAGGTCGAAGACGTGCAAGAGAAAAAGGACGAATCGGTGATGGTGACTAATGTGACGTCACTGCTGAAGACCGTCAAGGCTGTTGAAGACGAACACACCCGGGGCACGAGGGCACTGGAGTCCACCATCGAAGCCATATCTCAGGAGATTGAGGTCCTAATGTCACCGTCTCCGCCGAAGTCAACCGCAACTCCGGAAGAGCTGATCCGCTGCACGAGACAGATGACCGTGGCCACGGCCAAAGCTGTGGCCGCTGGGAACGCCAACAAGCAGGACCAGCTGACCGCCGCTGCCAACCTCGGCAGGAAGACCGTCGTGGACCTGTTGATCAGTTGCAAGGCGGCGGCGCAGGCGGCGGAGAGCGCGGAGGTGCGCGAGCGCGGCGTGCGGGCGGGGCTGGCGGCGGCGCAGGCCTACCGCGCGCTGCTGCAGGCCGTGCTGCAGGCCGCCACCGGGGACTCCGCCGCGCGCCAGCAGTTCCCGGAGCTGTCCCGCCGCGTGGCGCACACCGTCGCCGACATCATCGCCACCGCAGAACTGCTCAAAGGTTCGGACTGGGTGGACCCCGACGACCCCACGGTGATAGCCGAGAACGAGCTGCTGGGGGCCGCCGCCTCCATAGACGCGGCCGCCAAGAAGCTGGACTCGCTCCGGCCCAGGAAACCAGTGAAGCAGGAAGCCGATGAGACTCTGAACTTCGACGAAATGATCTTGGAAGCTGCCAAGTCCATTATAGCTGCGACGTCGGCCCTCGTCAGGGCTGCCTCCGCGGCGCAGCGGGAACTCATCGACCAGGGTGCCGTGGCGCGCCGGCCCGCCATGTCGTCGGACGACGGGTCGTGGTCGGGCGGGCTGGTGAGCGCGGCGCGGCTGGTGGCGGCGGCCACGCACTCGCTGGTGGAGGCGGCCAACGCGCTGGTGCAGGGCGCCGCCACCGAGGAGCGCCTCATCTCCAGCGCCAGGCAGGTCGCCTCCTCCACCGCGCACCTCCTCGTCGCCTGCAAGGTGAAGGCGGACCCCGGGGCGGAGAGCACGCGGCGGCTGCAGGCGGCGGGCGCGGAGGTCATCCGCTCCACGGACAACCTGGTGCGCGCCGCCCGGGACGCCATCCACTGCGACGACGAGCGCAGCCTCGTGCTCAACCGCCGCATGGTGGGCGGCATCGCGCAGGAGATCGACGCCAGGTCGGAAGTGCTCCGCATCGAGAAGGAACTGGAGGAGGCCCGCGGCAGGCTGACGGCCATCAGGCAGGCCAAGTACAAGCTGAGGAGCGACGCTGACGACTCCGACGCTGACCCGCAGCCCGGCTACGGCAGCGACTCCTCGGGACCCCAGCGGGTGCGGACTCCTAACAGCAGCTTCGCGAACACCACGTACAGCCCCAACAGCTCGCAGCAGACCACGCTGCACCAGAGCTCGCTGCTGCAGACCACGCACAGCTCCGGACTCAACTCCACTTCCTACGGACAGCAGAACAGCAGCAGCCCCGCCCCCCCGCAGCCCACCAGCCCGACGTTCTCCAGCTTCCGTCCGGCGCCGGACGCGCCCAAGCAGAACTACGAAGCCTTCACGACACGCTACGAAACTCGAATGTACGACACGCCGCGACCGGTAGCCGAGCACTCCACCACCGAGCGACAGGAGACCAGCCAGTACAGATACAAGCAGGAGAAGTTGGACTACGAAGCGCCCAGGACGCCCCTGAGCCCTAAGTTCAACGCCAGAGAGCTTAAATTCGACGAGCACCCCGAGCCGATATACTCCACCCTGAAGAAACCCTCCGACGGTTTGGGACAGACGTTCTCGGAGCACCAGAGGTCCACGGAGTCCATCCCCGGAGGCACCAAGCATTCAGAATACACAATCAAAAGTGAATCTTACCAGTCGTTCCCGAAGACGGAGTTTTCCAAAACGGAATTTAAGCAGGAAGTGAAATCTCCATTCACATCCACTCCGAAGTTTGATCGCACAAGCTACGTGACCACCTCCAGTGACCTGGTGAAGGCCGCCACGCCGGACTACGAGCGCATGGCTTCGCCCTACGCCAAGGAGGGCGACAGCTACGGAGGTCCCAATTACATGGAGGAAACCACCACGGAGGTCAAAGAAATACCCAACGGCACCCAGAAGATCACTACAACGAAGATATACAGCTCGTCGCCCGTCAACCTGACCTCCACCAGCACCAAGTACGAGCCGATCAAACTGGACGGAATCGACGAAATCTCGAAGACCTTCGACAGCGACTCCCGGTACAGCACCCTGGACTCGAGGTTCAACACGCTAGAGTCCAAGCTCAGTTCGGACACGAGCCGCTCCTTCATGAGGCCGTCGGAGTTCCAGTCGTCAGACTACCAGACCACCAGCAACGTGACGAAGATCAAGAAGCCGGATCTGTCGAAGGAGATCGACAGCCTGGACAAGAGGATCTCAAAGCAAACGATCACCTCGGAGACTATCGAAAGGAAGTCCGTAATGACCAGCTCTCACAAATCGGAGACCAGCTCCACCGTCACCAAGAAATTCGGGAACTTCTAG
Protein
MASAVKRADQDQFPRSVGSVASAVHGLVEAAAQAAYLVAVSEESSVAGRAGLVDQAQFGRAALAIQQACNLLADPASNQQQVLSAATVIAKHTSALCNACRVASGKTTEPQAKRHFVQAAKDVANSTAALVKEIKALDTDYSEANRARCASATGPLLEAVQSLCQFADSPEFASIPARISEQGRRSQEDILECGRNIISESCSMLEAAGQLVLSPEDRPQWHALAAHSKTLSDTIKALVANIREKAPGQRECAAALDTLNKQLRELDHAAIQAVAQELEPRKANTLQGYAEQIENCCTEMLERLEPLRVAARAEAENLGHCVRQYVSYSEPLVSGAVGAASGVSETTEQAALLQHARTVLETAVLLLQAARDAAGNPRAAAAHGAVDAQVVQARESLQELAERVRRLSAQHGAVGPLLDTLARALTRLTERRMSLLSSYDESDSFVDYQTRMVGVAKEIARLATDMTAKAATEPGRLVELGNEMCGKYEQLAQDSVGASATTPSGDVANRIRSAVVELGESISELIKAGGHCRLSAIAQNQRAVADSAKLVNERVVSVLSGLQAGSRGTQACIHAAATISAIIGDLDTTILFASAGTLQSDKESDTFSDHRENILKTAKALVEDTKTLVGGAAGTQEQLADAAQNAVTTIVQLCEVVKLGAMSLGSGSPEPQVLVLHAARDVAAALRDLAAATTAASGKPGLGADMQRLKHAAKRPPAPRRRCSAPGNSNTFPGQKRRSLNGRNDYNSCDSETDLFQSDQEEELVKLLDYSSQDDDVSPTIFHDDCEEIVAYIESRMRRPTRTPEDEGLNERYNAAARYSIVDMDWRVLKYGENILLGEVKKLLDLCLQLSDRNDSRRKDESLQRLRASTQLDTEMHTLSRVIEHLDSEAEASTAPAATVPAKKPKLTDEPKLKSPVFKIKKVKPINICSIKNSPEREMILTPQEPRGSTEIFITPEAKSAPTADPIKAKVEFWKLFKDDTEWWKALAKRNLEKMEESRRELQRFSGHELVLEEIKMERDKYEKEKTRLQTFIDEVDTSIQKKRDLEYDQKYEEMVLKLIEFAKKDFIYKGFDPLIERLKALANVHVEGRKRKVVNIEDILNVYTQIDITKYTYEELCLLEKYYKEIIRKYTQEYHGKDSLEAGDTRIYHKNVVLNVNTTNNLTKSVKTSGDTLKRSHRNMEIFDLTRTYPQEYYANNWWSIYEDILKNRENQFGTIDNWWSFYEAILNKESTSQEDLNRLRAVVQYRNSLRKRPHSRAEEQLRMLDEIHNNRFREVEDVQEKKDESVMVTNVTSLLKTVKAVEDEHTRGTRALESTIEAISQEIEVLMSPSPPKSTATPEELIRCTRQMTVATAKAVAAGNANKQDQLTAAANLGRKTVVDLLISCKAAAQAAESAEVRERGVRAGLAAAQAYRALLQAVLQAATGDSAARQQFPELSRRVAHTVADIIATAELLKGSDWVDPDDPTVIAENELLGAAASIDAAAKKLDSLRPRKPVKQEADETLNFDEMILEAAKSIIAATSALVRAASAAQRELIDQGAVARRPAMSSDDGSWSGGLVSAARLVAAATHSLVEAANALVQGAATEERLISSARQVASSTAHLLVACKVKADPGAESTRRLQAAGAEVIRSTDNLVRAARDAIHCDDERSLVLNRRMVGGIAQEIDARSEVLRIEKELEEARGRLTAIRQAKYKLRSDADDSDADPQPGYGSDSSGPQRVRTPNSSFANTTYSPNSSQQTTLHQSSLLQTTHSSGLNSTSYGQQNSSSPAPPQPTSPTFSSFRPAPDAPKQNYEAFTTRYETRMYDTPRPVAEHSTTERQETSQYRYKQEKLDYEAPRTPLSPKFNARELKFDEHPEPIYSTLKKPSDGLGQTFSEHQRSTESIPGGTKHSEYTIKSESYQSFPKTEFSKTEFKQEVKSPFTSTPKFDRTSYVTTSSDLVKAATPDYERMASPYAKEGDSYGGPNYMEETTTEVKEIPNGTQKITTTKIYSSSPVNLTSTSTKYEPIKLDGIDEISKTFDSDSRYSTLDSRFNTLESKLSSDTSRSFMRPSEFQSSDYQTTSNVTKIKKPDLSKEIDSLDKRISKQTITSETIERKSVMTSSHKSETSSTVTKKFGNF
Summary
Uniprot
EMBL
Proteomes
PRIDE
Pfam
Interpro
IPR015009
Vinculin-bd_dom
+ More
IPR035964 I/LWEQ_dom_sf
IPR036723 Alpha-catenin/vinculin-like_sf
IPR030224 Sla2_fam
IPR002558 ILWEQ_dom
IPR000299 FERM_domain
IPR015224 Talin_cent
IPR019748 FERM_central
IPR011993 PH-like_dom_sf
IPR036476 Talin_cent_sf
IPR018979 FERM_N
IPR037438 Talin1/2-RS
IPR035963 FERM_2
IPR019749 Band_41_domain
IPR032425 FERM_f0
IPR014352 FERM/acyl-CoA-bd_prot_sf
IPR035964 I/LWEQ_dom_sf
IPR036723 Alpha-catenin/vinculin-like_sf
IPR030224 Sla2_fam
IPR002558 ILWEQ_dom
IPR000299 FERM_domain
IPR015224 Talin_cent
IPR019748 FERM_central
IPR011993 PH-like_dom_sf
IPR036476 Talin_cent_sf
IPR018979 FERM_N
IPR037438 Talin1/2-RS
IPR035963 FERM_2
IPR019749 Band_41_domain
IPR032425 FERM_f0
IPR014352 FERM/acyl-CoA-bd_prot_sf
Gene 3D
ProteinModelPortal
PDB
5IC1
E-value=1.65296e-79,
Score=760
Ontologies
GO
PANTHER
Topology
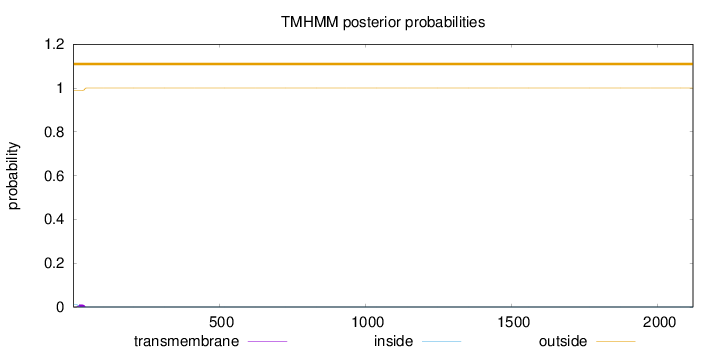
Length:
2120
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.2431
Exp number, first 60 AAs:
0.24212
Total prob of N-in:
0.01135
outside
1 - 2120
Population Genetic Test Statistics
Pi
356.024925
Theta
189.075366
Tajima's D
2.612598
CLR
0.158026
CSRT
0.952452377381131
Interpretation
Uncertain
