Gene
KWMTBOMO00574 Validated by peptides from experiments
Pre Gene Modal
BGIBMGA012240
Annotation
PREDICTED:_basement_membrane-specific_heparan_sulfate_proteoglycan_core_protein-like_isoform_X4_[Bombyx_mori]
Location in the cell
Extracellular Reliability : 2.36
Sequence
CDS
ATGTGTAATCCAAAGACAGGGGTCTGTTACGACTGCAAGGATAACACGGATGGTCCCCAGTGCGAACTCTGCAAGCCTGGATACGACAGAGACGGCTACGGCAACTGCGTTGAATCCGATAACTTCATCAGCACCCAGCAACCTTGCAGATGCAATCCTGACGGCGTCGAAGTACCATGTGACGAGACTGGTACCTGTTCTTGCAAGCAGAACGTCGAAGGCGATTACTGTGACACCTGCAGACCTGGAACCTACGGGCTGGATCGAAACAACCCTCAGGGATGTCTCTCGTGTTATTGTTCCGGCGTCACCAGCGAATGTCACGAGGGCGTCCACTACAGTAGAATACCGATGGCCGCACCAGTTTTCGGCGAAAACAACGGCGGCTACAGCCTCACCGACTTAAACGCAGAAAAAATATACAACGAACATTTCGTACCAGTTCCCGATAAAAGCGAGCTCATGTACATATTCTCGTACCCACCCGAAAACGAACTGTATTGGTCGTTGCCCATCTTCCCTGGTAACAGAGTACTGTCATACGGTGGTTCGCTGTCGATAAGACAAGAGTTCCGAAGCAACAACGACGATGCGGTCTCACAGAGTGGCGTCGACGTTGTTCTTGTCGGCAAAGACGCTTCGGTGTACTGGTCCAACCCGACTCCGATCCGATCCGGCGTGCCTCTTAATTACCAGGTGATTTTGAGCGAAGACAACTGGTTCCTATTGAACACGGCCACGCCGGTCACTCGAAACACCTTCATGAATGTCCTGAAGGACCTGAAGCGAGTGCTTGTTCGTGCTACTCTCGATCCCAACGTACTGTCGACATCTATCGCTGACGTGTCCATGGACACTGCCACTATCATGTACGAACAAGATTTGCCTGTTGCAAAGGGAGTCGAAATCTGCATGTGTCCAGCCGGATACACTGGCACCAGCTGCGAGAGTTGCTCGTCTGGTTACTACAAGGACGTGTCTGGTCGGTGCCAACAGTGCTCATGTAACGGCCACGACTGTCAACTCGACGCTTACGGACAGACTATATGTAACTGCCGCCCCCCTTACACCGGCTCTGATTGTTCTACCATCGCCGGTGAGCCCTCGGTGACTACACCGCCTAATCAACCGCCGCCCGAAGTAACGGTGTTCGTGAGAATCATTGAGCCCTCGAACATAAGGGACCTGCACGTCGGTAGCAGTGTCAACTACACTTGCCAGGCTCAGAGTCGCATTACGAACAGACTCCGCATCGCGTGGTCCAAGGCTGATGGCTACTTGCCTCAAGGAAGGTCGCAGGTCGACGAAAACAGTGGTGTCTTGCTCCTCACTAACCTTCAGACATCCGATAGCGGCCAGTACATCTGTCAGACAAGCGACGGATACTCAACGGCTCAAGATGTCGTCACTCTTATAGTGCCCGGTAATGATATGACCCCGCCCACGGTATCGATTCGTCCCATCACAACTGACTACTATGAAGGTGATAGGATCGAACTAGAATGCACGGCAACAGGAAACCCAGCTCCTTCTATCTCATGGCAGAGGAACTCTAGAAGACCTTTGCCGGCGTCCGCTGAATCGTTCGATGACCTCTTGATAATTGAAAGTGCACGCCAAGAGGACTCTGGAGAATACAGGTGTATCGCTTCGAACGCAGTCAGTACAGAAGTTACTAAAGTCACGATCAATGTACGTGCAAAACCATCTTGGCCATCTCAGGAGAAGCTAACAGTGTCTCCGACATCTCTCTCAATTGACGAGGGCCAAAGTTCTAGGGCTGTCTGTACTGGCACACAAGGCGTTCCGGCCGGCTCCATTGAGTGGATCAGGCAAGACAATGCTCCGTTCGTGGCAAACGTGCGGTCCGATAACGGGGTATTGTACATCGAATACGCTCGACCCGAGAACGATGGCATCTATGTCTGCCAGAGCTCATCGTCGAATGTCTCGCCGCAATCGATTATCATAACAATCATACCGACATACAGTCCTGACCCCGCCAAAGAGTCGAACATCAGCATTTCGGTCGACAGCTTGAAGGTACCGGCTGGTGGAAGCGGAAAGATCGACTGTAATCCTGACGGAACAATTCTACCTACCATCAAATGGAGCAAGCACGGCGGAGAATTCGGAAGCGAAACAAGCCAACGCGGCAACACTCTCATAATCAACAACGCCAAAGAGGACGATCAAGGATACTATCTGTGCGAGGGAATCGTTAACGGCGCCACCATAGCCAGCTCATACGTCTACGTCGAGATCGAAAGACGTGACCCTCCGCAAGTGGACATCTGGCCCCAAGGCGAGAGAGCAGTCACTCTGGGCACAGAATACGAACTCATCTGCAGAGTTCTTGGTGGAGTCCCTGAGCCTGACGTCATGTGGAGTCGAGGTGGAAGTAGACCGCTGTCCTCGTACGTCCACATCCGTCCGCAAAATACGCTCAAGTTTGACCACGTCGACGTGAACGACGAAGGCGAATACTTCTGCACGGCTACGAACGTGGCCGGTACAGCCACGGCTCGTTCCGTCATCAAAGTGAGATCGCCGCCGGTCATCACCATCACGCCGGCGAGCTTCCTAGAGGCACCTCTCGGTAGTTCCGTGACAGTCGAATGCAGAGCCGACGGGTATCCCCTACCAATGGTGTCCATAAAGACAAGCGCTGATCTCCGCGAGCTGGTGCGGCCCACACCCAGCTTAGCAGCATTGAAGATACCGTCGATAGCTGAGCGCGACGACGGCGACTACATTTGCACGGCCACTTCTGCGGCCGGCACCATCGAGGAGCCGTTCGCGATACGCGTCAGCCGCGGAGACATTGGAGTCGAATACGAATTTGGTGGAAGCGGCGATGACGAGTTCCCCGTTGACTACAACCCGAACAACCCGACCGGGAGATCAGACACGTTGATCGCTTATGAAAACGAACCAGAAATAACCATCTTCTGCAACAGCTCCGAGGGCTTCAACGCACGCTGGGACCGAGGAGACAGACAGTCACTGCAAAGAAATGCGTACCAAGTTGATTCACGTTTGATCATCCGTGGTGTATCCAAGAGCGACTCCGGCTTGTACGTTTGTAGTTTGTACAACCGCTACACCGGAGAGGTGGTGAAGGCGAACTACACTAATCTCCAAGTCGTGACCCGACCTAAGATAACGTTGAGGCCGGCCAACCAAACGGTCCGACCTGGTCAGTCGCTCACGGTCGAGTGTCTCGTCGAAGGAGATGAAATTCTAGACGTCACTTGGAGATACGACAGGGAGCCTTCTAGACGTGTCGAAATCCGTGGCCCAGTTCTGGTCTTTAACAACATCGAAGTGGAAGATGCCGGCATATACTATTGCATAGCTCGCAGCCGTTACGGAAACGACACCGCCACCGCCAATGTCATCGTAACCGGAGCACGCGACGCAAATTCTGCTTCGCTGGTGTACATCGATCAGCCACGCAGAAAGTTCAGGGTTTCGGAGAACGTCGAAGTTATCTGTAAGGGAAGATCTCGAGATGTCACCTTTAAGTGGGAGCGTCCCGACACCAACTTGTACCTGGTTACTAATCCGTTCGGAGGCGGTTCTCGGCTGCTGATAAACAGCGTCCAAGAGTCCGACGCCGGCGTATATCGCTGCATCGGTACAGATCCATTCGGCATCTCCTCGTACGACGATTTCGTTTTGGAGATCGAACCAGGTTCTGGCAACGCCGTCTATCCCGGCAACAGAGACCTGCCCGTCACCCATTACTCAGCTCGGCTTCGCGAGGCCGTCGACATGCCCTGCAACCACGACCTAAACGAGCCAGTCATTATCGAATGGAAACGAGAATATTCGCCGCTTCCCGCTGAAGTTCGAAGCAATCAGCCAATCCTACACTTGGAAAGCGTGACAGAAGCGGATGCCGGCATCTACGTCTGCCGCGTCAGCAACCAAGAAGTAACAGTTACAGCGAAGGCGATCCTTAGGGTGATCGGTGTGGTTCCACTCTTCAAAGGCAAGAGTTGGTTATCACTTCCACCTCTGAAAGACGCCTACAGACAATTCGACATTGAAGTCTACTTCAAACCCACCGATCTGAACGGCCTGATCCTGTACAACAGCCAAAATCAGGGTAGAACCGGTGACTACATCGGTCTAAGGTTATTGGATGGAGTACCAGAGTTCATATTCGACGCTGGTGCCGAACCTGTCATCGTCAAAGGCGATAGACCATTGCAATTGAACGTCTGGCATTCAATAAGAGTCAGCAGGACCGATTCGAAGGTGACAATGGACGTCGACGATACAGGACCGTTCATAACTGATTCGGAAGAGCCTTGGTCGGCCGTGCTGGAACTCAACCAGCCAATGTACATTGGAGGAGTTCCTGATATTGACCAACTACCAGCTGGACTTGCAGGATCCGATGGGTTCATCGGATGCGTGAGCACTCTGATCCTCGGCCACGATGAGAAGAATATCATGCTCGACAGCTTGGAACAATACGGCGTCGACGAATGTCGGTCTTGCACTCCCAACCTTTGCGTCAATGACGGAATCTGTCAGGAGGCGCGTAATGAACGCGGCTACATGTGCATCTGCGCTCCTGGCTTCGCCGGCTGGAATTGCGAGAGAACCGGGGAAGCTTGCAGAGCCGGCCTATGTGGACCTGGGAAATGCACCGAAACAGTGGACGGTTACAGGTGTGCTTGTCCCATGTCTCACACAGGCAAGAACTGCGAGACGAAGCAACTGATCGCGTACCCAGCTTTCACGGGGAGCGCATTCCTAGCTATCAACGCCCCGCCGCCGTCCCGTTCCATGAAGATGTCGCTAAAGATCAGGGCAGCCACTCCAGTGACAGACGGCATCATCATGTACTGCGCCGAGTCGTCGCGAGGATACGGCGGCTTCACCTCACTGACCGTTCGAAATGGAAGACTTGAGTTCCGTTACGACCTTGGATCCGGAAGCACTCCCGTGGTGCTTACAAGTGACAGGCCATTGCCCGCGAACCAATGGATCGACATTCAGATCGCCCGCCTCGCGGATTCCGTCTCCATGAAGATCAACTTAGTACGCAGCTTCGAGAGACGTTTGGATAGACCGGCTGAAAGCCTCCGGTTCGAGACTCCGATGTTCGTGGGCGGAGTCGACGATTCCACCGTGGTAGTGAACCCTAACGCCGGCGTCAGCGGCGGCTTCAGCGGATGCATTAAGGATGTCGTGTTGAATAGCAACGCCGTCGACATAAACTCATCGATTAAGTCGTCGAACATTCAAGAGTGCAACACGTACGACCGCGGCGATATTCAGGCGTCGGAGTCCTGCCAATGCGAAAACGGAGGTTCCTGTTCGACTGAATCCACCAATTGCATATGCCCACCCGGCTATACGGGATCGTACTGCGAGACGCGCATCGCATCCTACCTGATGTCGCCACCTCCGCCGGTAAACCCTTGCTCTCTGCACCCGTGTCGCAACGGAGGAACCTGCAAACCAGATCGCAACTCTTGGATGAACCACACCTGCGACTGCCCCTTGGGTTATGCCGGAGCCTCGTGTCAGATGCCTCTCGAATTAGGCCAGAGCGTGGGCTTCAACGGCAACGGGTATGTAGAGTTGCCGGCCAGTTTGCTTCGCTATGATGAACTGGCCTCGAACCCCGCTGTCATCGCCCTCGCTGTGCACACCACAAACGACGGAGTACTGGCCTACCAGAGGGAAGGACAAGCTCCGCCTAACGAAGGCGATTACTTCTTATTGAGAATTGAAAGAGGTTTCGTCGTACTCGAATGGGACTTGGGCGGTGGTCTTTCTTCCATAGTTGTCGATGTTCCTATTAACGACGGCGAGAGGCACCAGGTCGCCGCTCGTCTGCACGAGGACGGACACGCCTGGCTCTCCGTCGACGGAGTTGACAAGAGCGCGCCGGCCACCGGTATCTCCAACGTCATGAACGCTGACTCCAACATATACATCGGTGGAATACCAAGCTGGTTGAACATCCACGGATATCCAGGCTTCATCGGTTGCATTGAGAATGTTGAGACAACGGACAGCCACCGAGGATTGAATTTGCGAGACACCGCTGTGGCTGGTCGAAACACGCAGCTATGCAGAGACTCCTGA
Protein
MCNPKTGVCYDCKDNTDGPQCELCKPGYDRDGYGNCVESDNFISTQQPCRCNPDGVEVPCDETGTCSCKQNVEGDYCDTCRPGTYGLDRNNPQGCLSCYCSGVTSECHEGVHYSRIPMAAPVFGENNGGYSLTDLNAEKIYNEHFVPVPDKSELMYIFSYPPENELYWSLPIFPGNRVLSYGGSLSIRQEFRSNNDDAVSQSGVDVVLVGKDASVYWSNPTPIRSGVPLNYQVILSEDNWFLLNTATPVTRNTFMNVLKDLKRVLVRATLDPNVLSTSIADVSMDTATIMYEQDLPVAKGVEICMCPAGYTGTSCESCSSGYYKDVSGRCQQCSCNGHDCQLDAYGQTICNCRPPYTGSDCSTIAGEPSVTTPPNQPPPEVTVFVRIIEPSNIRDLHVGSSVNYTCQAQSRITNRLRIAWSKADGYLPQGRSQVDENSGVLLLTNLQTSDSGQYICQTSDGYSTAQDVVTLIVPGNDMTPPTVSIRPITTDYYEGDRIELECTATGNPAPSISWQRNSRRPLPASAESFDDLLIIESARQEDSGEYRCIASNAVSTEVTKVTINVRAKPSWPSQEKLTVSPTSLSIDEGQSSRAVCTGTQGVPAGSIEWIRQDNAPFVANVRSDNGVLYIEYARPENDGIYVCQSSSSNVSPQSIIITIIPTYSPDPAKESNISISVDSLKVPAGGSGKIDCNPDGTILPTIKWSKHGGEFGSETSQRGNTLIINNAKEDDQGYYLCEGIVNGATIASSYVYVEIERRDPPQVDIWPQGERAVTLGTEYELICRVLGGVPEPDVMWSRGGSRPLSSYVHIRPQNTLKFDHVDVNDEGEYFCTATNVAGTATARSVIKVRSPPVITITPASFLEAPLGSSVTVECRADGYPLPMVSIKTSADLRELVRPTPSLAALKIPSIAERDDGDYICTATSAAGTIEEPFAIRVSRGDIGVEYEFGGSGDDEFPVDYNPNNPTGRSDTLIAYENEPEITIFCNSSEGFNARWDRGDRQSLQRNAYQVDSRLIIRGVSKSDSGLYVCSLYNRYTGEVVKANYTNLQVVTRPKITLRPANQTVRPGQSLTVECLVEGDEILDVTWRYDREPSRRVEIRGPVLVFNNIEVEDAGIYYCIARSRYGNDTATANVIVTGARDANSASLVYIDQPRRKFRVSENVEVICKGRSRDVTFKWERPDTNLYLVTNPFGGGSRLLINSVQESDAGVYRCIGTDPFGISSYDDFVLEIEPGSGNAVYPGNRDLPVTHYSARLREAVDMPCNHDLNEPVIIEWKREYSPLPAEVRSNQPILHLESVTEADAGIYVCRVSNQEVTVTAKAILRVIGVVPLFKGKSWLSLPPLKDAYRQFDIEVYFKPTDLNGLILYNSQNQGRTGDYIGLRLLDGVPEFIFDAGAEPVIVKGDRPLQLNVWHSIRVSRTDSKVTMDVDDTGPFITDSEEPWSAVLELNQPMYIGGVPDIDQLPAGLAGSDGFIGCVSTLILGHDEKNIMLDSLEQYGVDECRSCTPNLCVNDGICQEARNERGYMCICAPGFAGWNCERTGEACRAGLCGPGKCTETVDGYRCACPMSHTGKNCETKQLIAYPAFTGSAFLAINAPPPSRSMKMSLKIRAATPVTDGIIMYCAESSRGYGGFTSLTVRNGRLEFRYDLGSGSTPVVLTSDRPLPANQWIDIQIARLADSVSMKINLVRSFERRLDRPAESLRFETPMFVGGVDDSTVVVNPNAGVSGGFSGCIKDVVLNSNAVDINSSIKSSNIQECNTYDRGDIQASESCQCENGGSCSTESTNCICPPGYTGSYCETRIASYLMSPPPPVNPCSLHPCRNGGTCKPDRNSWMNHTCDCPLGYAGASCQMPLELGQSVGFNGNGYVELPASLLRYDELASNPAVIALAVHTTNDGVLAYQREGQAPPNEGDYFLLRIERGFVVLEWDLGGGLSSIVVDVPINDGERHQVAARLHEDGHAWLSVDGVDKSAPATGISNVMNADSNIYIGGIPSWLNIHGYPGFIGCIENVETTDSHRGLNLRDTAVAGRNTQLCRDS
Summary
Uniprot
A0A2A4JY62
A0A1E1WPB5
H9JRT0
A0A2W1BNS5
A0A2A4JZY4
A0A2H1W0A8
+ More
A0A194R369 A0A194PH43 A0A212EQD1 A0A0P5IXJ5 A0A2P8ZL17 A0A0N8B666 A0A2A3EF83 A0A232FKH0 A0A1W4UVG1 A0A1W4UVI6 A0A1W4V891 A0A1W4V8B1 A0A1W4V959 A0A1W4UVV1 A0A1W4UVG7 A0A1W4UVI1 A0A1W4V896 A0A1W4UVW5 A0A1W4V969 A0A1W4V7U3 A0A1W4V964 A0A1W4UVW0 A0A1W4V7T2 A0A1W4UVW9 V5GTF6 A0A1W4V7T8 A0A1W4V974 A0A1W4UVH6 A0A1W4V8A1 A0A1W4UVH1 A0A1W4UVV5 A0A1W4V7S7 A0A067RIT1 V5I8B9 A0A2D3E2X4 V5HEE5 A0A131XXY6 V5GZ45 A0A1Y1MVH2 A0A1Y1N276 E2BPV9 A0A1B6CKY8 A0A023GG07 A0A195E4L2 A0A1B6CLV9 A0A131XPK7 A0A2S2Q1P7
A0A194R369 A0A194PH43 A0A212EQD1 A0A0P5IXJ5 A0A2P8ZL17 A0A0N8B666 A0A2A3EF83 A0A232FKH0 A0A1W4UVG1 A0A1W4UVI6 A0A1W4V891 A0A1W4V8B1 A0A1W4V959 A0A1W4UVV1 A0A1W4UVG7 A0A1W4UVI1 A0A1W4V896 A0A1W4UVW5 A0A1W4V969 A0A1W4V7U3 A0A1W4V964 A0A1W4UVW0 A0A1W4V7T2 A0A1W4UVW9 V5GTF6 A0A1W4V7T8 A0A1W4V974 A0A1W4UVH6 A0A1W4V8A1 A0A1W4UVH1 A0A1W4UVV5 A0A1W4V7S7 A0A067RIT1 V5I8B9 A0A2D3E2X4 V5HEE5 A0A131XXY6 V5GZ45 A0A1Y1MVH2 A0A1Y1N276 E2BPV9 A0A1B6CKY8 A0A023GG07 A0A195E4L2 A0A1B6CLV9 A0A131XPK7 A0A2S2Q1P7
Pubmed
EMBL
NWSH01000364
PCG76955.1
GDQN01002199
JAT88855.1
BABH01017200
BABH01017201
+ More
BABH01017202 BABH01017203 BABH01017204 KZ149976 PZC75931.1 PCG76962.1 ODYU01005265 SOQ45944.1 KQ460953 KPJ10291.1 KQ459605 KPI92029.1 AGBW02013270 OWR43696.1 GDIQ01207629 JAK44096.1 PYGN01000026 PSN57195.1 GDIQ01208931 JAK42794.1 KZ288266 PBC30144.1 NNAY01000102 OXU30958.1 GALX01004953 JAB63513.1 KK852445 KDR23766.1 GALX01004956 GALX01004955 JAB63511.1 MF062034 ATU31752.1 GANP01008574 JAB75894.1 GEFM01004668 JAP71128.1 GANP01008573 JAB75895.1 GEZM01019391 JAV89671.1 GEZM01019395 JAV89667.1 GL449658 EFN82310.1 GEDC01023161 JAS14137.1 GBBM01003500 JAC31918.1 KQ979685 KYN19842.1 GEDC01022839 JAS14459.1 GEFH01001080 JAP67501.1 GGMS01002398 MBY71601.1
BABH01017202 BABH01017203 BABH01017204 KZ149976 PZC75931.1 PCG76962.1 ODYU01005265 SOQ45944.1 KQ460953 KPJ10291.1 KQ459605 KPI92029.1 AGBW02013270 OWR43696.1 GDIQ01207629 JAK44096.1 PYGN01000026 PSN57195.1 GDIQ01208931 JAK42794.1 KZ288266 PBC30144.1 NNAY01000102 OXU30958.1 GALX01004953 JAB63513.1 KK852445 KDR23766.1 GALX01004956 GALX01004955 JAB63511.1 MF062034 ATU31752.1 GANP01008574 JAB75894.1 GEFM01004668 JAP71128.1 GANP01008573 JAB75895.1 GEZM01019391 JAV89671.1 GEZM01019395 JAV89667.1 GL449658 EFN82310.1 GEDC01023161 JAS14137.1 GBBM01003500 JAC31918.1 KQ979685 KYN19842.1 GEDC01022839 JAS14459.1 GEFH01001080 JAP67501.1 GGMS01002398 MBY71601.1
Proteomes
PRIDE
Pfam
Interpro
IPR023415
LDLR_class-A_CS
+ More
IPR036179 Ig-like_dom_sf
IPR000742 EGF-like_dom
IPR001791 Laminin_G
IPR013032 EGF-like_CS
IPR003598 Ig_sub2
IPR002049 Laminin_EGF
IPR013783 Ig-like_fold
IPR000034 Laminin_IV
IPR009030 Growth_fac_rcpt_cys_sf
IPR007110 Ig-like_dom
IPR003599 Ig_sub
IPR013320 ConA-like_dom_sf
IPR002172 LDrepeatLR_classA_rpt
IPR013098 Ig_I-set
IPR036055 LDL_receptor-like_sf
IPR001881 EGF-like_Ca-bd_dom
IPR000152 EGF-type_Asp/Asn_hydroxyl_site
IPR013151 Immunoglobulin
IPR000082 SEA_dom
IPR013106 Ig_V-set
IPR036179 Ig-like_dom_sf
IPR000742 EGF-like_dom
IPR001791 Laminin_G
IPR013032 EGF-like_CS
IPR003598 Ig_sub2
IPR002049 Laminin_EGF
IPR013783 Ig-like_fold
IPR000034 Laminin_IV
IPR009030 Growth_fac_rcpt_cys_sf
IPR007110 Ig-like_dom
IPR003599 Ig_sub
IPR013320 ConA-like_dom_sf
IPR002172 LDrepeatLR_classA_rpt
IPR013098 Ig_I-set
IPR036055 LDL_receptor-like_sf
IPR001881 EGF-like_Ca-bd_dom
IPR000152 EGF-type_Asp/Asn_hydroxyl_site
IPR013151 Immunoglobulin
IPR000082 SEA_dom
IPR013106 Ig_V-set
Gene 3D
CDD
ProteinModelPortal
A0A2A4JY62
A0A1E1WPB5
H9JRT0
A0A2W1BNS5
A0A2A4JZY4
A0A2H1W0A8
+ More
A0A194R369 A0A194PH43 A0A212EQD1 A0A0P5IXJ5 A0A2P8ZL17 A0A0N8B666 A0A2A3EF83 A0A232FKH0 A0A1W4UVG1 A0A1W4UVI6 A0A1W4V891 A0A1W4V8B1 A0A1W4V959 A0A1W4UVV1 A0A1W4UVG7 A0A1W4UVI1 A0A1W4V896 A0A1W4UVW5 A0A1W4V969 A0A1W4V7U3 A0A1W4V964 A0A1W4UVW0 A0A1W4V7T2 A0A1W4UVW9 V5GTF6 A0A1W4V7T8 A0A1W4V974 A0A1W4UVH6 A0A1W4V8A1 A0A1W4UVH1 A0A1W4UVV5 A0A1W4V7S7 A0A067RIT1 V5I8B9 A0A2D3E2X4 V5HEE5 A0A131XXY6 V5GZ45 A0A1Y1MVH2 A0A1Y1N276 E2BPV9 A0A1B6CKY8 A0A023GG07 A0A195E4L2 A0A1B6CLV9 A0A131XPK7 A0A2S2Q1P7
A0A194R369 A0A194PH43 A0A212EQD1 A0A0P5IXJ5 A0A2P8ZL17 A0A0N8B666 A0A2A3EF83 A0A232FKH0 A0A1W4UVG1 A0A1W4UVI6 A0A1W4V891 A0A1W4V8B1 A0A1W4V959 A0A1W4UVV1 A0A1W4UVG7 A0A1W4UVI1 A0A1W4V896 A0A1W4UVW5 A0A1W4V969 A0A1W4V7U3 A0A1W4V964 A0A1W4UVW0 A0A1W4V7T2 A0A1W4UVW9 V5GTF6 A0A1W4V7T8 A0A1W4V974 A0A1W4UVH6 A0A1W4V8A1 A0A1W4UVH1 A0A1W4UVV5 A0A1W4V7S7 A0A067RIT1 V5I8B9 A0A2D3E2X4 V5HEE5 A0A131XXY6 V5GZ45 A0A1Y1MVH2 A0A1Y1N276 E2BPV9 A0A1B6CKY8 A0A023GG07 A0A195E4L2 A0A1B6CLV9 A0A131XPK7 A0A2S2Q1P7
PDB
6IAA
E-value=1.73574e-23,
Score=277
Ontologies
GO
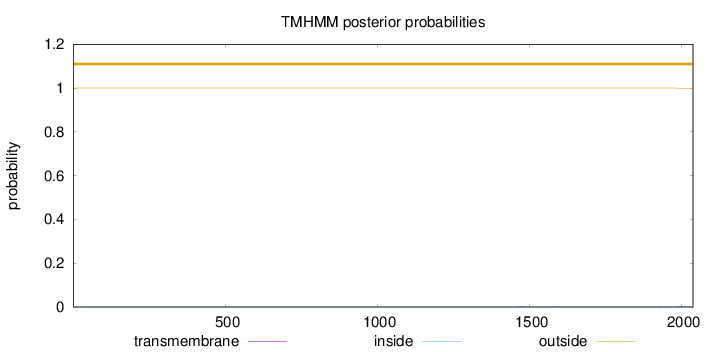
Topology
Length:
2037
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.03858
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00007
outside
1 - 2037
Population Genetic Test Statistics
Pi
20.223189
Theta
20.158464
Tajima's D
0.3046
CLR
0.085517
CSRT
0.466176691165442
Interpretation
Uncertain
